Baixar para ler offline
















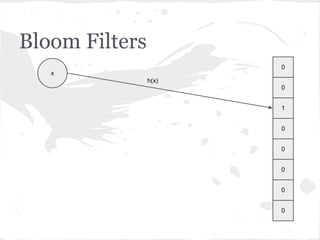
![Bloom Filters
adicionar!(item):
V[hash(item)] ← 1
contém?(item):
retorne V[hash(item)] = 1](https://image.slidesharecdn.com/encontrodnarj-120630205339-phpapp01/85/dnarj-20120630-19-320.jpg)

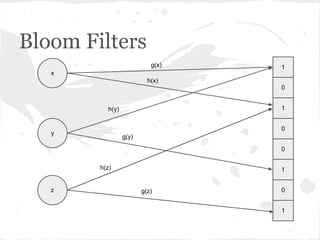
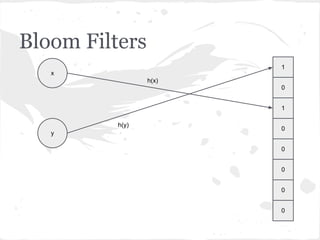
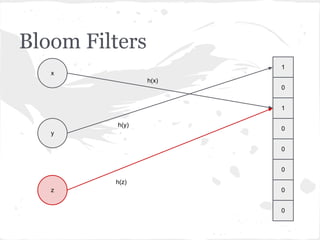
![Bloom Filters
adicionar!(item):
para cada hash em hashes:
V[hash(item)] ← 1
contém?(item):
para cada hash em hashes:
se V[hash(item)] = 0:
retorne falso
retorne verdadeiro](https://image.slidesharecdn.com/encontrodnarj-120630205339-phpapp01/85/dnarj-20120630-22-320.jpg)











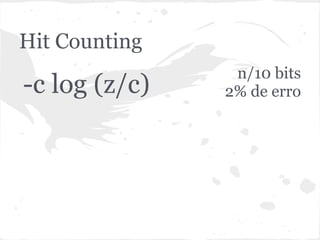

![Hit Counting
adicionar!(item):
V[hash(item)] ← 1
quantos?:
z ← número de zeros em V
c ← tamanho de V
retorne -c × log(z/c)](https://image.slidesharecdn.com/encontrodnarj-120630205339-phpapp01/85/dnarj-20120630-36-320.jpg)






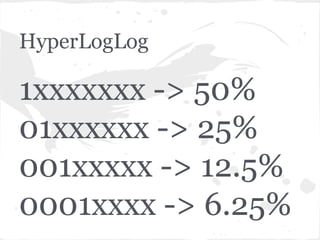

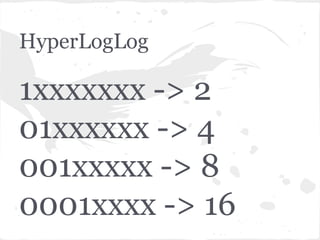


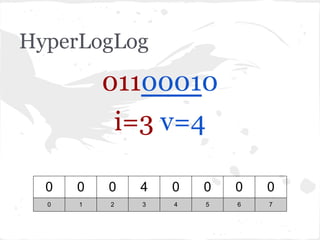



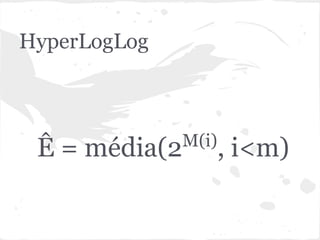
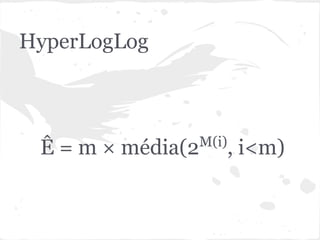
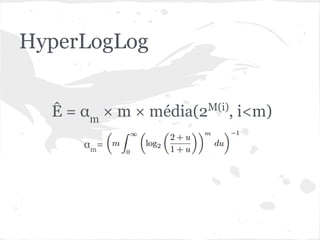
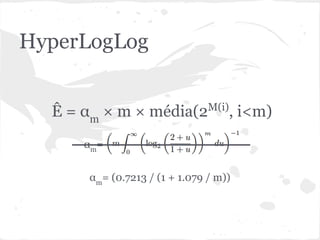






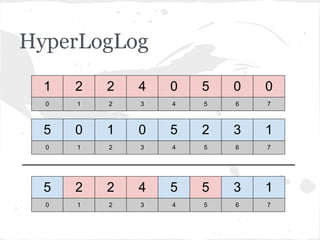


O documento discute estruturas de dados probabilísticas para lidar com grandes volumes de dados, como Bloom Filters, Hit Counting e HyperLogLog. Essas estruturas permitem estimar cardinalidades de forma eficiente em termos de espaço e tempo.






































