Transferir como PDF, PPTX


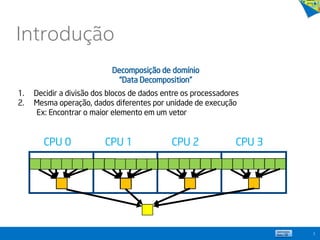
![for( i = 0; i < 3; i++)
a[i] = b[i]/2.0;
6
b[0] b[1] b[2]
a[0] a[1] a[2]
///
2 2 2
Decomposição de domínio possível
Introdução
Detectando paralelismo](https://image.slidesharecdn.com/principaisconceitos-tcnicasemodelosdeprogramaoparalela-140603143345-phpapp02/85/Principais-conceitos-tecnicas-e-modelos-de-programacao-paralela-6-320.jpg)
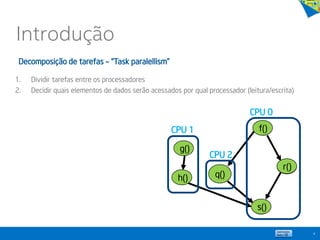
![for( i = 1; i < 4; i++)
a[i] = a[i-1]*b[i];
7
b[1] b[2] b[3]
a[1] a[2] a[3]
***
a[0]
Decomposição de domínio falha neste caso
Introdução
Detectando paralelismo](https://image.slidesharecdn.com/principaisconceitos-tcnicasemodelosdeprogramaoparalela-140603143345-phpapp02/85/Principais-conceitos-tecnicas-e-modelos-de-programacao-paralela-7-320.jpg)
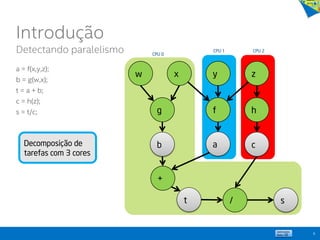



