Este documento apresenta a implementação do algoritmo de exclusão mútua distribuída de Lamport usando o framework Neko. O autor implementou o algoritmo em Java com classes que representam cada processo e a troca de mensagens entre eles. Ele também desenvolveu classes para gerar logs da execução e visualizar os resultados usando o programa LogView, mostrando a troca de mensagens em tempo real durante a execução distribuída.
![Implementa¸c˜ao do algoritmo de exclus˜ao m´utua de Lamport
usando um framework de implementa¸c˜ao de algoritmos
distribu´ıdos
Alvaro Augustho de Souza Silva
Orientador: Luiz Eduardo Buzato
4 de novembro de 2011
Resumo
Neste documento ser´a apresentada uma implementa¸c˜ao em Java do algoritmo de ex-
clus˜ao m´utua de Lamport [1], baseado em rel´ogio l´ogicos, com o uso do framework
Neko. O Neko [3] ´e um framework desenvolvido para facilitar o desenvolvimento e im-
plementa¸c˜ao de algoritmos distribu´ıdos. O escolha do algoritmo de Lamport foi com
o objetivo de apresentar o funcionamento deste em um ambiente distribu´ıdo real (no
caso um cluster de 5 computadores) e os poss´ıveis usos dele e do pr´oprio Neko. Foi im-
plementado um mecanismo de gera¸c˜ao de log da troca de mensagens entre os processos
em um arquivo de texto simples, e com este log pˆode-se gerar um diagrama visual da
execu¸c˜ao correspondente a ele, em que um gr´afico representava a troca de mensagens
entre os n´os por meio de setas coloridas e etiquetas mostrando o tipos de mensagens
sendo enviadas. O programa usado para gerar este diagrama chama-se LogView e foi
feito em um projeto de semestre num instituto de tecnologia na Sui¸ca, com supervis˜ao
de um dos autores do Neko. O LogView [2] usado aqui foi modificado por mim, de
forma que ele pudesse exibir mais detalhes da troca de mensagens que a vers˜ao original
n˜ao exibia, como os tempos de envio e recebimento da mensagem, o tipo dela, algumas
mudan¸cas na interface de forma a tornar a visualiza¸c˜ao um pouco mais clara, entre
outras modifica¸c˜oes.
1 Introdu¸c˜ao
O problema da exclus˜ao m´utua ´e um ponto crucial de preocupa¸c˜ao em sistemas que com-
partilham recursos entre processos em v´arios computadores, ou mesmo threads de execu¸c˜ao
de um processo sendo executado em um ´unico computador. A quest˜ao ´e evitar que dois ou
mais processos ou threads tenham acesso simultaneamente a este recurso compartilhado,
comumente chamado de regi˜ao cr´ıtica (r.c.). A solu¸c˜ao apresentada para este problema
por Leslie Lamport em seu artigo Time, clocks, and the ordering of events in a distributed
system de 1978 se baseia na id´eia de timestamps. Timestamps s˜ao contadores monotonica-
mente crescentes mantidos unicamente por cada processo, e que seguem as trˆes seguintes
regras:
1](https://image.slidesharecdn.com/a9e4a384-5273-412a-b671-41f418ac7008-160527191928/85/Lamport-1-320.jpg)
![Implementa¸c˜ao do algoritmo de exclus˜ao m´utua de Lamport
usando um framework de implementa¸c˜ao de algoritmos
distribu´ıdos
Alvaro Augustho de Souza Silva
Orientador: Luiz Eduardo Buzato
4 de novembro de 2011
Resumo
Neste documento ser´a apresentada uma implementa¸c˜ao em Java do algoritmo de ex-
clus˜ao m´utua de Lamport [1], baseado em rel´ogio l´ogicos, com o uso do framework
Neko. O Neko [3] ´e um framework desenvolvido para facilitar o desenvolvimento e im-
plementa¸c˜ao de algoritmos distribu´ıdos. O escolha do algoritmo de Lamport foi com
o objetivo de apresentar o funcionamento deste em um ambiente distribu´ıdo real (no
caso um cluster de 5 computadores) e os poss´ıveis usos dele e do pr´oprio Neko. Foi im-
plementado um mecanismo de gera¸c˜ao de log da troca de mensagens entre os processos
em um arquivo de texto simples, e com este log pˆode-se gerar um diagrama visual da
execu¸c˜ao correspondente a ele, em que um gr´afico representava a troca de mensagens
entre os n´os por meio de setas coloridas e etiquetas mostrando o tipos de mensagens
sendo enviadas. O programa usado para gerar este diagrama chama-se LogView e foi
feito em um projeto de semestre num instituto de tecnologia na Sui¸ca, com supervis˜ao
de um dos autores do Neko. O LogView [2] usado aqui foi modificado por mim, de
forma que ele pudesse exibir mais detalhes da troca de mensagens que a vers˜ao original
n˜ao exibia, como os tempos de envio e recebimento da mensagem, o tipo dela, algumas
mudan¸cas na interface de forma a tornar a visualiza¸c˜ao um pouco mais clara, entre
outras modifica¸c˜oes.
