Baixar para ler offline





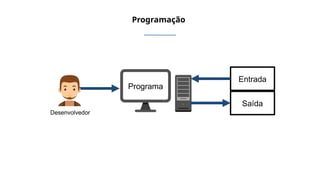
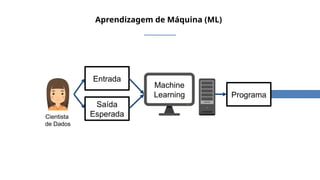
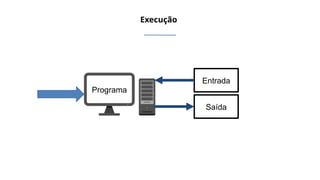
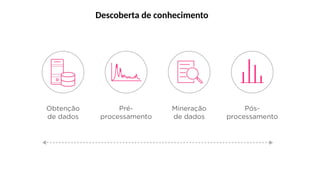
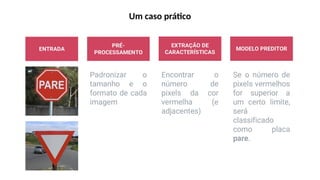
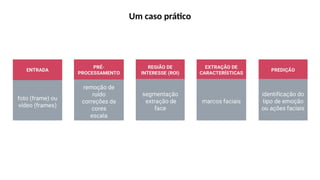
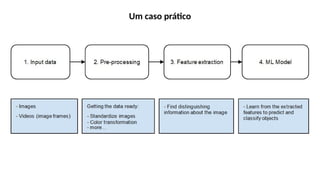
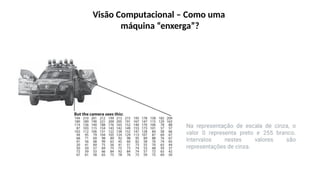
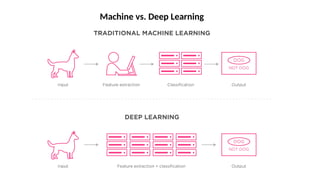
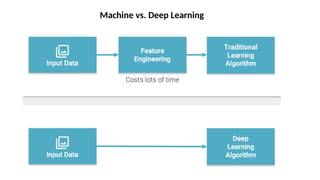
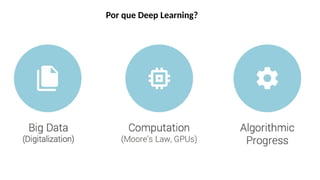
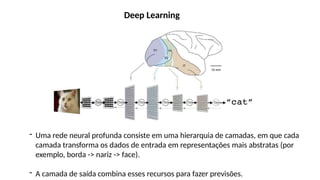
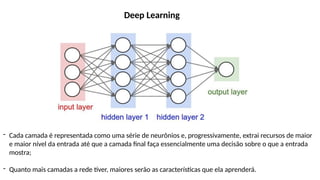
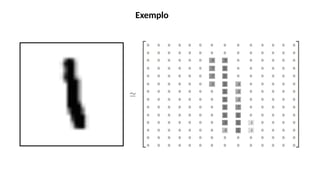
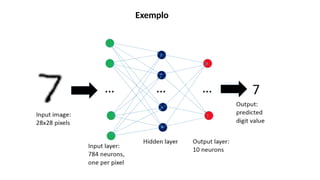
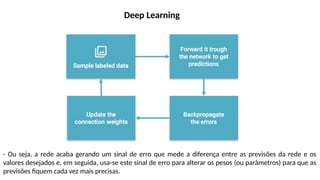





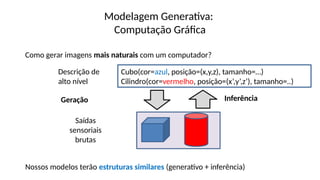

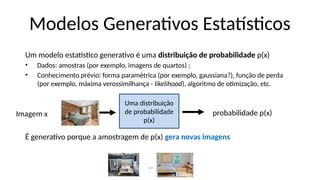







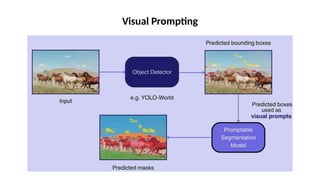
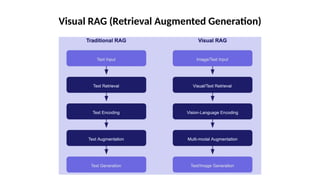
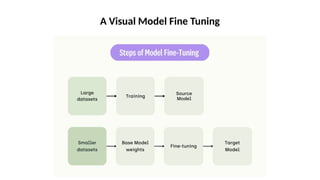
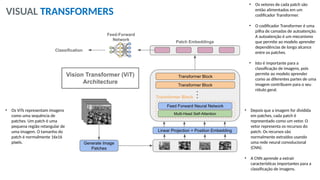

