Normalização
Um bom projetode uma base de dados garante que usuários podem
modificar o conteúdo da base de dados sem efeitos colaterais não
esperados. Por exemplo uma base de dados da universidade, na qual um
usuário deve ser capaz de inserir um novo curso sem ter que
simultaneamente inserir uma nova oferta do curso e um novo estudante
matriculado no curso.
Da mesma forma, quando um estudante é deletado da base de dados ao
final da sua graduação, dados sobre os cursos que realizou não devem ser
perdidos. Estes problemas são exemplos de anomalias de modificação,
efeitos colaterais não esperados que ocorrem quando alterando o
conteúdo de uma tabela com excess de redundância. Um bom projeto de
base de dados evita anomalias de modificação pela eleminação excessive
de redundâncias.
4.
Normalizar / Porquê?
Apósa construção do modelo conceitual dos dados (Modelo
Entidade/Relacionamento) é feita a transformação para o modelo
lógico (Esquema de Tabelas).
O Desenho de Tabelas obtido representa a estrutura da informação de
um modo natural e completo.
Mas terá o mínimo de redundância possível?
A Normalização tem como objetivo avaliar a qualidade do Projeto de
Tabelas e transformá-lo (em caso de necessidade) num Projeto
(Conjunto de Tabelas) equivalente, menos redundante e mais estável.
5.
Projeto Lógico- Normalização
Processoimportante para um projeto de banco de dados;
Consiste em analisar o modelo e através de regras formais,
reestruturar possíveis tabelas e atributos, reduzindo assim
redundâncias e permitindo o crescimento do Banco de Dados
com o mínimo de efeito colateral.
Consiste em diminuir redundâncias e anomalias de inserção,
atualização e deleção.
6.
Normalização
• Consiste emanalisar relações para satisfazer requisitos cada vez
mais rigorosos acarretando agrupamentos cada vez melhores,
mais estáveis e seguros
• Realiza-se uma série de testes para certificar se a relação está ou
não em uma determinada forma normal. O processo consiste em
certificar e decompor.
• Fundamentado no conceito de Dependência Funcional.
7.
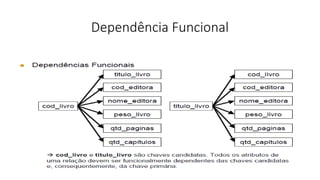
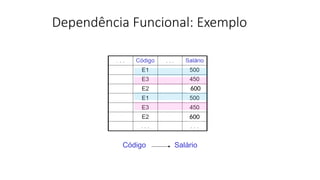
Dependência Funcional
• Correspondea uma restrição entre conjuntos de
atributos em uma relação.
• Sempre que um atributo X identifica um atributo Y,
dizemos que entre eles há uma dependência
funcional. Temos, portanto, que X é o determinante e
que Y é o dependente.
• A representação é: X->Y (lê-se X determina Y ou Y é
funcionalmente dependente de X).
8.
Dependência Funcional
E-Commerce 2019:Business, Technology and Society 15th Edition > ISBN-13 : 978-
0134998459
E-Commerce 2021: Business, Technology and Society 16th Edition > ISBN-13 : 978-
0136931805
E-Commerce 2020–2021: Business, Technology and Society, Global Edition 16th Edition > ISBN-13: 978-
Tabela de vendas(Dependência Funcional)
F# : chave primária do fornecedor
Cidade : cidade do fornecedor
P# : chave primária do produto
QDE : quantidade
F# CIDADE P# QDE
F1 Londres P1 100
F1 Londres P2 100
F2 Paris P1 200
F2 Paris P2 200
F3 Paris P2 300
F4 Londres P2 400
F4 Londres P4 400
F4 Londres P5 400
Exemplos de dependências funcionais válidas:
{ F# } → { CIDADE }
{ F#, P#} → { QDE }
{ F#, P#} → { CIDADE }
{ F#, P#} → { CIDADE, QDE }
{ F#, P#} → { F# }
{ F#, P#} → { F#, P#, CIDADE, QDE }
{ F# } → { QDE }
{ QDE } → { F# }
11.
Transitividade
A -> Be B -> C então A -> C
Exemplo:
CPF -> código-cidade e código-cidade -> nome-cidade
então CPF -> nome-cidade
Leia o exemplo acima da seguinte maneira:
Se com um número de CPF eu encontro o código da cidade de uma
pessoa, e com o código da cidade eu encontro o nome da cidade, então
com o número do CPF eu posso encontrar o nome da cidade.
12.
Transitividade
• Se umatributo X determina Y e se Y determina Z, podemos dizer que X
determina Z de forma transitiva.
• Outra leitura é: existe uma dependência funcional transitiva de X para Z.
Veja um exemplo:
• cidade -> estado
• estado -> país
cidade -> país (cidade determina país de forma transitiva)
13.
Discutir em Grupo
Identifiqueas dependências funcionais na relação abaixo:
Matrícula, nome do aluno, sexo e data de nascimento do
aluno, código, nome da disciplina e carga horária de disciplina e
a data da inscrição do aluno na disciplina.
14.
Codigo Nome TelefoneEndereço
1 Ary (34) 3821-0000
(34) 9979-0000
(34) 9964-0000
Av. Getúlio Vargas, 1000, apto 201 – Centro – Patos de Minas-MG
2 Tatiana (34) 3822-0000
(34) 9976-0000
Av. Brasil, 966 – Centro – Belo Horizonte-MG
3 Ana (11)3184-000 Rua Minas Gerais, 100 – Bairro Brasil – Recife-PE
4 João (31)3257-000 Praça da Liberdade, 27 – Bairro Esperança – São Paulo-SP
16.
Anomalias
Problema de Inserção
•Só é possível inserir um novo fornecedor quando o mesmo
solicitar peças;
• Só é possível inserir uma nova peça quando a mesma for
solicitada por um fornecedor.
Problemas de Atualização
• Para atualizar o endereço do fornecedor, todos os registros
desse fornecedor deverão ser atualizados;
• Para atualizar o preço da peça, todos os registros dessa peça
deverão ser atualizados.
Problema de Exclusão
• Caso sejam deletadas todas as solicitações de um fornecedor,
seus dados cadastrais também serão apagados.
17.
