Baixar para ler offline











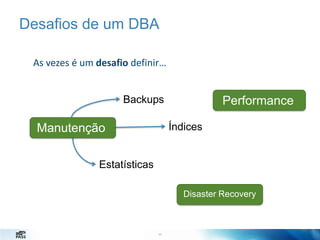



























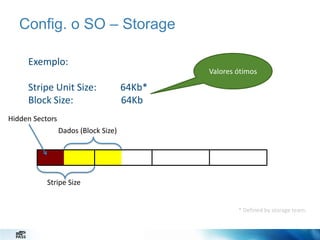
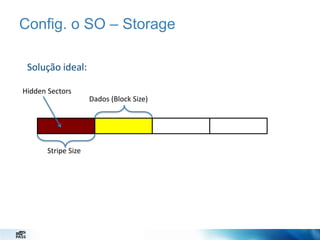




























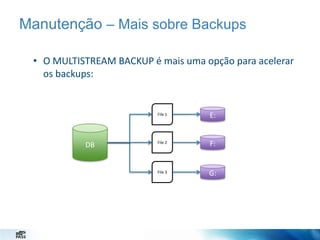
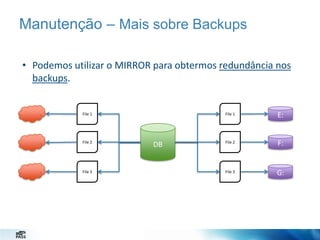





O documento discute estratégias de administração de banco de dados. Apresenta desafios de um administrador de banco de dados como minimizar alarmes e aumentar disponibilidade. Detalha configurações importantes como o SO, instância e banco de dados para melhor desempenho, como configurar a TempDB, rede e armazenamento.










































![[24HOP] SQL Server em maquinas virtuais do Windows Azure](https://cdn.slidesharecdn.com/ss_thumbnails/24hopsqlserveremmquinasvirtuaisdowindowsazure-140329123935-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)

















