





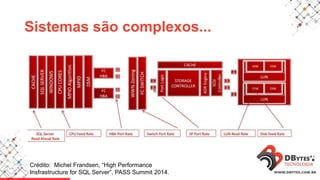




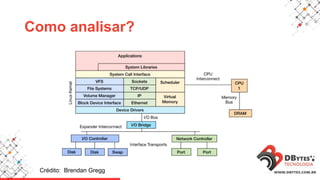




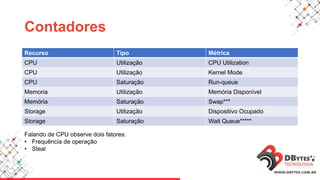





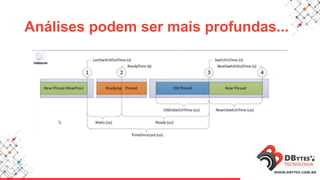
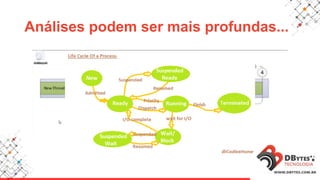


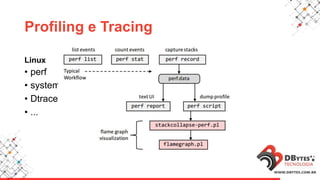





Este documento fornece uma introdução à análise de desempenho usando ferramentas de sistema operacional. Ele discute métodos e ferramentas para monitorar CPUs, memória, E/S de disco e rede em sistemas Linux e Windows. O documento enfatiza a importância de planejar os contadores a serem observados, saber onde procurar problemas e manter registros históricos.














![[Webinar] Performance e otimização de banco de dados MySQL](https://cdn.slidesharecdn.com/ss_thumbnails/performanceeotimizaodebancodedadosmysql-150924140113-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
























