Baixar para ler offline




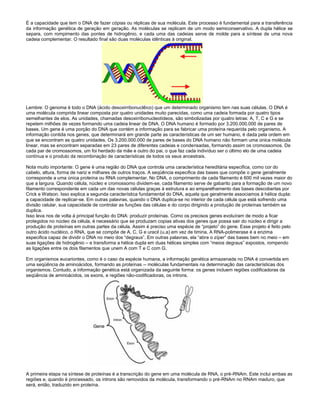




O documento descreve a estrutura e composição dos ácidos nucléicos DNA e RNA. O DNA é encontrado no núcleo celular e contém as bases adenina, guanina, citosina e timina. Já o RNA atua no citoplasma e contém adenina, guanina, citosina e uracilo. Ambos são polímeros de nucleotídeos compostos por uma pentose, fosfato e base nitrogenada. O DNA forma uma dupla hélice com as bases complementares apareadas por pontes de hidrogênio.



































