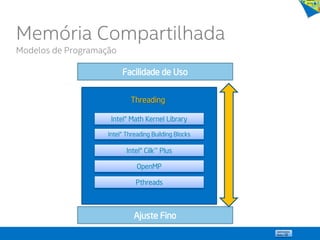
![Memória Compartilhada
Decomposição de Domínio via Threads
Código sequencial:
Thread 0
Thread 1
13
for (i = 500; i < 1000; i++) a[i] = foo(i);
for (i = 0; i < 500; i++) a[i] = foo(i);
int a[1000], i;
for (i = 0; i < 1000; i++) a[i] = foo(i);
Private Shared](https://image.slidesharecdn.com/principaisconceitos-tcnicasemodelosdeprogramaoparalela-140603143345-phpapp02/85/Principais-conceitos-tecnicas-e-modelos-de-programacao-paralela-13-320.jpg)
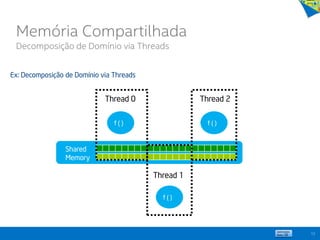
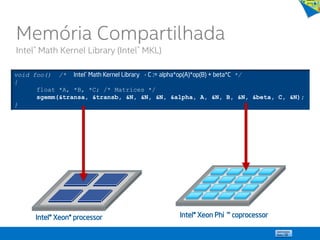
![15
int e;
main () {
int x[10], j, k, m; j = f(x, k); m = g(x, k);
...
}
int f(int *x, int k)
{
int a; a = e * x[k] * x[k]; return a;
}
int g(int *x, int k)
{
int a; k = k-1; a = e / x[k]; return a;
}
Thread 0
Thread 1
Static variable: Shared
Global to threads: Shared
Function’s local variables: Private
Shared
Variables
Private
Variables
Private
Variables
Thread
Thread
Memória privada e Memória compartilhada
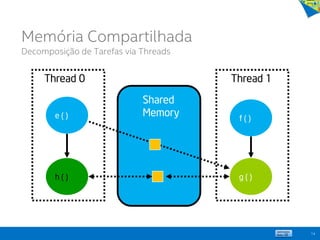
Memória Compartilhada
Decomposição de Tarefas via Threads](https://image.slidesharecdn.com/principaisconceitos-tcnicasemodelosdeprogramaoparalela-140603143345-phpapp02/85/Principais-conceitos-tecnicas-e-modelos-de-programacao-paralela-15-320.jpg)
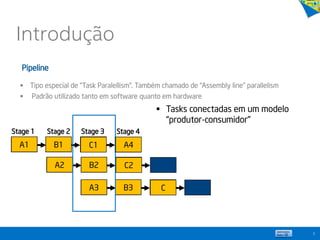
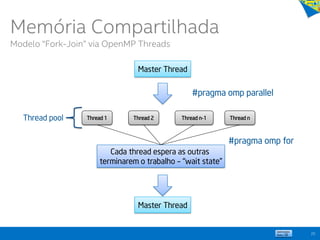
![ Paralelismo com 3 palavras-chaves
cilk_spawn
cilk_sync
cilk_for
Cilk™ Plus:
Projeto Open Source
Load Balancing
Sincronização
Protocolos de comunicação
Evita estouro de pilha
19
Learn more at http://cilkplus.org
// Parallel function invocation, in C
cilk_for (int i=0; i<n; ++i){
Foo(a[i]);
}
// Parallel spawn in a recursive fibonacci
// computation, in C
int fib (int n) {
if (n < 2) return 1;
else {
int x, y;
x = cilk_spawn fib(n-1);
y = fib(n-2);
cilk_sync;
return x + y;
}
}
Memória Compartilhada
Intel® Cilk™ Plus](https://image.slidesharecdn.com/principaisconceitos-tcnicasemodelosdeprogramaoparalela-140603143345-phpapp02/85/Principais-conceitos-tecnicas-e-modelos-de-programacao-paralela-19-320.jpg)
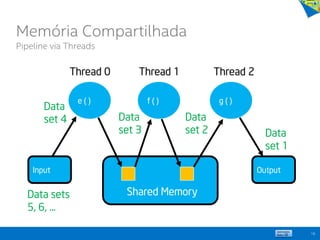
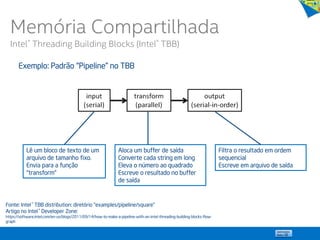
![21
Paralelizando um Loop
1. double res[200]; int i;
2. #pragma omp parallel for
3. for (i=0;i< 200; i++) {
4. res[i] = foo();
5. }
Thread 1
res[0] = foo();
res[1] = foo();
res[2] = foo();
res[3] = foo();
Thread 2
res[4] = foo();
res[5] = foo();
res[6] = foo();
res[7] = foo();
Thread N
res[MAX-3] = foo();
res[MAX-2] = foo();
res[MAX-1] = foo();
res[MAX] = foo();
...
Memória Compartilhada
OpenMP](https://image.slidesharecdn.com/principaisconceitos-tcnicasemodelosdeprogramaoparalela-140603143345-phpapp02/85/Principais-conceitos-tecnicas-e-modelos-de-programacao-paralela-21-320.jpg)

{
Foo(a[i]);
});
Memória Compartilhada
Intel® Threading Building Blocks (Intel® TBB)](https://image.slidesharecdn.com/principaisconceitos-tcnicasemodelosdeprogramaoparalela-140603143345-phpapp02/85/Principais-conceitos-tecnicas-e-modelos-de-programacao-paralela-22-320.jpg)








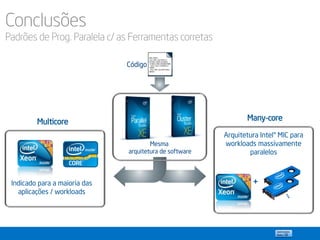


1) O documento apresenta os principais conceitos, técnicas e modelos de programação paralela, incluindo memória compartilhada e distribuída. 2) São discutidos padrões como decomposição de domínio, decomposição de tarefas e pipeline para detectar oportunidades de paralelismo. 3) Ferramentas como OpenMP, Intel TBB, Cilk Plus e MPI são apresentadas para implementar programação paralela em memória compartilhada e distribuída.







![(2013-05-20) [DevInSampa] AudioLazy - DSP expressivo e em tempo real para o P...](https://cdn.slidesharecdn.com/ss_thumbnails/20130520devinsamparevisedptbr-130520113224-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)














































![[Pereira ic'2011] explorando o paralelismo no nível de threads](https://cdn.slidesharecdn.com/ss_thumbnails/pereiraic2011explorandooparalelismononveldethreads-111008083559-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)






![[Ottoni micro05] resume](https://cdn.slidesharecdn.com/ss_thumbnails/ottonimicro05resume-111220195110-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)

