1 Introdu¸c˜ao
O problema da exclus˜ao m´utua ´e um ponto crucial de preocupa¸c˜ao em sistemas que com-
partilham recursos entre processos em v´arios computadores, ou mesmo threads de execu¸c˜ao
de um processo sendo executado em um ´unico computador. A quest˜ao ´e evitar que dois ou
mais processos ou threads tenham acesso simultaneamente a este recurso compartilhado,
comumente chamado de regi˜ao cr´ıtica (r.c.). A solu¸c˜ao apresentada para este problema
por Leslie Lamport em seu artigo Time, clocks, and the ordering of events in a distributed
system de 1978 se baseia na id´eia de timestamps. Timestamps s˜ao contadores monotonica-
mente crescentes mantidos unicamente por cada processo, e que seguem as trˆes seguintes
regras:
1](https://image.slidesharecdn.com/a9e4a384-5273-412a-b671-41f418ac7008-160527191928/75/Lamport-1-2048.jpg)




![public void setMEAlgorithm(MEAlgorithm algorithm)
{
this.algorithm = algorithm;
}
/* o PID deste processo */
private int me;
/* o n´umero de processos
private int n;
/* objeto gerador de n´umeros aleat´orios */
private Random random;
public Application(NekoProcess process) {
super(process, "[Aplica¸c~ao] Thread-p" + process.getID());
me = process.getID();
n = process.getN();
}
A primeira parte do c´odigo faz as importa¸c˜oes de classes necess´arias. Esta classe estende
ActiveReceiver, uma classe do Neko que cria objetos capazes de receber ativamente men-
sagens que forem enviadas a eles, ao inv´es de simplesmente esperar elas serem entregues.
Seu funcionamento ser´a melhor entendido quando o algoritmo for apresentado; ele foi im-
plementado usando o funcionamento desta classe.
Neste come¸co tamb´em ´e criado o objeto Sender que tratar´a de enviar as mensagens que
porventura devam ser enviadas a outros processos, e por fim o algoritmo de exclus˜ao m´utua
a ser usado. Se eu tivesse implementado outro algoritmo em outra classe, bastava que ele
implementasse a mesma interface. Para escolher um e n˜ao outro, o arquivo de configura¸c˜ao
mencionado anteriormente seria usado.
Por fim, o construtor desta classe ´e mostrado. Ele chama o construtor da classe
NekoThread, a que ActiveReceiver estende, usando super. Esse construtor recebe um
objeto NekoProcess, que representa o processo que ser´a criado, e um nome ´e passado para
nomear a thread deste novo processo. ´E inicializada tamb´em uma vari´avel que guarda
o pr´oprio PID, me, e outra que guarda o n´umero de processos no ambiente de execu¸c˜ao.
Ambos ser˜ao usados `a frente.