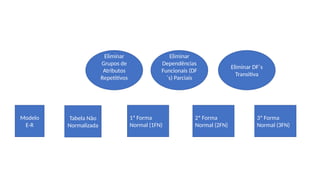
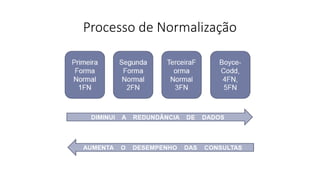
Modelo
E-R
Tabela Não
Normalizada
1ª Forma
Normal(1FN)
2ª Forma
Normal (2FN)
3ª Forma
Normal (3FN)
Eliminar
Grupos de
Atributos
Repetitivos
Eliminar
Dependências
Funcionais (DF
´s) Parciais
Eliminar DF´s
Transitiva
19.
Primeira Forma Normal
Umarelação está na primeira forma normal se todos os seus atributo são monovalorados e atômicos.
Quando encontrarmos um atributo multivalorado, deve-se criar um novo atributo que individualize a
informação que esta multivalorada:
BOLETIM = {matricula-aluno, materia, notas}
No caso acima, cada nota seria individualizada identificando a prova a qual aquela nota se refere:
BOLETIM = {matricula-aluno, materia, numero-prova, nota}
Quando encontrarmos um atributo não atômico, deve-se dividi-lo em outros atributos que sejam
atômicos:
PESSOA = {CPF, nome-completo}
Vamos supor que, para a aplicação que utilizará esta relação, o atributo nome-completo não é atômico, a
solução então será:
PESSOA = {CPF, nome, sobrenome}
20.
Primeira forma normal(1NF)
Primeira regra para eliminar as anomalias é:
• Não devem existir colunas multivaloradas.
O que é uma coluna multivalorada? É uma coluna na qual é possível armazenar-
se mais de um valor por registro. Por exemplo, imagine que você tenha na sua
tabela de clientes as colunas Codigo, Nome e Telefones, preenchidos assim:
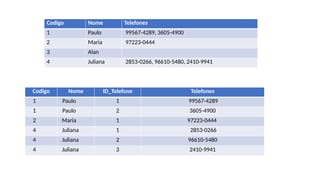
Codigo Nome Telefones
1 Paulo 99567-4289, 3605-4900
2 Maria 97223-0444
3 Alan
4 Juliana 2853-0266, 96610-5480, 2410-9941
21.
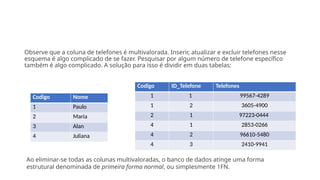
Codigo Nome ID_TelefoneTelefones
1 Paulo 1 99567-4289
1 Paulo 2 3605-4900
2 Maria 1 97223-0444
4 Juliana 1 2853-0266
4 Juliana 2 96610-5480
4 Juliana 3 2410-9941
Codigo Nome Telefones
1 Paulo 99567-4289, 3605-4900
2 Maria 97223-0444
3 Alan
4 Juliana 2853-0266, 96610-5480, 2410-9941
22.
Observe que acoluna de telefones é multivalorada. Inserir, atualizar e excluir telefones nesse
esquema é algo complicado de se fazer. Pesquisar por algum número de telefone específico
também é algo complicado. A solução para isso é dividir em duas tabelas:
Codigo Nome
1 Paulo
2 Maria
3 Alan
4 Juliana
Codigo ID_Telefone Telefones
1 1 99567-4289
1 2 3605-4900
2 1 97223-0444
4 1 2853-0266
4 2 96610-5480
4 3 2410-9941
Ao eliminar-se todas as colunas multivaloradas, o banco de dados atinge uma forma
estrutural denominada de primeira forma normal, ou simplesmente 1FN.
23.
Estrutura de DadosRelacional
Existem cinco components estruturais no modelo de dados relacional:
relação, atributo, tupla, domínio e banco de dados relacional.
• Relação > Uma tabela com colunas e linhas
• Atributo > Uma coluna identificada por um nome de uma relação
• Tupla > Uma linha de uma relação
• Domínio > O conjunto de valores possíveis de um atributo
• Banco de dados relacional > Uma coleção de tabelas normalizadas
26.
Chaves candidatas esuperchaves
Antes de prosseguir com as demais formas normais, faz-se necessário introduzir-se os
conceitos de chaves candidatas e superchaves.
• A chave primária é aquele conjunto de colunas que serve para identificar a tupla de uma
forma única (pode ser só uma coluna, ou podem ser duas ou mais). É importante que o
projetista do banco de dados saiba identificar quais são as colunas mais apropriadas
para serem eleitas como parte da chave primária.
• Entretanto, às vezes há mais do que um conjunto de colunas que poderia ser chave
primária. Cada um desses conjuntos é chamado de chave candidata. Por exemplo, em
uma tabela Pessoa que tenha os campos CPF, RG, Estado e Nome, tanto o CPF quanto o
RG junto com o Estado são chaves candidatas. Assim, é possível chegar-se ao Nome a
partir do CPF, mas também é possível chegar-se ao Nome a partir do RG e do Estado.
• Qualquer conjunto de colunas que tenha como subconjunto, uma chave candidata é
denominado de superchave.
27.
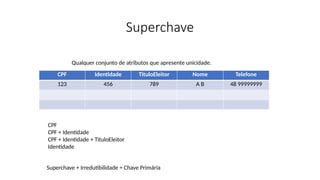
Superchave
CPF Identidade TituloEleitorNome Telefone
123 456 789 A B 48 99999999
Qualquer conjunto de atributos que apresente unicidade.
CPF
CPF + Identidade
CPF + Identidade + TituloEleitor
Identidade
Superchave + Irredutibilidade = Chave Primária
29.
Segunda forma normal(2FN)
A segunda forma normal é aquela que diz que:
• Todas as colunas devem ter dependência funcional com a totalidade
de cada chave candidata.
Na maioria dos casos por “cada chave candidata“, entenda-se por “com
a chave primária“, exceto se houver mais do que uma chave candidata.
Além disso, para que uma tabela esteja na segunda forma normal, ela
deve estar antes de tudo, na primeira forma normal.
30.
Uma coluna estáem dependência funcional com a chave primária
quando ela é determinada no domínio da aplicação por meio da chave
primária. Uma coluna não tem dependência funcional com a chave
primária quando ela é definida de forma independente da chave
primária ou quando ela é definida a partir de alguma outra coluna que
não seja a chave primária.
Uma dependência funcional pode ser dita estar na totalidade da chave
primária quando todos os campos da chave primária são necessários
para estabelecer-se a relação de dependência. No caso de a chave
primária ser composta, é possível se ter uma dependência parcial.
31.
