Transferir como PDF, PPTX













![Algoritmos de CB - TFIDF
17
Figura: ModeloVetorial [Dr. Edberto Ferneda, Unesp, 2010]](https://image.slidesharecdn.com/joelrecsystemprint-140410202955-phpapp02/85/Conceitos-e-praticas-em-Sistemas-de-Recomendacao-17-320.jpg)



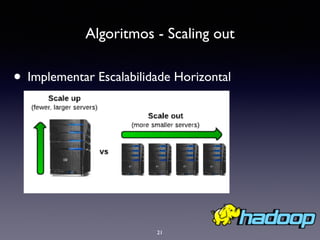

![Map Input:
{[user: U1, items: [P1, P3, P6],
user: U2, items: [P1, P9],
user: U3, items: [P1, P6, P8]]}
23
Algoritmos - Scaling out
Map Output/Reduce Input:
(P1: [P3, P6];
P3: [P1, P6];
P6: [P1, P3];
P1: [P9];
P9: [P1];
P1: [P6, P8];
P6: [P1, P8];
P8: [P1, P6])
Reduce Output:
(P1: [P3, P6, P8];
P3: [P1, P6];
P6: [P1, P3, P8];
P8: [P1, P6])](https://image.slidesharecdn.com/joelrecsystemprint-140410202955-phpapp02/85/Conceitos-e-praticas-em-Sistemas-de-Recomendacao-23-320.jpg)





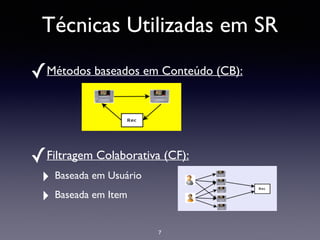
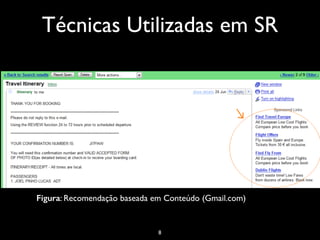
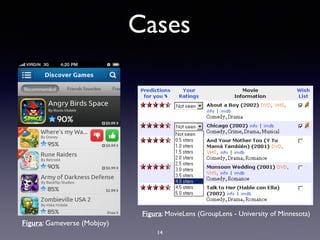
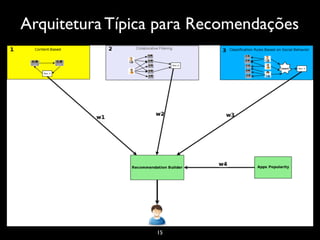
O documento discute sistemas de recomendação, incluindo técnicas como filtragem colaborativa e baseada em conteúdo, problemas comuns e desafios, e algoritmos como KNN e TF-IDF. Ele também fornece exemplos de casos e recursos para começar a desenvolver sistemas de recomendação.

























![[Jose Ahirton Lopes] Algoritmos de Recomendacao II](https://cdn.slidesharecdn.com/ss_thumbnails/joseahirtonlopesalgoritmosderecomendacao-1809062102561-181102020815-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Jose Ahirton Lopes] Algoritmos de Recomendacao](https://cdn.slidesharecdn.com/ss_thumbnails/joseahirtonlopesalgoritmosderecomendacao-180906210256-thumbnail.jpg?width=640&height=640&fit=bounds)

