public void run()
{
if(me == (n-1))
System.out.println("Processo " + me + " fazendo logging da execu¸c~ao...");
else {
System.out.println("Processo " + me + " tentando entrar na r.c..");
littleSleep(-1);
algorithm.enterCriticalSection();
6](https://image.slidesharecdn.com/a9e4a384-5273-412a-b671-41f418ac7008-160527191928/85/Lamport-6-320.jpg)

![3.3 A Classe de Inicializa¸c˜ao: MEInitializer.java
Para montar a estrutura de processos necess´aria para a execu¸c˜ao de um algoritmo no Neko
package lamport;
// lse.neko imports:
import lse.neko.NekoProcess;
import lse.neko.NekoProcessInitializer;
import lse.neko.ReceiverInterface;
import lse.neko.SenderInterface;
// other imports:
import org.apache.java.util.Configurations;
public class MEInitializer
implements NekoProcessInitializer
{
public MEInitializer() {
}
public void init(NekoProcess process, Configurations config)
throws Exception
{
/* Primeiro, constr´oi a pilha de protocolos e configura a rede. */
/* Camada da aplica¸c~ao */
Class applicationClass =
Class.forName(config.getString("application"));
Class[] appConstructorParamClasses = { NekoProcess.class };
Object[] appConstructorParams = { process };
ReceiverInterface application = (ReceiverInterface)
applicationClass
.getConstructor(appConstructorParamClasses)
.newInstance(appConstructorParams);
application.setId("app");
/* Camada do algoritmo */
Class algorithmClass =
Class.forName(config.getString("algorithm"));
Class[] algConstructorParamClasses = { NekoProcess.class };
Object[] algConstructorParams = { process };
ReceiverInterface algorithm = (ReceiverInterface)
algorithmClass
.getConstructor(algConstructorParamClasses)
.newInstance(algConstructorParams);
algorithm.setId("alg");
/* Configura a rede. */
SenderInterface net = process.getDefaultNetwork();
Na primeira parte s˜ao criados os objetos usados na pilha de protocolos. Neste caso s˜ao
trˆes: a camada da aplica¸c˜ao, mostrada anteriormente, a camada do algoritmo, usando uma
8](https://image.slidesharecdn.com/a9e4a384-5273-412a-b671-41f418ac7008-160527191928/85/Lamport-8-320.jpg)
![classe que ser´a mostrada a seguir, e o objeto ’net’, que implementa a camada de rede e
tratar´a da troca de mensagens, envio e entrega, entre os processos.
Como pode-se perceber, foi usado uma propriedade do Java chamada Reflection. Isso
´e usado para podermos saber em tempo de execu¸c˜ao qual a classe da aplica¸c˜ao e a do
algoritmo, que dever˜ao estar no arquivo de configura¸c˜ao. Fazendo assim, podemos usar
uma classe de inicializa¸c˜ao apenas (esta mesma) e escrever v´arias aplica¸c˜oes e algoritmos,
bastando mudar uma linha no arquivo de configura¸c˜ao para trocar entre elas. Se n˜ao
quis´essemos isso, bastava criar os objetos fazendo ReceiverInterface application = new
Application(process) para a camada de aplica¸c˜ao, e ReceiverInterface algorithm =
new LamportME(process), mas a flexibilidade e modularidade da nossa implementa¸c˜ao
ficaria prejudicada. Essa decis˜ao fica a cargo do programador.
ReceiverInterface ´e uma interface do Neko que s´o tem um m´etodo: deliver. Ele tem
o papel de gerenciar mensagens recebidas. ActiveReceiver implementa esta interface e
sobrescreve este m´etodo de modo que ele joga numa queue as mensagens recebidas. O
m´etodo receive que ele tamb´em implementa, por sua vez, retira mensagens da fila e entrega
ao processo que o chama, o destinat´ario original delas. A classe da aplica¸c˜ao estende
ActiveReceiver, mas n˜ao faz uso deste m´etodo; a classe que implementa o algoritmo far´a
amplo uso dele, como ser´a mostrado em breve.
/* Segundo, liga as camadas. */
/* Configura o objeto Sender que a aplica¸c~ao pode usar para mandar mensagens. */
applicationClass
.getMethod("setSender", new Class[] { SenderInterface.class })
.invoke(application, new Object[] { net });
/* Configura a camada do algoritmo criada anteriormente para ser usada
* pela camada de aplica¸c~ao quando ela quiser garantir exclus~ao m´utua
* no acesso `a regi~ao cr´ıtica. */
applicationClass
.getMethod("setMEAlgorithm", new Class[] { MEAlgorithm.class })
.invoke(application, new Object[] { algorithm });
/* Configura o objeto Sender que a camada do algoritmo usar´a para mandar mensagens. */
algorithmClass
.getMethod("setSender", new Class[] { SenderInterface.class })
.invoke(algorithm, new Object[] { net });
Continuando a usar Java Reflection, esta segunda parte liga as camadas da pilha de
protocolos do processo que est´a sendo constru´ıdo. Usa m´etodos pr´oprios das classes Appli-
cation, que usa setMEAlgorithm para dizer que o objeto ’algorithm’ criado anteriormente
´e o que deve ser usado como gerenciador da exclus˜ao m´utua, e setSender em ambos Appli-
cation e LamportME (a classe do algoritmo) para dizer que ’net’ ´e o objeto que gerenciar´a
a troca de mensagens na rede entre os processos.