Para dar umexemplo da 2FN, imagine que sua empresa tenha
representantes comerciais atuando em clientes e queira representar a
relação de quais representantes comerciais atuam em quais clientes.
Nessa tabela (vamos chamar de representação), temos as colunas
ID_Cliente e ID_Rep como chaves primárias e temos também as
colunas Nome_Cliente, Nome_Rep, Endereço_Rep, Endereço_Cliente e
Valor_Contrato.
32.
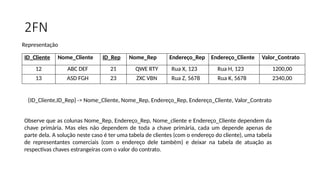
2FN
ID_Cliente Nome_Cliente ID_RepNome_Rep Endereço_Rep Endereço_Cliente Valor_Contrato
12 ABC DEF 21 QWE RTY Rua X, 123 Rua H, 123 1200,00
13 ASD FGH 23 ZXC VBN Rua Z, 5678 Rua K, 5678 2340,00
Representação
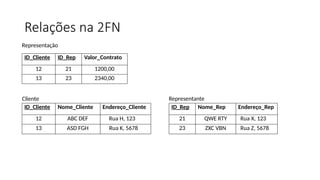
Observe que as colunas Nome_Rep, Endereço_Rep, Nome_cliente e Endereço_Cliente dependem da
chave primária. Mas eles não dependem de toda a chave primária, cada um depende apenas de
parte dela. A solução neste caso é ter uma tabela de clientes (com o endereço do cliente), uma tabela
de representantes comerciais (com o endereço dele também) e deixar na tabela de atuação as
respectivas chaves estrangeiras com o valor do contrato.
{ID_Cliente,ID_Rep} -> Nome_Cliente, Nome_Rep, Endereço_Rep, Endereço_Cliente, Valor_Contrato
Terceira forma normal(3FN)
A terceira forma normal é aquela que diz que:
• Todas as colunas devem ter dependência funcional com a totalidade
de cada chave candidata e nada mais além do que essas chaves
candidatas.
Novamente, na maioria dos casos por “cada chave candidata“, entenda-se por “com a
chave primária“, exceto se houver mais do que uma chave candidata. Se a única
chave candidata existente for a chave primária, isso ficaria assim:
Todas as colunas devem ter dependência funcional com a totalidade da chave
primária e nada mais além da chave primária.
Além disso, para uma tabela estar na terceira forma normal, ela deve estar
primeiramente na segunda forma normal (e também na primeira). A parte de
depender da totalidade de cada chave candidata é abordada na segunda forma
normal, então o foco aqui é depender de nada mais que essas chaves.
35.
Por exemplo. Imaginea tabela de carros com as colunas placa (chave
primária), cor, nome_proprietário, endereço_proprietário:
placa cor nome_proprietário endereço_proprietário
ABX-1234 Azul José Rua X, 123
NNU-5566 Verde Marcos Rua exemplo, 5678
SGH-7210 Preto Maria Avenida teste, 7743
ERT-6902 Vermelho José Rua X, 123
BGH-5431 Preto José Rua X, 123
placa -> endereço_proprietário (placa determina endereço_proprietário de forma transitiva)
36.
Observe o endereçodo proprietário – ele é uma violação da terceira
forma normal.
Observe que o endereço do proprietário é definido como resultado de
quem é o proprietário, e não como consequência da placa do carro.
Se o José mudar de endereço e atualizarmos o endereço de apenas um
dos carros dele, o banco de dados ficará inconsistente (há anomalia de
alteração). Se a Maria comprar mais um novo carro e adicionarmos
com um outro endereço, também ficará inconsistente (anomalia de
inserção).
37.
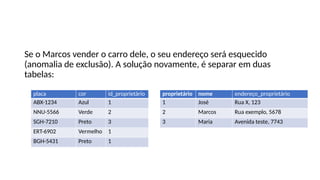
Se o Marcosvender o carro dele, o seu endereço será esquecido
(anomalia de exclusão). A solução novamente, é separar em duas
tabelas:
placa cor id_proprietário
ABX-1234 Azul 1
NNU-5566 Verde 2
SGH-7210 Preto 3
ERT-6902 Vermelho 1
BGH-5431 Preto 1
proprietário nome endereço_proprietário
1 José Rua X, 123
2 Marcos Rua exemplo, 5678
3 Maria Avenida teste, 7743
38.
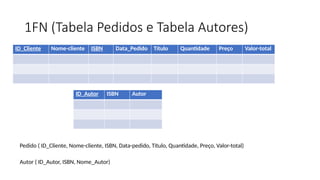
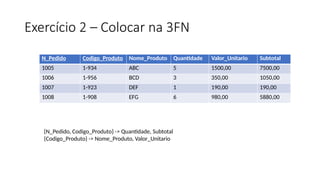
Exercício 1 –Colocar na 3FN
Pedido ( ID_Cliente,Nome-cliente, ISBN, Data-pedido, Título, Autor(es),
Quantidade, Preço, Valor-total)
ID_Cliente Nome-cliente ISBN Data_Pedido Título Autor(es) Quantidade Preço Valor-total
NN -> 1FN (Agrupamentos e Multivalorados)
1FN -> 2FN (Sem Dependência Funcional Parcial)
39.
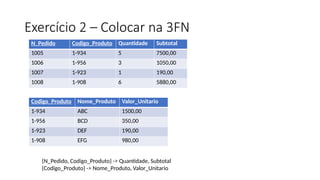
1FN (Tabela Pedidose Tabela Autores)
ID_Cliente Nome-cliente ISBN Data_Pedido Título Quantidade Preço Valor-total
ID_Autor ISBN Autor
Pedido ( ID_Cliente, Nome-cliente, ISBN, Data-pedido, Título, Quantidade, Preço, Valor-total)
Autor ( ID_Autor, ISBN, Nome_Autor)
40.
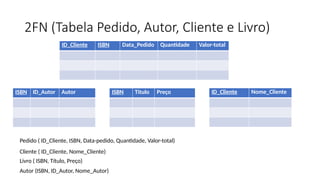
2FN (Tabela Pedido,Autor, Cliente e Livro)
ID_Cliente ISBN Data_Pedido Quantidade Valor-total
ISBN ID_Autor Autor
Pedido ( ID_Cliente, ISBN, Data-pedido, Quantidade, Valor-total)
Autor (ISBN, ID_Autor, Nome_Autor)
Livro ( ISBN, Título, Preço)
Cliente ( ID_Cliente, Nome_Cliente)
ID_Cliente Nome_Cliente
ISBN Titulo Preço
41.