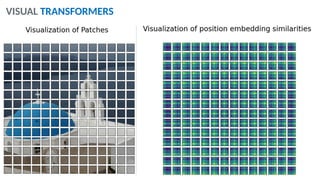
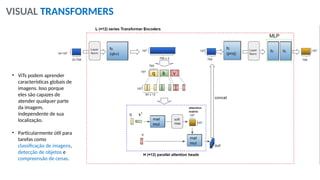
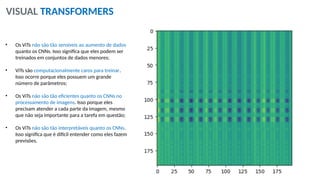
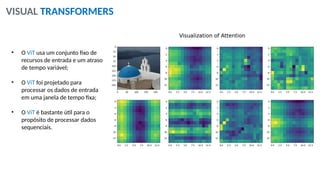
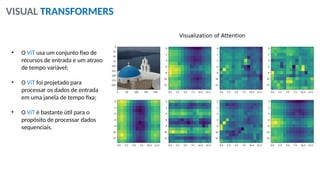





O documento aborda a visão computacional, explorando como máquinas podem 'enxergar' através de deep learning e inteligência artificial generativa. Discute técnicas, desafios e soluções na modelagem generativa, destacando o uso de visual transformers e suas implicações em tarefas de classificação e compreensão de imagens. O autor enfatiza a importância de sistemas de visão computacional que garantam inteligibilidade, conscientização sobre dados e segurança.




![[Jose Ahirton lopes] Do Big ao Better Data](https://cdn.slidesharecdn.com/ss_thumbnails/ahirtonlopesdobigaobetterdata-190410143141-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Jose Ahirton Lopes] Inteligencia Artificial - Uma Abordagem Visual](https://cdn.slidesharecdn.com/ss_thumbnails/joseahirtonlopesinteligenciaartificial-umaabordagemvisual-200103185454-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Jose Ahirton Lopes] Inteligencia Artificial - Uma Abordagem Visual](https://cdn.slidesharecdn.com/ss_thumbnails/joseahirtonlopes-meetupinteligenciaartificial-umaabordagemvisual-200215025106-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Jose Ahirton Lopes] Deep Learning - Uma Abordagem Visual](https://cdn.slidesharecdn.com/ss_thumbnails/joseahirtonlopesdeeplearning-umaabordagemvisual-181209205137-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Jose Ahirton Lopes] Deep Learning - Uma Abordagem Visual](https://cdn.slidesharecdn.com/ss_thumbnails/joseahirtonlopesdeeplearning-umaabordagemvisual-181204182142-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Ahirton Lopes e Rafael Arevalo] Deep Learning - Uma Abordagem Visual](https://cdn.slidesharecdn.com/ss_thumbnails/ahirtonlopeserafaelarevalodeeplearning-umaabordagemvisual-190215183628-thumbnail.jpg?width=640&height=640&fit=bounds)














![[Jose Ahirton Lopes] Deep Learning - Uma Abordagem Visual](https://cdn.slidesharecdn.com/ss_thumbnails/joseahirtonlopesdeeplearning-umaabordagemvisual-181003230235-thumbnail.jpg?width=640&height=640&fit=bounds)

















![[Jose Ahirton Lopes] ML na Sala de Aula](https://cdn.slidesharecdn.com/ss_thumbnails/joseahirtonlopesmlnasaladeaula1-200123030521-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Jose Ahirton Lopes] ML na sala de aula](https://cdn.slidesharecdn.com/ss_thumbnails/joseahirtonlopesmlnasaladeaula-191204203059-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Jose Ahirton Lopes] IA e para todos](https://cdn.slidesharecdn.com/ss_thumbnails/joseahirtonlopesiaeparatodos-191128000830-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Jose Ahirton Lopes] O que se espera da tal equipe de dados](https://cdn.slidesharecdn.com/ss_thumbnails/joseahirtonlopesoqueseesperadatalequipededados-191110025806-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Jose Ahirton Lopes] Detecção Precoce de Estudantes em Risco de Evasão Usan...](https://cdn.slidesharecdn.com/ss_thumbnails/joseahirtonlopes-deteccaooprecocedeestudantesemriscodeevasaousandodadosadministrativoseaprendizagemd-191029002634-thumbnail.jpg?width=640&height=640&fit=bounds)