// Terceira, inicia a execu¸c~ao dos protocolos.
application.launch();
algorithm.launch();
9](https://image.slidesharecdn.com/a9e4a384-5273-412a-b671-41f418ac7008-160527191928/85/Lamport-9-320.jpg)

![public void setSender(SenderInterface sender)
{
this.sender = sender;
}
/* objeto respons´avel pelo logging. */
/* Somente o processo n-1 ir´a tratar do logging, portanto somente ele usar´a este objeto */
MyLogger logger;
//algorithm variables
/* the id of this process */
private int me;
/* the number of processes */
private int n;
/* list of addresses that includes all processes but this one */
private int[] allButMe;
/* internal Lamport’s scalar clock */
int osn;
/* array of requests */
private NekoMessage[] q;
public LamportME(NekoProcess process) {
super(process, "LamportME-p" + process.getID());
n = process.getN();
me = process.getID();
allButMe = new int[n - 1];
for (int i = 0; i < n - 1; i++) {
allButMe[i] = (i < me) ? i : i + 1;
}
q = new NekoMessage[n];
osn = 0;
logger = new MyLogger(n);
}
Como dito anteriormente, esta classe estende ActiveReceiver e implementa a interface
MEAlgorithm, mostrada primeiro. Os tipos de menagens usados na execu¸c˜ao do algoritmo
s˜ao expostos no come¸co da classe: s˜ao associados n´umeros inteiros com as strings que
nomeiam os tipos da mensagens, e depois esses tipos s˜ao “registrados” no Neko com o uso
do m´etodo register da classe MessageTypes do Neko. Tudo que este m´etodo faz ´e associar
o nome do tipo da mensagem com o inteiro que a representar´a, e para isso usa um objeto
do tipo HashMap.
Ap´os isso s˜ao listadas as vari´aveis. Sender, como sabemos, ser´a o objeto que simular´a a
rede e gerenciar´a o envio de mensagens, e ´e inicializado usando o m´etodo setSender pela
classe de inicializa¸c˜ao, como mostrado anteriormente. Os inteiro me e n guardam o PID
do processo e o n´umero de processos no ambiente de execu¸c˜ao atual, respectivamente. O
vetor de inteiros allButMe serve para guardar o PID de todos os processos menos o pr´oprio
11](https://image.slidesharecdn.com/a9e4a384-5273-412a-b671-41f418ac7008-160527191928/85/Lamport-11-320.jpg)

![portanto este m´etodo retorna um inteiro. Vemos que, para cada tipo de mensagem, um
m´eodo foi escrito especialmente para tratar dela. Esses m´etodos ser˜ao mostrados abaixo.
/**
* M´etodo que gerencia mensagens do tipo "req"
* @param m: a mensagem do tipo "req" recebida
*/
private void requestMessageHandling(NekoMessage m) {
// obtem o valor do rel´ogio l´ogico enviado na mensagem
int k = ((Integer)m.getContent()).intValue();
// atualiza o pr´oprio rel´ogio l´ogico
update(k);
// coloca a mensagem no vetor de mensagens
int j = m.getSource();
q[j] = m;
// envia um "ack" de volta ao remetente, carregando o valor do pr´oprio rel´ogio
NekoMessage Ack = new NekoMessage(me, new int[] {j}, getId(), new Integer(osn), ack);
sender.send(Ack);
this.LogMessage(m, osn, r);
this.LogMessage(Ack, osn, s);
}
O tratamento de uma mensagem do tipo “req”, ou request ´e feito neste m´etodo. Primeiro
o rel´ogio l´ogico pr´oprio ´e atualizado com base no rel´ogio l´ogico recebido na mensagem envi-
ado de outro processo. Essa atualiza¸c˜ao ´e feita no m´etodo update. Ap´os isso, a mensagem
´e colocada na fila q na posi¸c˜ao destinada a mensagens recebidas pelo processo remetente
dela. Por fim, uma mensagem de resposta ack ´e enviada em unicast de volta ao processo
remetente, levando consigo o valor do rel´ogio l´ogico do processo atual.