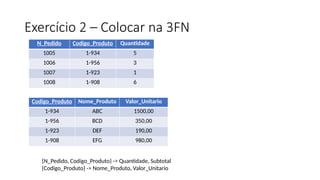
3FN (Tabela Pedido,Autor, Cliente e Livro)
ID_Cliente ISBN Data_Pedido Quantidade
ISBN ID_Autor Autor
Pedido ( ID_Cliente, ISBN, Data-pedido, Quantidade)
Autor (ISBN, ID_Autor, Nome_Autor)
Livro ( ISBN, Título, Preço)
Cliente ( ID_Cliente, Nome_Cliente)
ID_Cliente Nome_Cliente
ISBN Titulo Preço
• O Subtotaldepende da multiplicação de Quant por Valor_unit, desta
forma a coluna Subtotal depende de outras colunas não-chave.
• Para levar esta coluna para a 3FN devemos eliminar a coluna Subtotal.
46.
Normalizar para a3FN
Matricula NomeFuncionario CodCargo NomeCargo DescCargo SalarioCargo
1 Ana Cintra 1 Professor Professor Universitário 7500
2 Carla Mendes 2 Advogado Apoio Legal 6500
3 Angela Ribeiro 3 Secretaria Apoio Administrativo 1550
4 Rodrigo Reno 1 Professor Professor Universitário 7500
47.
Observamos que nestatabela existe a seguinte
dependência: CodCargo => NomeCargo, DescCargo,
SalarioCargo.
Perceba que CodCargo não é chave primária e os
atributos CargoNome, DescCargo e SalarioCargo
estão dependendo dele, ou seja, existe uma
dependência funcional transitiva.
48.
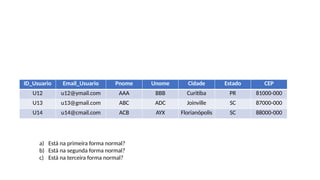
ID_Usuario Email_Usuario PnomeUnome Cidade Estado CEP
U12 u12@ymail.com AAA BBB Curitiba PR 81000-000
U13 u13@gmail.com ABC ADC Joinville SC 87000-000
U14 u14@cmail.com ACB AYX Florianópolis SC 88000-000
a) Está na primeira forma normal?
b) Está na segunda forma normal?
c) Está na terceira forma normal?
49.
49
Formais Normais
• PrimeiraForma Normal (1NF)
• Segunda Forma Normal (2NF)
• Terceira Forma Normal (3NF)
• Forma Norma Boyce/Codd (BCNF)
• Quarta Forma Normal (4NF)
• Quinta Forma Normal (5NF ou PJNF)
DF Total eDF Parcial
• DF Parcial
• um atributo depende funcionalmente de parte da chave composta de
uma tabela OU
• Parte da chave composta identifica um ou mais atributos da tabela
• DF Total
• um atributo depende funcionalmente de todos os atributos da chave
composta de uma tabela
• A chave composta completa identifica um ou mais atributos da tabela
53.
DF Total eDF Parcial
• DF Parcial
ProjetoEmpregado (codProj, tipo, descr, #codDepto, codEmp, nome, categ, sal, dataIni, tempoAl)
• DF Total
ProjetoEmpregado (codProj, tipo, descr, #codDepto, codEmp, nome, categ, sal, dataIni, tempoAl)
codEmp (parte da chave) – identifica o empregado, a categoria e seu salario
codProj (parte da chave) – identifica o projeto, o tipo, a descr e o depto
codProj e codEmp (chave completa)– identificam a data de inicio e o tempo
no qual o empregado atua no projeto
54.
2ª Forma Normal(2FN)
• “Uma tabela está na 2FN se e somente se ela estiver na
1FN e não possuir Dependência Funcional Parcial (DF)
• tabelas com DFs parciais devem ser desmembradas em
tabelas com DFs totais
• Tabelas cuja PK possui apenas um atributo estão
automaticamente na 2FN
55.
2ª Forma Normal(2FN)
1FN:
Departamento (codDepto, nome)
ProjetoEmpregado (codProj, tipo, descr, #codDepto, codEmp, nome, categ, sal, dataIni, tempoAl)
2FN:
• Departamento (codDepto, nome)
• Projeto (codProj, tipo, descr, #codDepto )
• ProjetoEmpregado (#codProj, #codEmp, dataIni, tempoAl)
• Empregado (codEmp, nome, categ, sal)
56.
Dependência Funcional Transitiva
Seum atributo não-chave possui DF total de um atributo chave e também
possui DF total de um ou mais atributos não-chave, então diz-se que existe
uma DF transitiva ou indireta da CP.
Empregado (codEmp, nome, categ, sal)
57.
3 ª FormaNormal (3FN)
“Uma tabela está na 3FN se e somente se ela estiver na
2FN e não possuir DFs indiretas”
– tabelas com DFs indiretas devem ser
desmembradas em tabelas que não possuem tais Dfs
Tabelas que possuem apenas um atributo que não faz
parte da PK estão automaticamente na 3FN
• What isthe cardinality and existence of each of the following
relationships in just the direction given? State any assumptions you
have to make.
• Husband to wife
• Student to degree
• Child to parent
• Player to team
• Student to course
61.
For each ofthe following pairs of rules, identify two entity types and one relationship. State the
cardinality and existence of the relationship in each case. If you don't think enough information is
available to define either of these, then state an assumption that makes it clear. Draw the ER diagram.
• A department employs many persons. A person is employed by, at most, one department.
• A manager manages, at most, one department. A department is managed by, at most, one manager.
• An author may write many books. A book may be written by many authors.
• A team consists of many players. A player plays for only one team.
• A lecturer teaches, at most, one course. A course is taught by exactly one lecturer.
• A flight-leg connects two airports. An airport is used by many flight-legs.
• A purchase order may be for many products. A product may appear on many purchase orders.
• A customer may submit many orders. An order is for exactly one customer
62.
Draw an ERdiagram for the following. Be sure to indicate the existence and cardinality
for each relationship.
• A college runs many classes. Each class may be taught by several teachers, and a
teacher may teach several classes. A particular class always uses the same room.
Because classes may meet at different times or on different evenings, it is possible for
different classes to use the same room.
