


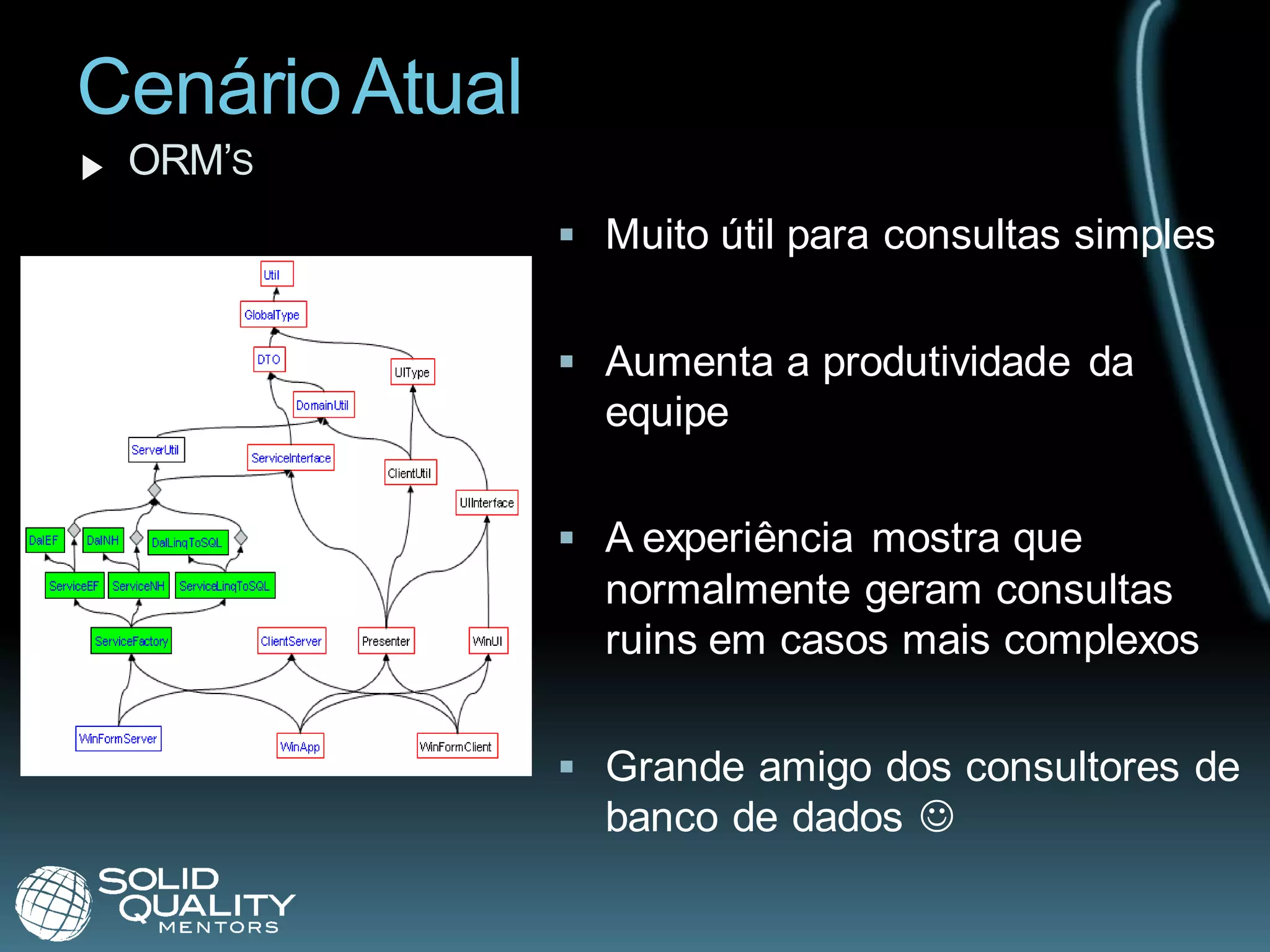



















O documento discute como melhorar o desempenho do SQL Server abordando tópicos como: 1) otimizar o design do banco de dados escolhendo tipos de dados e normalização apropriados; 2) configurar corretamente o SQL Server; 3) usar ferramentas como Profiler, DTA e DMVs para identificar e corrigir problemas de consulta e índices. O documento enfatiza a importância de considerar a performance desde o início do desenvolvimento.













