O m´etodo send do objeto sender tem como ´unico argumento a mensagem a ser enviada.
Essa mensagem, encapsulada num objeto do tipo NekoMessage, ´e constru´ıda passando-se ao
m´etodo construtor como argumentos o PID do processo remetente, um vetor representando
os v´arios processos destinat´arios dela (neste caso o vetor s´o contem o remetente da mensagem
“req” recebida), um identificador do protocolo de destino (basta usar o m´etodo getId), o
conte´udo a ser transmitido (neste caso o valor do pr´oprio rel´ogio l´ogico, mas pode ser
qualquer objeto Java) e o tipo da mensagem, nesta ordem. send enviar´a a mensagem sem
que o usu´ario precise se preocupar com mais detalhes.
/**
* M´etodo que trata mensagens "rel"
* @param m: a mensagem do tipo "rel" recebida
*/
private void releaseMessageHandling(NekoMessage m) {
int k = ((Integer)m.getContent()).intValue(); // obtem o valor do rel´ogio l´ogico enviado na mensagem
update(k); // atualiza o pr´oprio rel´ogio l´ogico
int j = m.getSource();
13](https://image.slidesharecdn.com/a9e4a384-5273-412a-b671-41f418ac7008-160527191928/85/Lamport-13-320.jpg)
![q[j] = m;
this.LogMessage(m, osn, r);
}
Este ´e o m´etodo que trata mensagens do tipo “rel”, ou release. S˜ao feitas duas coisas: o
rel´ogio l´ogico pr´oprio ´e atualizado (ele sempre ´e atualiado quando uma mensagem ´e recebido,
como o algoritmo pede para ser feito) e a mensagem ´e colocada no vetor de mensagens, na
posi¸c˜ao destinada a mensagens do remetente dela.
/**
* Method that handles ack messages.
* It also counts the number of acks received since a request was sent.
* @param m: the message received
*/
private void ackMessageHandling(NekoMessage m) {
int k = ((Integer)m.getContent()).intValue(); // obtem o valor do rel´ogio l´ogico enviado na mensagem
update(k); // atualiza o pr´oprio rel´ogio l´ogico
int j = m.getSource();
if(q[j] != null && q[j].getType() != req)
q[j] = m;
this.LogMessage(m, osn, r);
}
Por fim, mensagens do tipo “ack” s˜ao tratadas por este m´etodo. Como nas mensagens do
tipo release, nenhuma resposta precisa ser enviada de volta ao remetente. Portanto, apenas
a atualiza¸c˜ao do rel´ogio l´ogico pr´oprio e o coloca¸c˜ao da mensagem no vetor de mensagens
´e feito. Por´em, essa coloca¸c˜ao do “ack” no vetor deve ser feita com um cuidado extra:
o “ack” n˜ao pode sobrescrever request que por acaso tenham sido enviados pelo processo
remetente deste “ack” anteriormente; somente releases podem fazˆe-lo. Caso contr´ario, o
processo atual poderia julgar que a prioridade para entrar na ´area cr´ıtica pudesse ser sua,
quando na verdade era do processo que teve sua mensagem de request apagada pelo “ack”.
Os dois processos entrariam na r.c. e a exclus˜ao m´utua n˜ao aconteceria. Portanto, esse
cuidado ´e tomado no teste do if, antes de atribuir q[j] a m.
public void enterCriticalSection() {
// multicast de uma mensagem do tipo ’req’ requisitando a entrada na r.c.