• Each employee in an engineering company has at most one recognized skill, but a
given skill may be possessed by several employees. An employee is able to operate a
given machine-type (e.g., lathe, grinder) if he has one of several skills, but each skill is
associated with the operation of only one machine type. Possession of a given skill
(e.g., mechanic, electrician) allows an employee to maintain several machine-types,
although maintenance of any given machine-type requires a specific skill (e.g., a lathe
must be maintained by a mechanic).
63.
Draw an ERdiagram for each of the following situations. On the diagram be sure to identify the
cardinality, existence, and optionality (for subtypes) of each relationship.
• A company has a number of employees. Each employee may be assigned to one or more projects,
or may not be assigned to a project. A project must have at least one employee assigned, and
may have several employees assigned.
• A university has a large number of courses in its catalog. Each course may have one or more other
courses as prerequisistes, or may have no prerequisites.
• A college course may have one or more scheduled sections, or may not have a scheduled section.
• A hospital patient has a patient history. Each patient has one or more history records (we assume
that the initial patient visit is always recorded as an instance of the history). Each patient history
record belongs to exactly one patient.
• A video store may stock more than one copy of a given movie. It is also true that the store may
not have a single copy of a paticular movie.
64.
For each ofthe following sets of sentences, draw the corresponding ER
diagram.
1.An account can be charged against many projects, though it may not be
charged against any. A project must have at least one, though it may have
many, accounts charged against it.
2.Projects must be classified as either top secret or civilian (but not both).
There is information specific to top secret projects and specific to civilian
projects that we want to record.
3.An employee must manage exactly one department. A department may or
may not have one employee manage it.
4.Men are only allowed to supervise men. Women are only allowed to supervise
women. We do not want to allow the database to hold data representing a man
supervising a woman. An employee, regardless of sex, is assigned to exactly
one office, with each office having exactly one employee in it. (Be sure to
include the office entity in this diagram.)
65.
• The followingdescriptions all have to do with a holding company for food service companies. You should answer each
one separately from the others.
• Each chain consists of 50 to 300 stores that are owned by ACTME, the holding company for several restaurant chains
and two caterers.
• Menu items are wide ranging, and can be classified by the section of the menu (appetizer, dessert, etc.) in which each is
presented and by ethnic group (Italian, Hungarian, etc.) to which it belongs.
• The menu of each restaurant changes every couple months; management likes to keep track of past menus to track
which ones have been successful.
• Each menu item is made of several ingredients (eggs, bacon, etc.) that are used in a certain quantity.
• Ingredients can be acquired from several suppliers. Ingredients are acquired by sending orders for several goods using
the vendor's item numbers. The item number for each of these ingredients varies across suppliers, so if you are going
to order eggs from supplier # 1, then you might order item 52 while from supplier # 2 you might order item J216. The
company keeps price and item numbers for all the ingredients for all its menu items — and even for some ingredients
which it is not currently using in any menu items. The quantity needed for each ingredient is also kept. The current
price of these goods is maintained though the historical price is not. Because of special deals and volume discounts, the
price at which a good is acquired is often different from its list price. Thus, the database must retain the price at which
a good is actually acquired.
66.
Create a setof normalized relations given the bill shown below.
67.
A naive databasedesigner implemented a resume database to keep track of information about
a student, including information about his or her job, classes he or she has taken, and
organizations he or she has been involved with. (Oops. Ending a sentence with a proposition is
something up with which I will not put.) It has the following fields.
student-id
The student's id
name
name of the student
ssn
student's social security #
work-address
street address where the student currently works
work-city
city where the student currently works
work-state
state where the student works
work-zip
<FONT SIZE="-1">zip</FONT> code where the student works
class
id of a class the student has taken
org
id of an organization in which the student is involved
The student has come to you because he has noticed that he has typed in lots of information
multiple times, he also has to leave lots of fields blank, and he types multiple values into
several fields. Put this database into 4NF and remove any conditional dependencies. Assume
that the student can have only one job (although he or she may not work at all) but has
taken many (or no) classes and could, potentially, have been in many (or no) organizations.
Assume that the student works in the United States. Assume that the student could be from the
United States or not.
68.
• Question P.7
•The following are sample problems which you can use to practice your ER modeling skills. Draw the ER diagram, determine tables that are needed, determine the primary key for each table, and
determine some of the attributes of each table. After doing this problem using your normalization skills, you should also attempt it by using your ER modelling skills. Then compare the answers you get
from the two approaches. You might want to work on these problems individually, get together in groups to discuss them, and then come by my office en masse to discuss your problems.
• Problem 1
• An employment agency offers a service in which the skills of prospective applicants are matched against the skills, or combination of skills, required for available jobs. Similar types of jobs may be
offered by a number of employers, and any employer may offer more than one job. Each job is given a unique job number when it is entered into the system, and, in addition to the title of the job, a
range of salaries and the length of time for which the job is available are recorded. Applicants are given unique applicant numbers, and a brief job history may be recorded giving job titles, salaries and
dates, in addition to name, address, and age. The information on jobs and applicants is to be recorded in a database, together with the date(s), if any, on which a particular applicant is matched to a
particular job, and whether or not the match is successful (i.e., whether or not the applicant actually gets the job).
• Problem 2
• A company records information on its fleet of vehicles and the employees who are permitted to drive them. The database is used by three groups of people: the department managers, the finance
division, and the service department.
• For the department managers, each vehicle has a unique registration number and each driver a unique employee number. Drivers may be authorized to drive a number of vehicles, and any vehicle may
be used by a number of drivers. Vehicles are allocated to departments within the company, although they may be used by drivers in other departments. Some classes of vehicle require specialist driver
qualifications. There are occasional accidents which may lead to the vehicle being written off and/or the driver being disqualified from driving some or all classes of vehicle.
• For the finance division, each vehicle, identified again by registration number, has a current and a replacement value, must be taxed on a certain date, and was bought on a certain date. For accounting
purposes, the allocation of vehicles to departments is also required. Finally, details are recorded of any insurance claims associated with accidents, or repair costs if no insurance claim arose.
• The service department is responsible for giving regular services to each vehicle. There are different types of service corresponding to different mileage values for each class of vehicle, with a short
description documenting each type of service. Where vehicles have been involved in accidents, details of repairs effected are recorded.
• Problem 3
• A university research group publishes an analysis of all journal papers relating to a particular area of chemistry, namely reaction kinetics. Each paper may have one or more authors, and may discuss one
or more reactions, but may appear in only one journal. Journals are identified by title, volume, and issue number. Each issue contains many papers. Each paper contains a series of references to other
papers. Authors can, and usually do, contribute to a large number of papers appearing in a variety of journals.
