Baixar para ler offline





























































![Modelo SAR
A estimação do modelo SAR é feita assumindo que o vetor
de erros tem distribuição normal multivariada com média
zero e covariância σ2I
O modelo SAR pode ser escrito da seguinte forma:
y = (I − ρW)−1
Xβ + (I − ρW)−1
O vetor de observações y possui distribuição condicional a
X normal multivariada, com média e variância condicional,
dadas por:
E[Y|X] = (I − ρW)−1
Xβ
Σ[Y|X] = σ2
(I − ρW)−1
(I − ρW)−1
Notes](https://image.slidesharecdn.com/iv-areas-160201190626/85/Iv-areas-66-320.jpg)




![Modelo SEM
O vetor de observações y possui distribuição condicional a
X normal multivariada, com média e variância condicional,
dadas por:
E[Y|X] = Xβ
Σ[Y|X] = σ2
(I − ρW)−1
(I − ρW)−1
A estimação é feita por maxima verosimilhança condicional
Notes](https://image.slidesharecdn.com/iv-areas-160201190626/85/Iv-areas-71-320.jpg)

![Modelo SARMA
A estimação do modelo é feita por máxima verossimilhança,
assumindo que o ∼ N(0, σ2I), e reescrevendo o modelo
y = (I − ρW1)−1
Xβ + (I − ρW1)−1
(I − λW2)−1
O vetor de observações y possui distribuição condicional a
X normal multivariada, com média e variância condicional,
dadas por:
E[Y|X] = (I − ρW1)−1
Xβ
Σ[Y|X] = σ2
(I − ρW)−1
(I − λW2)−1
(I − ρW)−1
(I − λW2)−1
Notes](https://image.slidesharecdn.com/iv-areas-160201190626/85/Iv-areas-73-320.jpg)















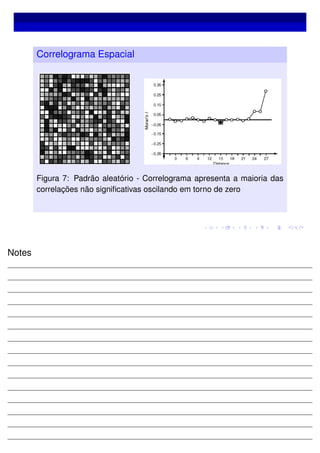
O documento discute análise estatística de dados agregados por área geográfica. Aborda conceitos como vizinhança entre áreas, matrizes de vizinhança e pesos, e média móvel espacial para identificar padrões espaciais nos dados.





















