NekoMessage Req = new NekoMessage(me, allButMe, getId(), new Integer(osn), req);
sender.send(Req);
this.LogMessage(Req, osn, s);
// adiciona pr´opria requisi¸c~ao `a queue de mensagens e atualiza rel´ogio l´ogico
q[me] = Req; osn = osn + 1;
while(!testPriority()) {
try {
14](https://image.slidesharecdn.com/a9e4a384-5273-412a-b671-41f418ac7008-160527191928/85/Lamport-14-320.jpg)
![sleep(500);
} catch (InterruptedException e) {
System.out.println("Erro ao testar prioridade da thread.");
}
}
}
Este ´e m´etodo que coloca o algoritmo em funcionamento. ´E a implementa¸c˜ao do
enterCriticalSection presente na interface MEAlgorithm e, como sabemos, ´e o que deve
ser chamado quando a aplica¸c˜ao deseja entrar na regi˜ao cr´ıtica. Como a defini¸c˜ao do al-
goritmo pede, o que ´e feito ´e o seguinte: ´e feito um broadcast de uma mensagem “req”,
carregando o pr´oprio PID e o pr´oprio valor do rel´ogio l´ogico do processo atual antes do envio
da mensagem. Essa mensagem “req” tamb´em ´e guardada no pr´oprio vetor de mensagens,
na posi¸c˜ao destinada `as pr´oprias mensagens, e o rel´ogio l´ogico ´e atualizado. Entao, um loop
de teste fica rodando em ciclos de 500ms, testando se o processo atual tem a prioridade
para entrar na regi˜ao cr´ıtica. Quando esta prioridade ´e ganha, o loop termina, e o m´etodo
retorna. A aplica¸c˜ao continua sua execu¸c˜ao, agora com o processo atual utilizando-se da
regi˜ao cr´ıtica.
public void exitCriticalSection() {
// multicast de release
NekoMessage Rel = new NekoMessage(me, allButMe, getId(), new Integer(osn), rel);
sender.send(Rel);
this.LogMessage(Req, osn, s);
q[me] = Rel;
osn = osn + 1;
}
Quando a aplica¸c˜ao termina de usar a regi˜ao cr´ıtica, o m´etodo exitCriticalSection,
tamb´em presente na interface MEAlgorithm, ´e executado. O que ele faz ´e enviar em broad-
cast uma mensagem de release, “rel”, mostrando que terminou de usar sua prioridade e que
outro processo requisitante pode fazer uso da regi˜ao. Essa mensagem de release ´e colocada
no vetor de mensagens, na posi¸c˜ao destinada `as pr´oprias mensagens, e o rel´ogio l´ogico ´e
incrementado de uma unidade de tempo.
private void update(int k)
{
if(osn < k) osn = k;
osn = osn + 1;
}
Este m´etodo simples trata da atualiza¸c˜ao do rel´ogio l´ogico como deve ser feita na especi-
fica¸c˜ao do algoritmo de exclus˜ao m´utua de Lamport. Um inteiro k ´e recebido; se este k for
maior que o rel´ogio l´ogico atual, osn ´e atualizado com esse valor (acontece no caso que uma
mensagem recebida tinha um rel´ogio l´ogico maior que o do processo atual, significando que
15](https://image.slidesharecdn.com/a9e4a384-5273-412a-b671-41f418ac7008-160527191928/85/Lamport-15-320.jpg)
![ele estava atrasado em rela¸c˜ao ao processo remetente). Para terminar, osn ´e aumentado em
mais uma unidade.
public boolean testPriority() {
int myReqClock = ((Integer)q[me].getContent()).intValue();
for(int i = 0; i < n; i++) {
if(q[i] == null) return false;
if(q[i].getType() == req) {
int otherReqClock = ((Integer)q[i].getContent()).intValue();
if((otherReqClock < myReqClock)
|| (otherReqClock == myReqClock && i < me)) {
System.out.println(me + ": Processo " + i + " tem prioridade para entrar na r.c.!"
+ " O rel´ogio da minha req ´e " + myReqClock
+ " e o da dele ´e " + otherReqClock + ".");
return false;
}
}
}
osn = osn + 1;
return true;
}
} // class
Para terminar a descri¸c˜ao desta classe, o ´ultimo m´etodo ´e o que controla o processo
da exclus˜ao m´utua, e portanto ´e o mais importante. O teste para saber se o processo
em quest˜ao vai ganhar ou n˜ao a prioridade de entrada na ´area cr´ıtica ´e feito da seguinte
maneira, como especificado na defini¸c˜ao do algoritmo: o rel´ogio da mensagem de request do
pr´oprio processo presente na fila de mensagens ´e comparado com todas as outras mensagens
de request de outros processos presentes na fila. Se nenhuma delas tiver um rel´ogio de valor
menor que o da “req” pr´opria, ou tiver um valor igual, por´em o PID do outro processo for
maior que o PID do processo que est´a testando a prioridade, ent˜ao esse processo ganha a
prioridade e pode entrar na regi˜ao cr´ıtica. Caso contr´ario, ele n˜ao ganha a prioridade, e o
teste ser´a executado novamente no loop mostrado no m´etodo enterCriticalSection, at´e
que ele ganhe a prioridade e possa usufruir da ´area cr´ıtica. Dessa forma, ´e assegurado que
somente um processo por vez tem acesso a essa ´area, e a exclus˜ao m´utua funciona durante
a execu¸c˜ao da aplica¸c˜ao.