• In order to reduce the work involved in preparing their analysis, the research group wishes to store sufficient information on a computer to answer queries including the following: 1)~Which authors
have written one or more papers which discuss a particular reaction? 2)~Which papers either discuss a particular reaction, or have been referred to by a paper which discusses that reaction?
69.
Best selling books
BookstoreLocation Store's best seller
Border's AA How to train a dog
Border's Philadelphia Fly like a turkey
Little Professor AA How to train a dog
Is the table below in 2NF? Why or why not? If it is not, create tables in 2NF.
70.
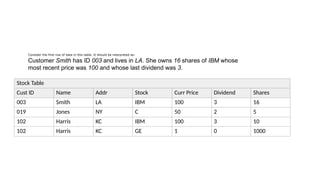
Stock Table
Cust IDName Addr Stock Curr Price Dividend Shares
003 Smith LA IBM 100 3 16
019 Jones NY C 50 2 5
102 Harris KC IBM 100 3 10
102 Harris KC GE 1 0 1000
Consider the first row of data in this table. It should be interpreted as:
Customer Smith has ID 003 and lives in LA. She owns 16 shares of IBM whose
most recent price was 100 and whose last dividend was 3.
71.
Another way ofthinking about what information this table really contains is to determine how you can uniquely identify
a particular row of the table, not by using the row number, but by referring to the data itself. For example, if you could use Cust ID to
uniquely identify a row in the Stock table, then you would say that this table contains information about customers. Why can you say
this? Let's look into this point for a minute.
Consider the Stock column. IBM appears on two different rows. Why? Well, two different customers own that stock. So, is this table
about stocks? That is, does each line of the table tell us information related to just that particular stock? Not exactly. On the other
hand, if the table never contained two rows with the same stock on it, then it would seem that each row must contain something
uniquely associated with that particular stock, wouldn't it?
Two attributes that, when taken together, can uniquely identify any row in the Stock table are [cust id, stock]. Attributes that can
perform this function are referred to as the primary identifier of a relation. (These are really important when thinking about database
design; we'll study these in much greater depth later.) There are many problems with this table but they can be classified into
three types of anomalies. The process of normalizing a database helps us avoid these anomalies.
72.
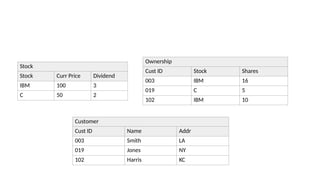
Stock
Stock Curr PriceDividend
IBM 100 3
C 50 2
Ownership
Cust ID Stock Shares
003 IBM 16
019 C 5
102 IBM 10
Customer
Cust ID Name Addr
003 Smith LA
019 Jones NY
102 Harris KC
73.
Product # NameMfr Mfr HQ
1001 Walkman Sony Japan
1002 Camera Leica Germany
1003 DVD Sony Japan
When tables are in 2NF but not in 3NF, the solution is to split up offending tables into two (or more) new tables. Consider the table below.
The functional dependencies here include
•Product # —> Mfr
•Mfr —> Mfr HQ
So, by transitivity we have
Product # —> Mfr HQ
74.
Consider the productand manufacturer table above. We found that Mfr HQ depends on Mfr. We already know that Mfr is not part of the primary identifier … so we have one
dependency of the form Mfr —> Mfr HQ. Thus, we should create another relation containing Mfr and Mfr HQ. The primary identifier of this table is Mfr. Finally, we need to
remove Mfr HQ from the 2NF relation. Thus, the above single relation is replaced by the following two relations:
•Product # —> [Name, Mfr]
•Mfr —> Mfr HQ
The following is another way of representing the above relations:
•Product(Product #, Name, Mfr)
•Company(Mfr, Mfr HQ)
The form of this is tableName(field1, field2,{…)} and the underlined field is the primary identifier of the relation. These are called the table structures.
75.
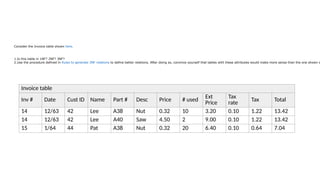
Invoice table
Inv #Date Cust ID Name Part # Desc Price # used
Ext
Price
Tax
rate
Tax Total
14 12/63 42 Lee A38 Nut 0.32 10 3.20 0.10 1.22 13.42
14 12/63 42 Lee A40 Saw 4.50 2 9.00 0.10 1.22 13.42
15 1/64 44 Pat A38 Nut 0.32 20 6.40 0.10 0.64 7.04
Consider the Invoice table shown here.
1.Is this table in 1NF? 2NF? 3NF?
2.Use the procedure defined in Rules to generate 3NF relations to define better relations. After doing so, convince yourself that tables with these attributes would make more sense than the one shown a
76.
Step 1
The Invoicetable as shown [#tab:invoice-example above] is not in 1NF because of the attributes containing derived values. Ext Price is calculated by multiplying Price by #
used. Tax is calculated by multiplying the total of all the Ext Prices for a particular invoice by the Tax rate. Total is calculated by adding Tax to the total of all the Ext Prices for a
particular invoice. Thus, Ext Price, Tax, and Total all contain derived data; therefore, the Invoice table is not in 1NF (and, therefore, not in 2NF or 3NF).
Step 2
Now, let's go through the procedure to define 3NF relations. Each attribute is already single-valued. As pointed out above, there are three attributes containing derived values.
Drop these attributes. There are not any repeating groups. The primary identifier is [Inv #, Part #]}. Thus, the 1NF relation is
[Inv #, Part #] —> [Date, Cust ID, Name, Desc, Price, Tax rate, # used]
I would remove the following relations from the 1NF relation since each depends on only part of the primary identifier:
•Inv # —> [Date, Cust ID, Name, Tax rate]
•Part # —> [Desc, Price]
The original relation is now [Inv #, Part #] —> # used.
Now you look for some attribute(s) on the right side of the above relations that determines some other attribute(s) on the right side of the same relation. The Name attribute is
functionally determined by the Cust ID attribute — and the Cust ID attribute is not part of the primary identifier. Thus we have a problem here with a transitive dependency. This
is the only attribute dependent on an attribute other than the primary identifier. Create a new relation showing this dependency and drop the Name attribute from the relation
with Inv # as the primary identifier. We are left with the following relations:
•Inv # —> [Date, Cust ID, Tax rate]
•Part # —> [Desc, Price]
•Cust ID —> Name
•Inv #, Part # —> # used
These four relations are in 3NF.
77.
