Baixado 27 vezes


![Implementação Escalar
Modo Escalar
Uma instrução produz
um resultado
for (i=0;i<=MAX;i++)
c[i]=a[i]+b[i];](https://image.slidesharecdn.com/isc-2013-3-11-vetorizacao-130821204554-phpapp02/75/Vetorizacao-e-Otimizacao-de-Codigo-Intel-Software-Conference-2013-4-2048.jpg)
![Implementação Vetorizada
Processamento SIMD
(vetorizado)
Instruções SSE, AVX, AVX2
Uma instrução pode produzir
múltiplos resultados
for (i=0;i<=MAX;i++)
c[i]=a[i]+b[i];](https://image.slidesharecdn.com/isc-2013-3-11-vetorizacao-130821204554-phpapp02/75/Vetorizacao-e-Otimizacao-de-Codigo-Intel-Software-Conference-2013-5-2048.jpg)





![Notação de Arrays - Intel® Cilk™ Plus
Sintaxe para especificar seções dos arrays nas quais executar
determinadas operações
Sintaxe: [<limite inferior> : <tamanho> : <passo>]
• Exemplos
a[0:N] = b[0:N] * c[0:N];
a[:] = b[:] * c[:] // se a, b, c são declarados
com tamanho N
A vetorização automática do compilador C++ Intel® pode usar
essa informação para aplicar operações únicas para múltiplos
elementos do array usando Intel® Streaming SIMD Extensions
(Intel® SSE) e Intel® Advanced Vector Extensions (Intel® AVX)
• Exemplo mais avançado:
x[0:10:10] = sin(y[20:10:2]);](https://image.slidesharecdn.com/isc-2013-3-11-vetorizacao-130821204554-phpapp02/75/Vetorizacao-e-Otimizacao-de-Codigo-Intel-Software-Conference-2013-12-2048.jpg)
![Exemplo de Notação de Arrays
void foo(double * a, double * b, double * c, double * d,
double * e, int n) {
for(int i = 0; i < n; i++)
a[i] *= (b[i] - d[i]) * (c[i] + e[i]);
}
void goo(double * a, double * b, double * c, double * d,
double * e, int n) {
a[0:n] *= (b[0:n] - d[0:n]) * (c[0:n] + e[0:n]);
}
icl -Qvec-report3 -c test-array-notations.cpp
Intel(R) C++ Intel(R) 64 Compiler XE for applications running on Intel(R) 64, Version 12.1.4.325 Build
20120410
Copyright (C) 1985-2012 Intel Corporation. All rights reserved.
test-array-notations.cpp
test-array-notations.cpp(2): (col. 2) remark: loop was not vectorized: existence of vector dependence.
test-array-notations.cpp(3): (col. 3) remark: vector dependence: assumed FLOW dependence between a
line 3 and e line 3.
<snip>
test-array-notations.cpp(7): (col. 6) remark: LOOP WAS VECTORIZED.](https://image.slidesharecdn.com/isc-2013-3-11-vetorizacao-130821204554-phpapp02/75/Vetorizacao-e-Otimizacao-de-Codigo-Intel-Software-Conference-2013-13-2048.jpg)


![Exemplo de Função Elementar
double user_function(double x);
__declspec(vector) double elemental_function(double x);
double a[100];
double b[100];
void foo() {
a[:] = user_function(b[:]);
a[:] = elemental_function(b[:]);
}
icl /Qvec-report3 /c test-elemental-functions.cpp
Intel(R) C++ Intel(R) 64 Compiler XE for applications running on Intel(R) 64, Version 12.1.4.325 Build
20120410
Copyright (C) 1985-2012 Intel Corporation. All rights reserved.
test-elemental-functions.cpp
test-elemental-functions.cpp(9)
: (col. 4) remark: LOOP WAS VECTORIZED.
