

![Sintaxe
• C:
#pragma acc nome_diretiva [cláusula [,cláusula]…]
bloco estruturado de código
• Fortran:
!$acc nome_diretiva [cláusula [,cláusula]…]
bloco estruturado de código
!$acc end nome_diretiva](https://image.slidesharecdn.com/jpanetta-aula4-parte2-120731125046-phpapp02/85/Introducao-ao-Processamento-Paralelo-4-2-3-320.jpg)
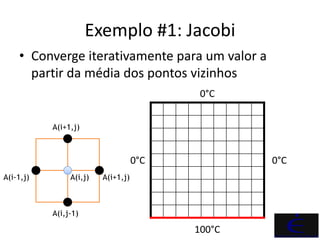




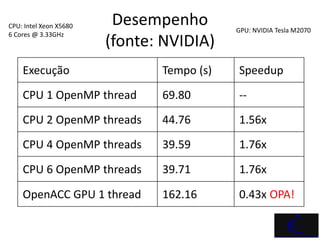
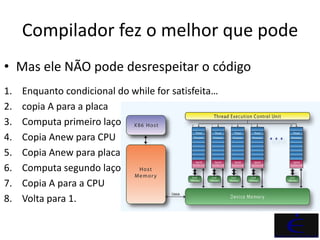



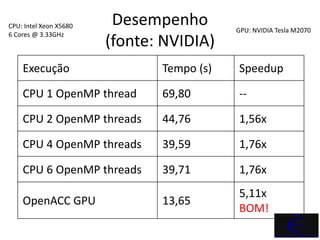



OpenACC é um padrão que permite a aceleração de códigos por meio de diretivas de compilação que orientam o compilador a utilizar aceleradores como GPUs. O documento detalha exemplos práticos de uso de OpenACC em Fortran, demonstrando sua eficácia na melhoria de desempenho e portabilidade do código. Além disso, apresenta comparações de desempenho entre execução em CPU e GPU, ressaltando o aumento significativo de speedup obtido com a implementação de OpenACC.


































![[Ottoni micro05] resume](https://cdn.slidesharecdn.com/ss_thumbnails/ottonimicro05resume-111220195110-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)









![Full Waveform Inversion: Introdução e Aplicações [5/5]](https://cdn.slidesharecdn.com/ss_thumbnails/a05metodoadjuntov04-160712144138-thumbnail.jpg?width=640&height=640&fit=bounds)
![Full Waveform Inversion: Introdução e Aplicações [4/5]](https://cdn.slidesharecdn.com/ss_thumbnails/a04fwialgoritmogeralv03-160712143538-thumbnail.jpg?width=640&height=640&fit=bounds)
![Full Waveform Inversion: Introdução e Aplicações [3/5]](https://cdn.slidesharecdn.com/ss_thumbnails/a03otimizacaov03-160712143225-thumbnail.jpg?width=640&height=640&fit=bounds)
![Full Waveform Inversion: Introdução e Aplicações [2/5]](https://cdn.slidesharecdn.com/ss_thumbnails/a02modelagemv03-160712143007-thumbnail.jpg?width=640&height=640&fit=bounds)
![Full Waveform Inversion: Introdução e Aplicações [1/5]](https://cdn.slidesharecdn.com/ss_thumbnails/a01introduov04-160712142615-thumbnail.jpg?width=640&height=640&fit=bounds)

