Journal title VolumePublisher Pages
AI Expert 172 Miller Freeman 106
CACM 146
Assoc Computing
Machinery 152
AI Expert 173 Miller Freeman 132
Consider this table:
Is this table in 1NF? 2NF? 3NF? Justify your answer and fix any problem.
78.
The table isin 1NF since it has no repeating groups, all single-valued attributes, and no derived data. The primary identifier is [Journal title, Volume]. It is not in 2NF since
Journal title —> Publisher
but Journal title is not the complete identifier. Thus we have to repeatedly specify that Miller Freeman publishes AI Expert. This is a transitive dependency problem. We fix this
by replacing the above relation with the following:
•[Journal title, Volume] —> Pages
•Journal title —> Publisher
Make sure that you could
•Appropriately fill these tables with data
•See what functional dependencies they contain
•See we have reached 2NF.
There are no transitive dependencies, so we are in 3NF.
One quick way to tell that you don't have transitive dependencies: if the relation has one or fewer attributes on the right side of the arrow, then it can't have a transitive
dependency. How would it? One attribute on the right-hand-side has to be determined by another attribute on the right-hand-side. If there aren't at least two, then this can't
happen.
79.
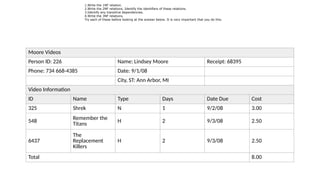
Moore Videos
Person ID:226 Name: Lindsey Moore Receipt: 68395
Phone: 734 668-4385 Date: 9/1/08
City, ST: Ann Arbor, MI
Video Information
ID Name Type Days Date Due Cost
325 Shrek N 1 9/2/08 3.00
548
Remember the
Titans
H 2 9/3/08 2.50
6437
The
Replacement
Killers
H 2 9/3/08 2.50
Total 8.00
1.Write the 1NF relation.
2.Write the 2NF relations. Identify the identifiers of these relations.
3.Identify any transitive dependencies.
4.Write the 3NF relations.
Try each of these before looking at the answer below. It is very important that you do this.
80.
Write the 1NFrelation.
The attributes are as follows:
Receipt, Date, PID, PName, Phone, City, State, VID, VName, Type, Days, Date Due, Cost, Total
Derived data
Date Due can be calculated from Date and Days. Total can be calculated as the total of the Cost attribute. Remove these from the relation.
Repeating groups
None.
Multi-value attributes
City and State should be separated into separate attributes.
Primary identifier
This is [Receipt, VID].
Now the list of attributes is
Receipt, Date, PID, PName, Phone, City, State, VID, VName, Type, Days, Cost
and the 1NF relation is
[Receipt, VID] —> [Date, PID, PName, Phone, City, State, VName, Type, Days, Cost]
Write the 2NF relations.
Now we're looking for all attributes that are dependent on only part of the primary identifier. I propose that the following are true:
•Receipt —> Date: If you know the receipt, you know what date the receipt was issued. Or, equivalently, given a certain receipt, there is only one date on which that receipt was
issued.
•Receipt —> [PID, PName, Phone, City, State]: If you know the receipt, you know information about the person. Or, alternatively, there is only one person associated with any one
receipt.
•VID —> [VName, Type, Days, Cost]: If you know the video id, you know information about the video.
After removing the attributes from the right side of the above relations from the original relation, this leaves the original relation as follows:
Receipt, VID
There aren't any attributes on the right side of the arrow in the above relation, so the primary identifier for this relation consists of both attributes.
Grouping together the first and second relations since they have the same identifier, we now have:
•Receipt —> [Date, PID, PName, Phone, City, State]
•VID —> [VName, Type, Days, Cost]
•Receipt, VID
The identifier for the first relation is Receipt; for the second is VID; for the third is [Receipt, VID]. Since the relations are in 1NF and there is nothing on the right side of the only
relation that has a multi-attribute identifier (the third relation), we are in 2NF.
Identify any transitive dependencies.
What you are looking for here are attributes on the right side of the above relations that depend on other attributes on the right side. I propose that the following are true:
•PID —> [PName, Phone, City, State]
•Type —> [Days, Cost]
Write the 3NF relations.
To get to 3NF, remove the transitive dependencies from the 2NF relations. After doing so, the relations are as follows:
•Receipt —> [Date, PID]
•PID —> [PName, Phone, City, State]
•VID —> [VName, Type]
•Type —> [Days, Cost]
•Receipt, VID
Q&A with student
How come type —> [Days, cost] is valid as 3NF? Couldn't we use days to determine cost as well?
I defined the determinancy this way because of the way I thought of the situation. I thought of type as classifying the videos. Then, once you know the type of a video, you know
how many days it can be rented and how much it costs to rent. Different types of videos can have different combinations of values for days and cost. A D type video (I'm making


















































![Another way of thinking about what information this table really contains is to determine how you can uniquely identify
a particular row of the table, not by using the row number, but by referring to the data itself. For example, if you could use Cust ID to
uniquely identify a row in the Stock table, then you would say that this table contains information about customers. Why can you say
this? Let's look into this point for a minute.
Consider the Stock column. IBM appears on two different rows. Why? Well, two different customers own that stock. So, is this table
about stocks? That is, does each line of the table tell us information related to just that particular stock? Not exactly. On the other
hand, if the table never contained two rows with the same stock on it, then it would seem that each row must contain something
uniquely associated with that particular stock, wouldn't it?
