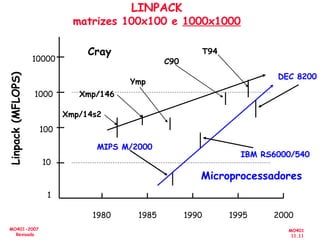
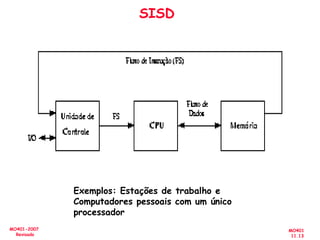
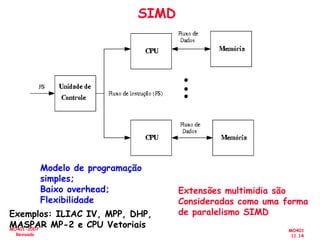
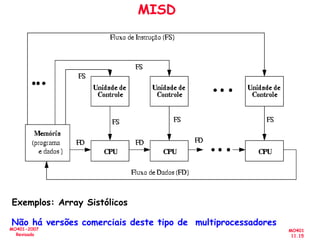
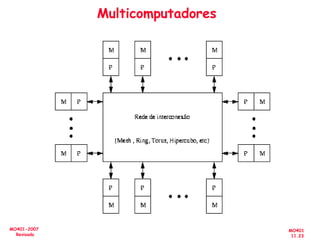
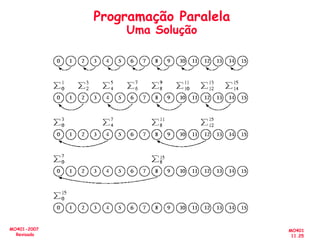
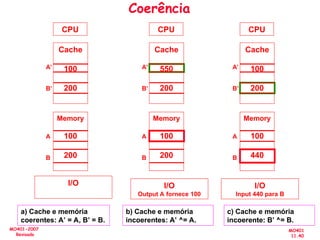
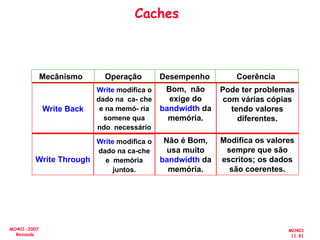
O documento aborda a arquitetura de computadores com foco em multiprocessadores e paralelismo, discutindo conceitos como níveis de paralelismo, classificação de Flynn, leis de desempenho e modelos de programação como memória compartilhada e passagem de mensagens. Ele também enfatiza a importância de projetar sistemas que otimizem o desempenho e enfrentem desafios como latência e eficiência na comunicação. Além disso, os avanços em processadores e suas aplicações são abordados desde a década de 1950 até os dias atuais.












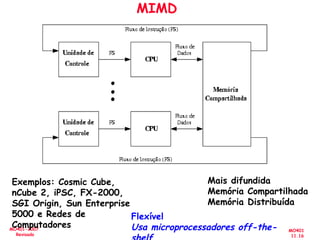



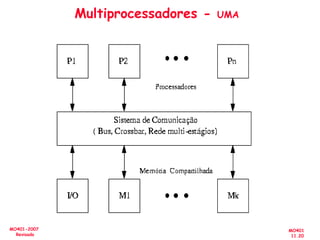
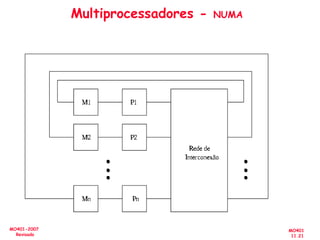
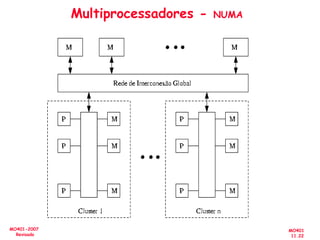















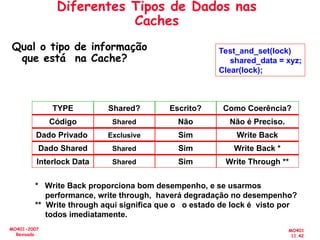






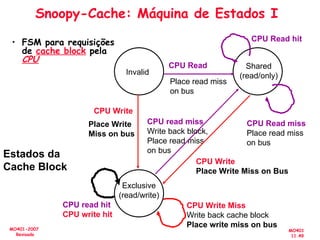
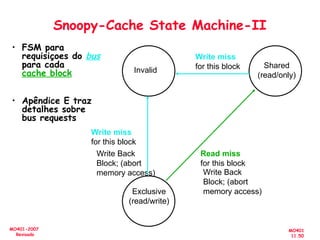
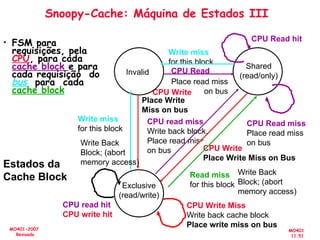
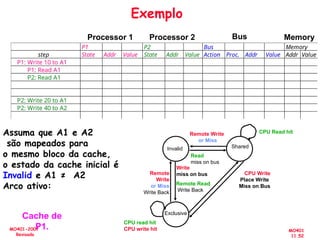
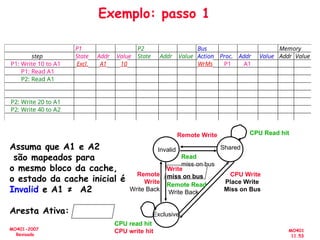
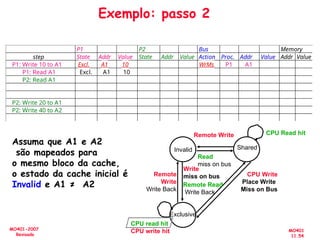
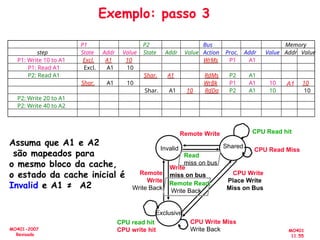
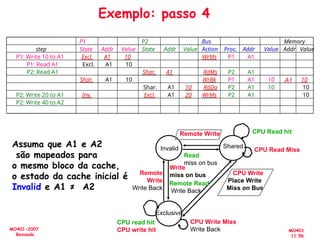
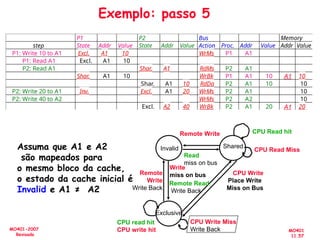
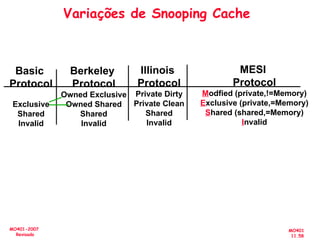
















![[Pereira ic'2011] explorando o paralelismo no nível de threads](https://cdn.slidesharecdn.com/ss_thumbnails/pereiraic2011explorandooparalelismononveldethreads-111008083559-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)





