test-elemental-functions.cpp(8)
: (col. 4) remark: loop was not vectorized: nonstandard loop is not a vectorization candidate.](https://image.slidesharecdn.com/isc-2013-3-11-vetorizacao-130821204554-phpapp02/75/Vetorizacao-e-Otimizacao-de-Codigo-Intel-Software-Conference-2013-18-2048.jpg)











![Um exemplo de soma
int compute(const X& v);
int main()
{
const std::size_t n = 1000000;
extern X myArray[n];
// ...
int result = 0;
for (std::size_t i = 0; i < n; ++i)
{
result += compute(myArray[i]);
}
std::cout << "The result is: "
<< result
<< std::endl;
return 0;
}](https://image.slidesharecdn.com/isc-2013-3-11-vetorizacao-130821204554-phpapp02/75/Vetorizacao-e-Otimizacao-de-Codigo-Intel-Software-Conference-2013-32-2048.jpg)
![Somando com Intel® Cilk™ Plus
int compute(const X& v);
int main()
{
const std::size_t n = 1000000;
extern X myArray[n];
// ...
int result = 0;
cilk_for (std::size_t i = 0; i < n; ++i)
{
result += compute(myArray[i]);
}
std::cout << "The result is: "
<< result
<< std::endl;
return 0;
}
Race!](https://image.slidesharecdn.com/isc-2013-3-11-vetorizacao-130821204554-phpapp02/75/Vetorizacao-e-Otimizacao-de-Codigo-Intel-Software-Conference-2013-33-2048.jpg)
![Solução com Locks
int compute(const X& v);
int main()
{
const std::size_t n = 1000000;
extern X myArray[n];
// ...
mutex L;
int result = 0;
cilk_for (std::size_t i = 0; i < n; ++i)
{
int temp = compute(myArray[i]);