Two attributes that, when taken together, can uniquely identify any row in the Stock table are [cust id, stock]. Attributes that can
perform this function are referred to as the primary identifier of a relation. (These are really important when thinking about database
design; we'll study these in much greater depth later.) There are many problems with this table but they can be classified into
three types of anomalies. The process of normalizing a database helps us avoid these anomalies.](https://image.slidesharecdn.com/normalizao-250425200356-8db532c7/85/Normalizacao-de-Tabelas-ate-Terceira-Forma-Normal-71-320.jpg)

![Consider the product and manufacturer table above. We found that Mfr HQ depends on Mfr. We already know that Mfr is not part of the primary identifier … so we have one
dependency of the form Mfr —> Mfr HQ. Thus, we should create another relation containing Mfr and Mfr HQ. The primary identifier of this table is Mfr. Finally, we need to
remove Mfr HQ from the 2NF relation. Thus, the above single relation is replaced by the following two relations:
•Product # —> [Name, Mfr]
•Mfr —> Mfr HQ
The following is another way of representing the above relations:
•Product(Product #, Name, Mfr)
•Company(Mfr, Mfr HQ)
The form of this is tableName(field1, field2,{…)} and the underlined field is the primary identifier of the relation. These are called the table structures.](https://image.slidesharecdn.com/normalizao-250425200356-8db532c7/85/Normalizacao-de-Tabelas-ate-Terceira-Forma-Normal-74-320.jpg)
![Step 1
The Invoice table as shown [#tab:invoice-example above] is not in 1NF because of the attributes containing derived values. Ext Price is calculated by multiplying Price by #
used. Tax is calculated by multiplying the total of all the Ext Prices for a particular invoice by the Tax rate. Total is calculated by adding Tax to the total of all the Ext Prices for a
particular invoice. Thus, Ext Price, Tax, and Total all contain derived data; therefore, the Invoice table is not in 1NF (and, therefore, not in 2NF or 3NF).
Step 2
Now, let's go through the procedure to define 3NF relations. Each attribute is already single-valued. As pointed out above, there are three attributes containing derived values.
Drop these attributes. There are not any repeating groups. The primary identifier is [Inv #, Part #]}. Thus, the 1NF relation is
[Inv #, Part #] —> [Date, Cust ID, Name, Desc, Price, Tax rate, # used]
I would remove the following relations from the 1NF relation since each depends on only part of the primary identifier:
•Inv # —> [Date, Cust ID, Name, Tax rate]
•Part # —> [Desc, Price]
The original relation is now [Inv #, Part #] —> # used.
Now you look for some attribute(s) on the right side of the above relations that determines some other attribute(s) on the right side of the same relation. The Name attribute is
functionally determined by the Cust ID attribute — and the Cust ID attribute is not part of the primary identifier. Thus we have a problem here with a transitive dependency. This
is the only attribute dependent on an attribute other than the primary identifier. Create a new relation showing this dependency and drop the Name attribute from the relation
with Inv # as the primary identifier. We are left with the following relations:
•Inv # —> [Date, Cust ID, Tax rate]
•Part # —> [Desc, Price]
•Cust ID —> Name
•Inv #, Part # —> # used
These four relations are in 3NF.](https://image.slidesharecdn.com/normalizao-250425200356-8db532c7/85/Normalizacao-de-Tabelas-ate-Terceira-Forma-Normal-76-320.jpg)

![The table is in 1NF since it has no repeating groups, all single-valued attributes, and no derived data. The primary identifier is [Journal title, Volume]. It is not in 2NF since
Journal title —> Publisher
but Journal title is not the complete identifier. Thus we have to repeatedly specify that Miller Freeman publishes AI Expert. This is a transitive dependency problem. We fix this
by replacing the above relation with the following:
•[Journal title, Volume] —> Pages
•Journal title —> Publisher
Make sure that you could
•Appropriately fill these tables with data
•See what functional dependencies they contain
•See we have reached 2NF.
There are no transitive dependencies, so we are in 3NF.
One quick way to tell that you don't have transitive dependencies: if the relation has one or fewer attributes on the right side of the arrow, then it can't have a transitive
dependency. How would it? One attribute on the right-hand-side has to be determined by another attribute on the right-hand-side. If there aren't at least two, then this can't
happen.](https://image.slidesharecdn.com/normalizao-250425200356-8db532c7/85/Normalizacao-de-Tabelas-ate-Terceira-Forma-Normal-78-320.jpg)
![Write the 1NF relation.
The attributes are as follows:
Receipt, Date, PID, PName, Phone, City, State, VID, VName, Type, Days, Date Due, Cost, Total
Derived data
Date Due can be calculated from Date and Days. Total can be calculated as the total of the Cost attribute. Remove these from the relation.
Repeating groups
None.
Multi-value attributes
City and State should be separated into separate attributes.
Primary identifier
This is [Receipt, VID].
Now the list of attributes is
Receipt, Date, PID, PName, Phone, City, State, VID, VName, Type, Days, Cost
and the 1NF relation is
[Receipt, VID] —> [Date, PID, PName, Phone, City, State, VName, Type, Days, Cost]
Write the 2NF relations.
Now we're looking for all attributes that are dependent on only part of the primary identifier. I propose that the following are true:
•Receipt —> Date: If you know the receipt, you know what date the receipt was issued. Or, equivalently, given a certain receipt, there is only one date on which that receipt was
issued.
•Receipt —> [PID, PName, Phone, City, State]: If you know the receipt, you know information about the person. Or, alternatively, there is only one person associated with any one
receipt.
•VID —> [VName, Type, Days, Cost]: If you know the video id, you know information about the video.
After removing the attributes from the right side of the above relations from the original relation, this leaves the original relation as follows:
Receipt, VID
There aren't any attributes on the right side of the arrow in the above relation, so the primary identifier for this relation consists of both attributes.
Grouping together the first and second relations since they have the same identifier, we now have:
•Receipt —> [Date, PID, PName, Phone, City, State]
•VID —> [VName, Type, Days, Cost]
•Receipt, VID
The identifier for the first relation is Receipt; for the second is VID; for the third is [Receipt, VID]. Since the relations are in 1NF and there is nothing on the right side of the only
relation that has a multi-attribute identifier (the third relation), we are in 2NF.
Identify any transitive dependencies.
What you are looking for here are attributes on the right side of the above relations that depend on other attributes on the right side. I propose that the following are true:
•PID —> [PName, Phone, City, State]
•Type —> [Days, Cost]
Write the 3NF relations.
To get to 3NF, remove the transitive dependencies from the 2NF relations. After doing so, the relations are as follows:
•Receipt —> [Date, PID]
•PID —> [PName, Phone, City, State]
•VID —> [VName, Type]
•Type —> [Days, Cost]
•Receipt, VID
Q&A with student
How come type —> [Days, cost] is valid as 3NF? Couldn't we use days to determine cost as well?
I defined the determinancy this way because of the way I thought of the situation. I thought of type as classifying the videos. Then, once you know the type of a video, you know
how many days it can be rented and how much it costs to rent. Different types of videos can have different combinations of values for days and cost. A D type video (I'm making](https://image.slidesharecdn.com/normalizao-250425200356-8db532c7/85/Normalizacao-de-Tabelas-ate-Terceira-Forma-Normal-80-320.jpg)
















































