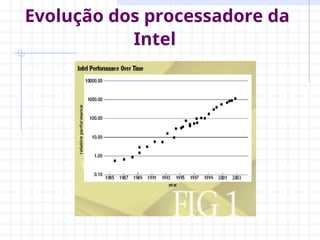
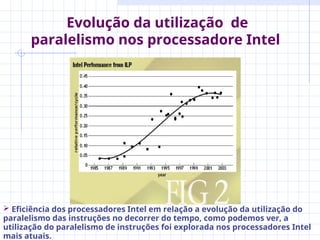
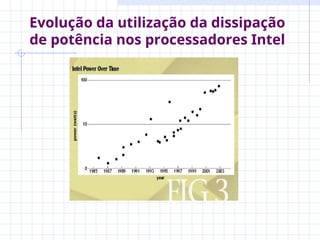
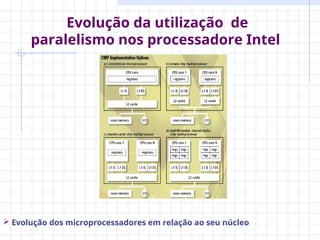
O documento discute a evolução dos microprocessadores, destacando o aumento da performance devido à miniaturização dos transistores e ao uso de técnicas de paralelismo. Apresenta os desafios enfrentados na implementação de processadores superescalares e multiprocessadores, bem como soluções como os CMPs que otimizam o espaço e a eficiência energética. Além disso, aborda a importância da paralelização de software para maximizar o throughput e a latência em aplicações modernas.




























![[Pereira ic'2011] explorando o paralelismo no nível de threads](https://cdn.slidesharecdn.com/ss_thumbnails/pereiraic2011explorandooparalelismononveldethreads-111008083559-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
















































