Baixado 10 vezes


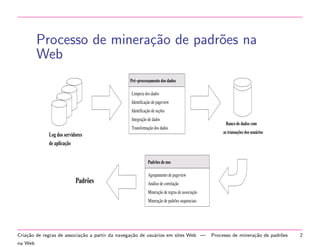


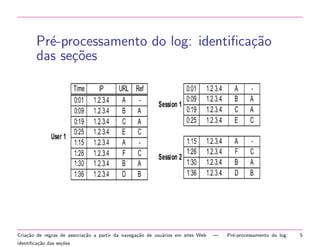
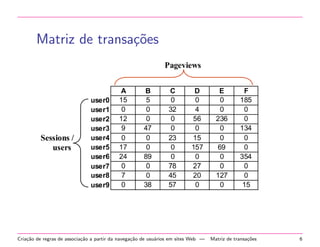




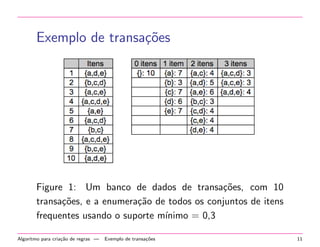









O documento descreve o processo de mineração de padrões na Web para criar regras de associação a partir da navegação de usuários em sites. O processo inclui pré-processamento de logs, identificação de usuários e seções, criação de uma matriz de transações e mineração de itens frequentes e regras de associação.






















![Pré-processamento [no R] e Análise Exploratória - Curso de Big Data](https://cdn.slidesharecdn.com/ss_thumbnails/analiseexploratoriav2-150622235900-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)









![Web Data Mining com R: pré-processamento de dados [no R]](https://cdn.slidesharecdn.com/ss_thumbnails/aprocessamentodados-140207143831-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)





