Baixar para ler offline






![Medição: Index Selectivity
Cardinalidade
[Código Postal] Quantos distintos haverá em PT?
Valores distintos
---------------
1000?
Se tiver uma tabela com registo de 10 milhões de
licenças de condução?
Selectividade = 1000 / 10 000 000
Is = 0,0001%](https://image.slidesharecdn.com/gestodaaplicaocap12-121129173531-phpapp01/85/Gestao-da-Aplicacao-7-320.jpg)




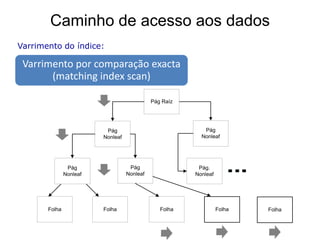
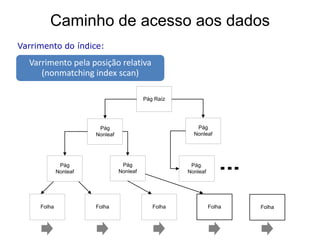
![Caminho de acesso aos dados
Varrimento das tabelas:
• não existe(m) índice(s) ou as condições
[WHERE] excluem o(s) índice(s)
• grande número de linhas que satisfazem as
condições
• índices com baixo clustering (index page cluster ratio)
• a tabela é demasiado pequena (poucas linhas)](https://image.slidesharecdn.com/gestodaaplicaocap12-121129173531-phpapp01/85/Gestao-da-Aplicacao-13-320.jpg)





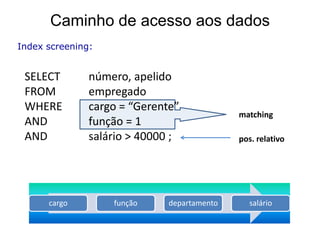
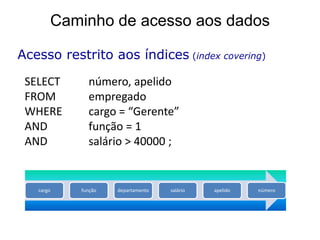











![Optimização do SQL
Video [“esclarecedor”] sobre SQL
Optimization em Oracle: ver aqui.](https://image.slidesharecdn.com/gestodaaplicaocap12-121129173531-phpapp01/85/Gestao-da-Aplicacao-34-320.jpg)


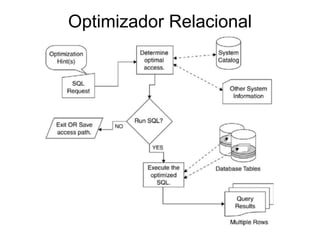
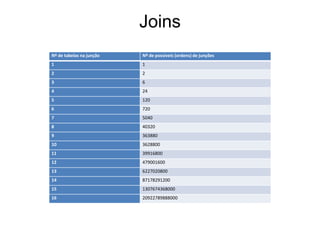
Este documento discute otimização de desempenho de banco de dados. Aborda tópicos como: 1) O otimizador relacional que gera planos de execução SQL considerando fatores como custo; 2) Medição de seletividade e densidade de índices para escolha do tipo; 3) Diferentes caminhos de acesso aos dados, incluindo varrimento de tabela vs índice; 4) Reescrita de queries para maior eficiência.























































































