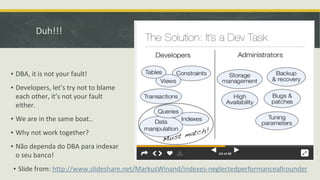
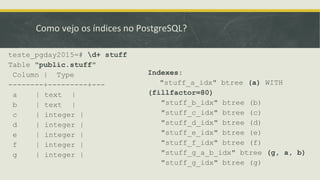
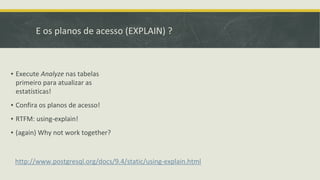
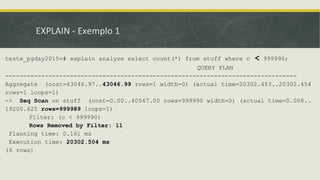
Baixado 24 vezes


![Agenda - Resumo
▪ Conceituação
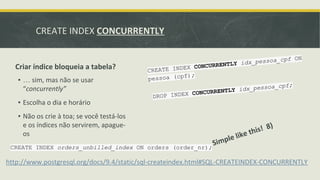
▪ CREATE INDEX [CONCURRENTLY]
▪ FILLFACTOR
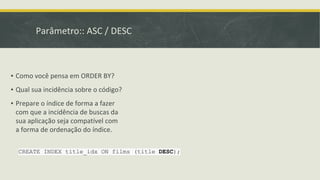
▪ ASC/DESC
▪ NULLS FIRST / NULLS LAST
▪ UNIQUE
▪ Múltiplas Colunas (composto)
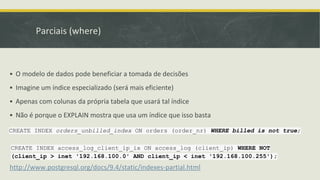
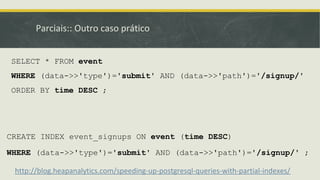
▪ Parciais (where)
▪ Tablespaces
▪ Operadores e Funções
▪ Métodos de acesso
▪ Btree
▪ GiST (opt.: Buffering)
▪ GIN (opt.: FastUpdate)
▪ Hash (evite usar)
▪ SP-GiST
▪ BRIN (novidade)
▪ Vodka
▪ (Outros)](https://image.slidesharecdn.com/pgdaycampinas2015-150810120604-lva1-app6892/85/pgDay-Campinas-2015-2-320.jpg)

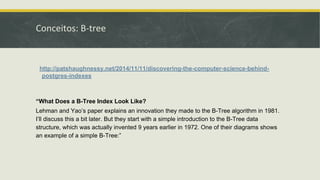
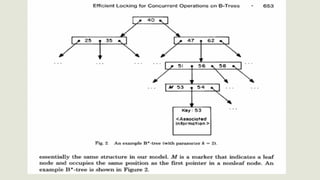
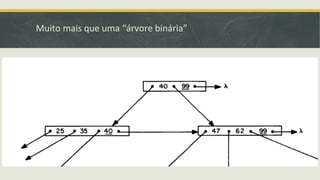
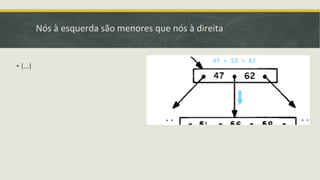
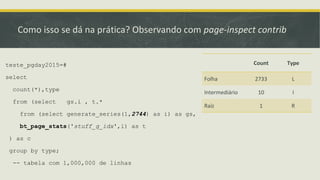
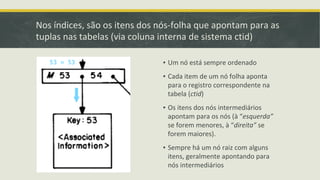
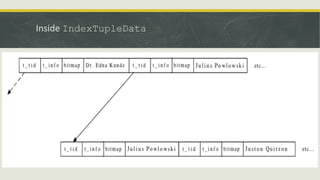


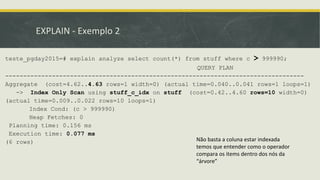






![Outros Métodos de Acesso::GiST
▪ Suporta tipos de dados
customizados!
▪ Utilizados em visão computacional,
bioinformática, remote sensing[1],
▪ São “grandes”, demoram um pouco
mais para serem construidos
▪ Generalized Search Tree (GiST)
▪ box, circle, inet, cidr, point, polygon,
ranges, tsquery, tsvector
▪ Utiliza operadores especializados
▪ Utiliza operadores customizados
▪ Em contribs (btree_gist, cube, hstore,
intarray, ltree, pg_trgm, seg)](https://image.slidesharecdn.com/pgdaycampinas2015-150810120604-lva1-app6892/85/pgDay-Campinas-2015-31-320.jpg)




![PGStrom [wtf?]
▪ NVidias’s CUDA Support
https://wiki.postgresql.org/wiki/PGStrom](https://image.slidesharecdn.com/pgdaycampinas2015-150810120604-lva1-app6892/85/pgDay-Campinas-2015-37-320.jpg)
![PGStrom [wtf?^2]
https://wiki.postgresql.org/wiki/PGStrom](https://image.slidesharecdn.com/pgdaycampinas2015-150810120604-lva1-app6892/85/pgDay-Campinas-2015-38-320.jpg)


Esta palestra abordará conceitos e práticas sobre índices no PostgreSQL, incluindo: (1) a teoria por trás dos índices B-tree, (2) casos práticos como índices compostos e parciais, e (3) quando utilizá-los para obter melhor performance. Além disso, serão discutidos outros métodos de acesso como GiST, GIN, Hash e SP-GiST.






![[Webinar] Performance e otimização de banco de dados MySQL](https://cdn.slidesharecdn.com/ss_thumbnails/performanceeotimizaodebancodedadosmysql-150924140113-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)

















