Quando o processo entra na ´area cr´ıtica, o rel´ogio dele aumenta em uma unidade, por
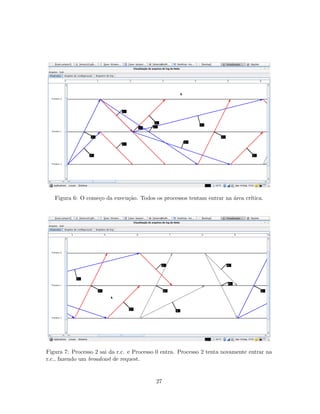
isto ser tratado como um evento na execu¸c˜ao. Isso tamb´em facilita um pouco a visualiza¸c˜ao
das mensagens de release no gr´afico gerado pelo logView, mostrado mais `a frente.
16](https://image.slidesharecdn.com/a9e4a384-5273-412a-b671-41f418ac7008-160527191928/85/Lamport-16-320.jpg)





![int eventSource = logMsg.getSource();
int eventType = logMsg.getType();
String[] s = formatString(msg, eventSource, eventType, osn);
for(int i=0; i<s.length;i++) {
if(s[i] != null) {
try{
if(firstEntry) {
fw = new FileWriter(logPath, false);
firstEntry = false;
} else fw = new FileWriter(logPath, true);
BufferedWriter out = new BufferedWriter(fw);
out.write(s[i] + "n");
out.close();
} catch (Exception e) {
System.err.println("Error: " + e.getCause());
}
}
}
}
O m´etodo doLogging trata os eventos de envio e recebimento de mensagens que devem
ser registrados no arquivo de log.
private String[] formatString(NekoMessage m, int source, int type, int osn) {
String[] v = new String[n];
String time = String.valueOf(osn);
String eventType = MessageTypes.instance().getName(type);
int messageSource = m.getSource();
int[] messageDest = m.getDestinations();
String messageType = MessageTypes.instance().getName(m.getType());
String messageContent = String.valueOf(m.getContent());
if(eventType == "r") {
String f = time + " p" + source + " messages e " + eventType + " p" + messageSource +
" p" + source + " " + messageType + " " + messageContent;
v[0] = f;
}
else for(int i=0; i<messageDest.length; i++) {
String f = time + " p" + source + " messages e " + "s" + " p" + source +
" p" + messageDest[i] + " " + messageType + " " + messageContent;
v[i] = f;
}
return v;
}
23](https://image.slidesharecdn.com/a9e4a384-5273-412a-b671-41f418ac7008-160527191928/85/Lamport-23-320.jpg)




![tornando poss´ıvel a visualiza¸c˜ao dos eventos na execu¸c˜ao segundo uma ordena¸c˜ao do tipo
happened-before entre todas a mensagens. Sendo assim, a visualiza¸c˜ao gerada se torna um
instrumento muito ´util para se enxergar como um algoritmo distribu´ıdo funciona.
O Neko e o LogView podem ser encontrados nas p´aginas listadas na bibliografia.
Referˆencias
[1] L Lamport. “Time, Clocks, and the Ordering of Events in a Distributed System”. In:
Communications of the ACM 21 (1978), pp. 558–565.
[2] J. Muller, M. Galanthay e P. Urb´an. Rapport de Projet de Semestre Visualisation des
Fichiers de Traces de Neko : LogView. 2002. url: http://ddsg.jaist.ac.jp/neko/
logView/rapport/rapport.pdf.
[3] P. ´Urban, X. D´efago e A. Schiper. “Neko: A Single Environment to Simulate and Pro-
totype Distributed Algotithms”. In: Journal of Information Science and Engineering
18 (2002), pp. 981–997. url: http://ddsg.jaist.ac.jp/pub/UDS02.pdf.
29](https://image.slidesharecdn.com/a9e4a384-5273-412a-b671-41f418ac7008-160527191928/85/Lamport-29-320.jpg)













