L.lock();
result += temp;
L.unlock();
}
std::cout << "The result is: "
<< result
<< std::endl;
return 0;
}
Problemas
Sobrecarga e
contenção dos
Locks](https://image.slidesharecdn.com/isc-2013-3-11-vetorizacao-130821204554-phpapp02/75/Vetorizacao-e-Otimizacao-de-Codigo-Intel-Software-Conference-2013-34-2048.jpg)
![Solução com Reducer do CILK™ Plus
int compute(const X& v);
int main()
{
const std::size_t ARRAY_SIZE = 1000000;
extern X myArray[ARRAY_SIZE];
// ...
cilk::reducer_opadd<int> result;
cilk_for (std::size_t i = 0; i < ARRAY_SIZE; ++i)
{
result += compute(myArray[i]);
}
std::cout << "The result is: "
<< result.get_value()
<< std::endl;
return 0;
}
Declare result como
reducer de soma (int)
Atualizações são
resolvidas automatica/e,
sem races nem contenção
Ao final, o valor (int) pode
ser recuperado (soma)](https://image.slidesharecdn.com/isc-2013-3-11-vetorizacao-130821204554-phpapp02/75/Vetorizacao-e-Otimizacao-de-Codigo-Intel-Software-Conference-2013-35-2048.jpg)








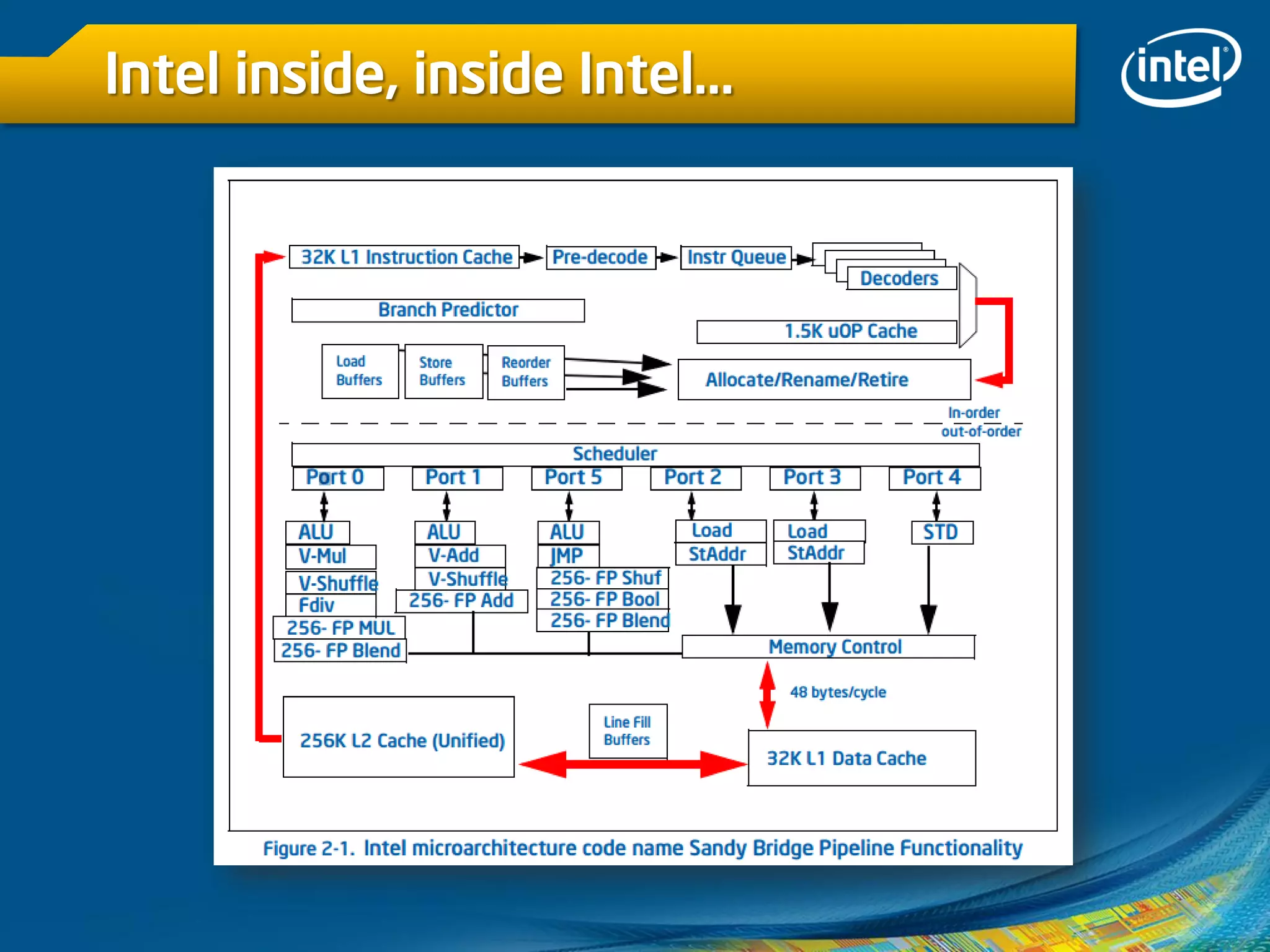
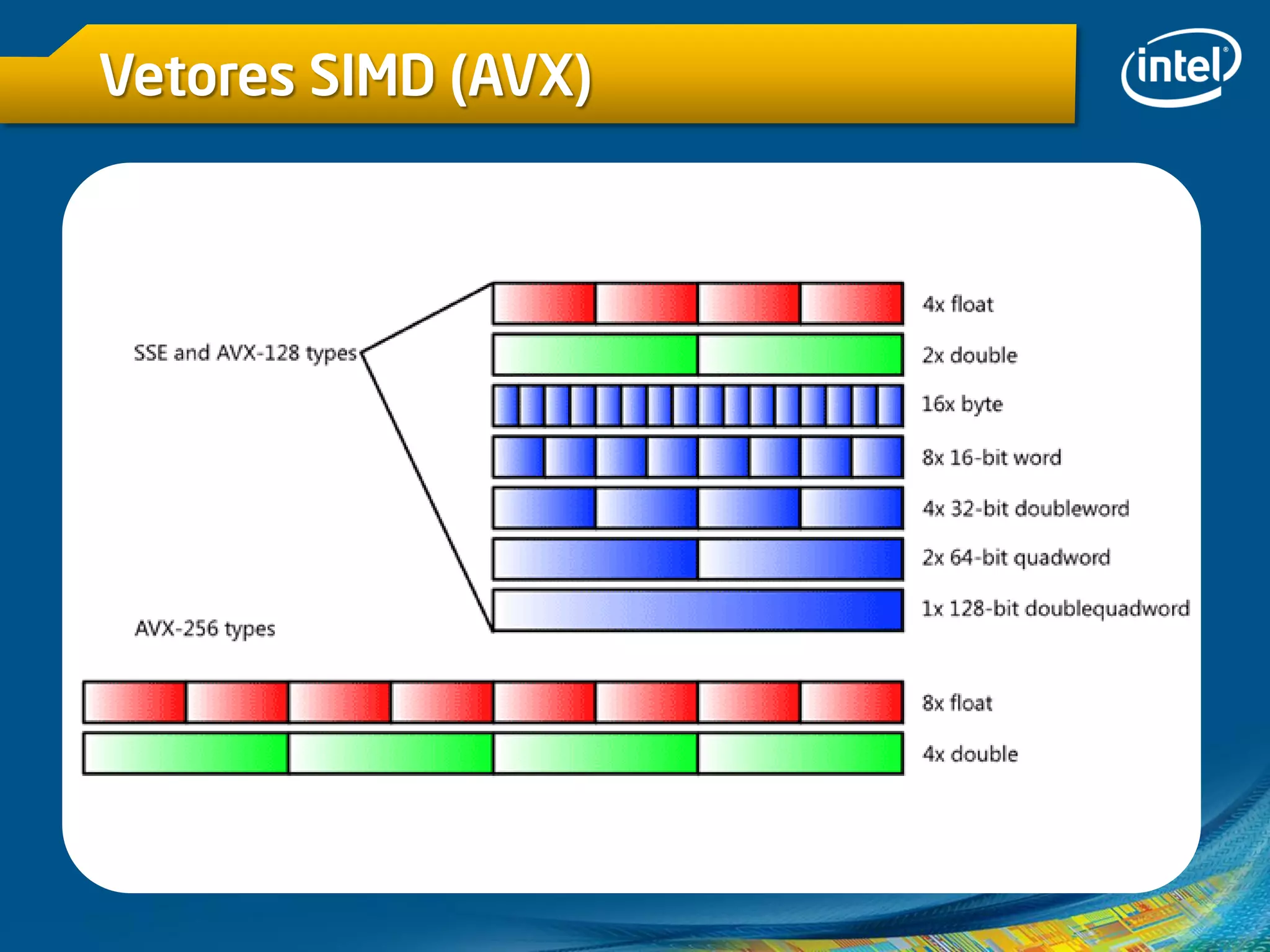
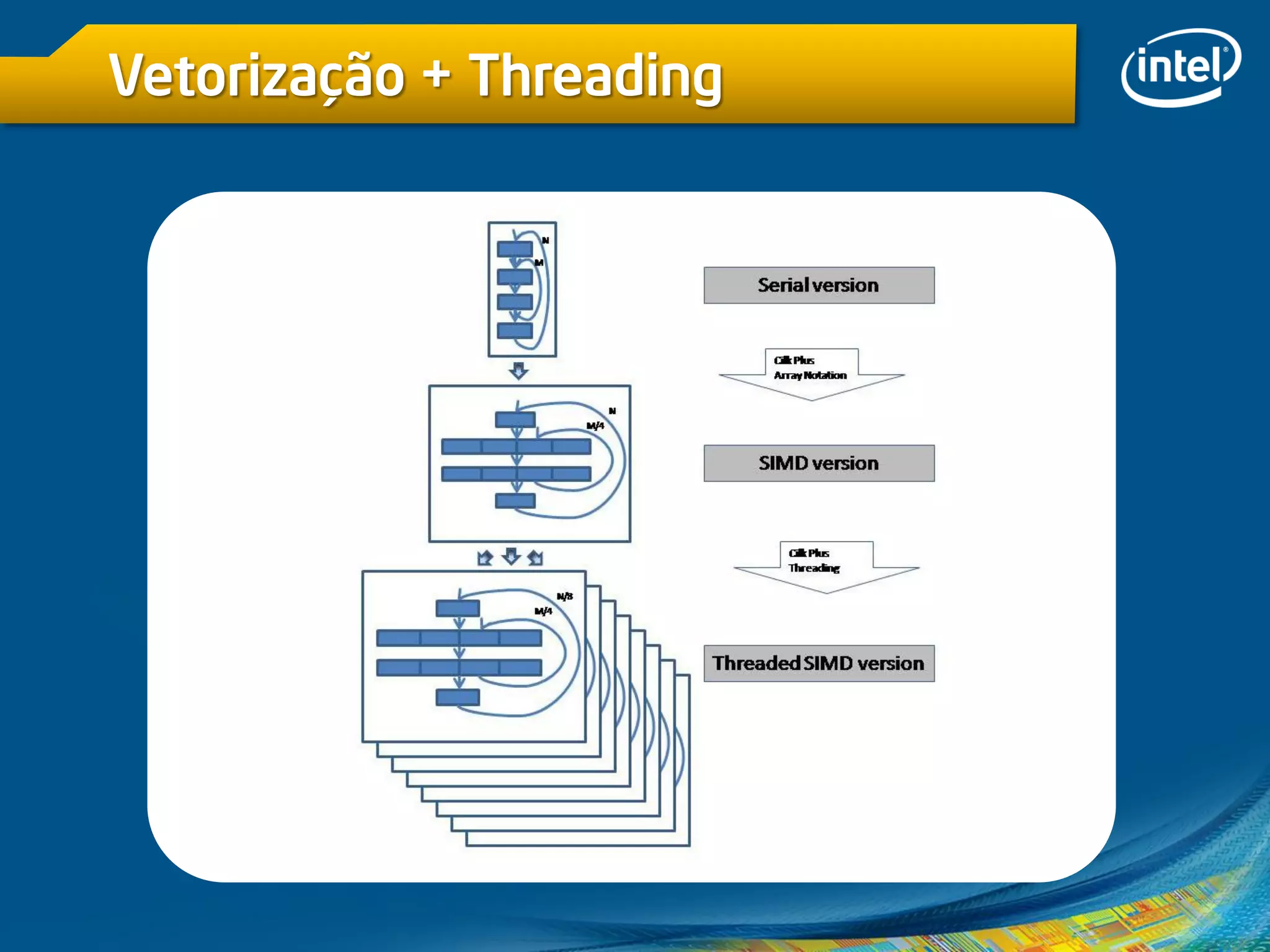
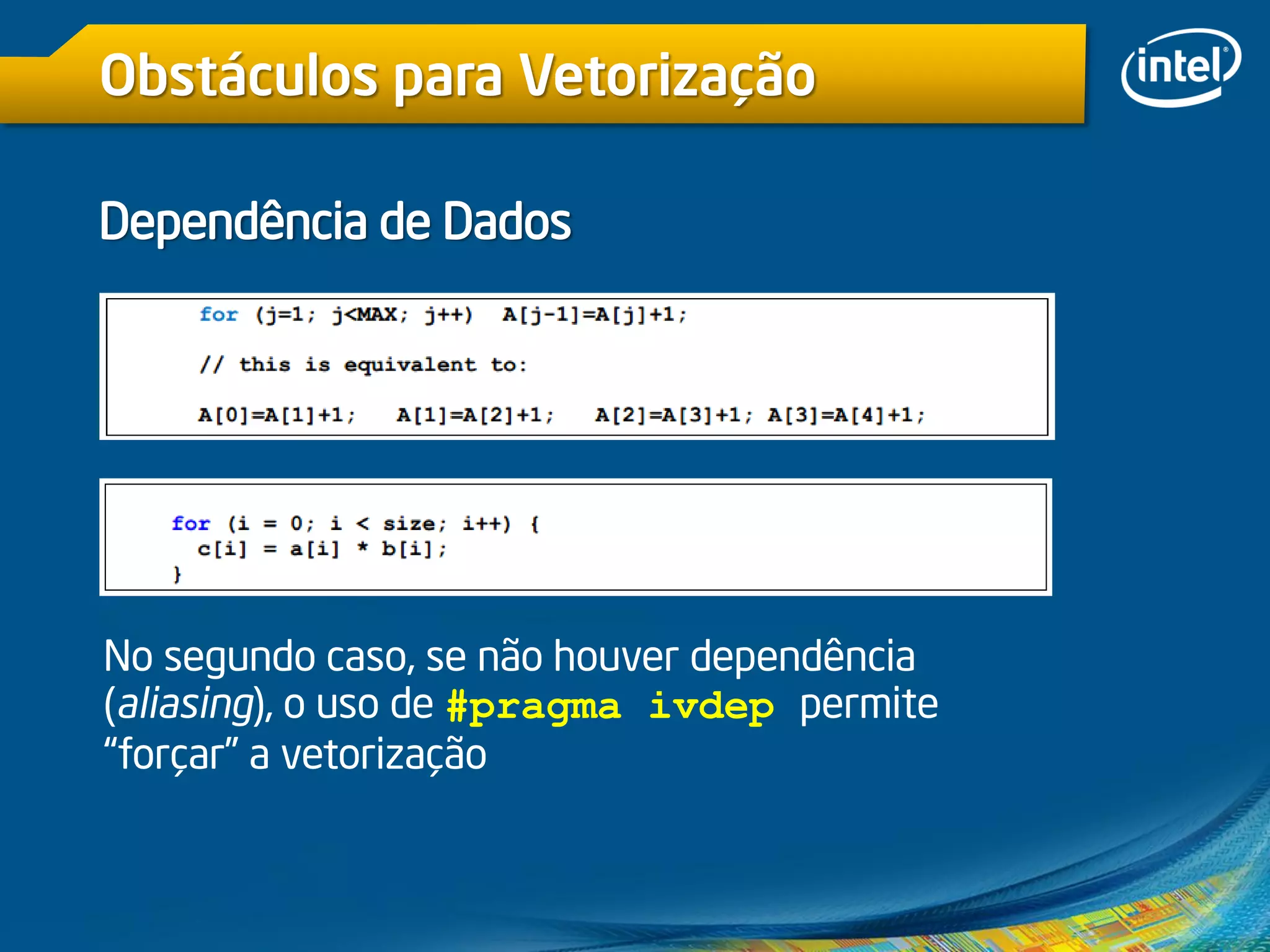
O documento discute vetorização e otimização de código usando o Intel Cilk Plus e técnicas SIMD. Destaca a importância de vetorização para melhorar o desempenho em processadores multi-core, bem como os desafios associados ao uso de API multithread e instruções de vetorização. Também descreve como usar palavras-chave e notação de arrays para facilitar a escrita de código eficiente e abordagens para evitar dependências de dados durante a vetorização.















![(2013-05-20) [DevInSampa] AudioLazy - DSP expressivo e em tempo real para o P...](https://cdn.slidesharecdn.com/ss_thumbnails/20130520devinsamparevisedptbr-130520113224-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)















































![[Ottoni micro05] resume](https://cdn.slidesharecdn.com/ss_thumbnails/ottonimicro05resume-111220195110-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
























