Baixar para ler offline








![Criação de uma tabela pessoa com dados
ctícios
DROP TABLE IF EXISTS pessoa;
CREATE TABLE pessoa AS
WITH candidatos AS (
SELECT
cast(regexp_replace(md5(cast(random() as text)), '[^0-9]+','','g') as numeric) as cpf,
upper(regexp_replace(md5(cast(random() as text)), '[0-9]+',' ','g')) as nome,
cast(random() * 30 as integer) + 18 as idade
FROM generate_series(1,1000000)
)
SELECT DISTINCT ON(cpf) *
FROM candidatos
ORDER BY cpf, idade;
DROP TABLE
SELECT 999777](https://image.slidesharecdn.com/meetup-001-destistificando-explain-171107114728/85/Destistificando-o-EXPLAIN-8-320.jpg)
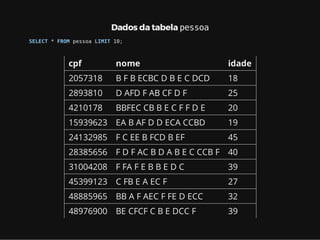
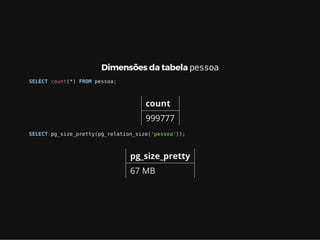


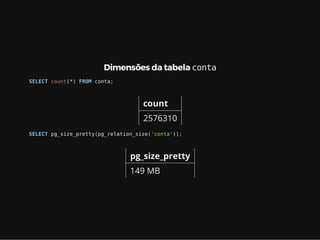





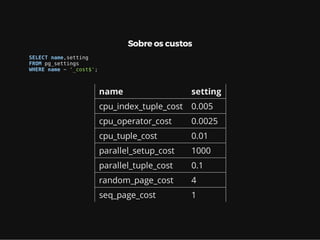







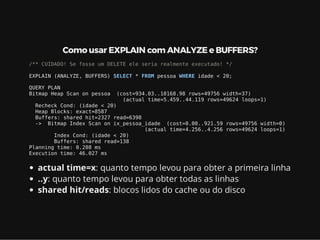
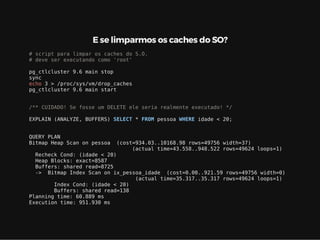
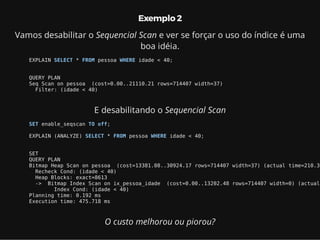
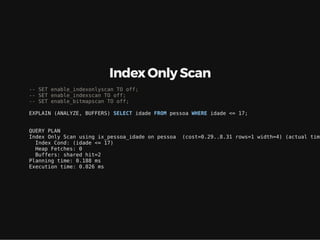


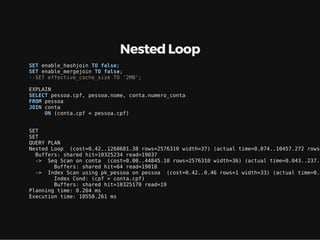

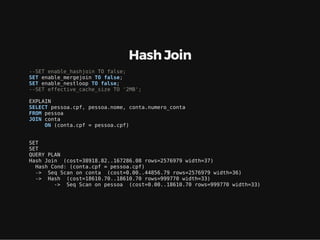

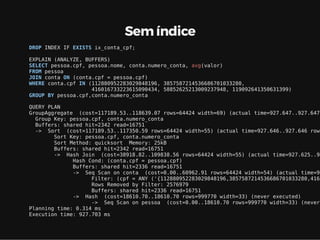



Este documento resume os principais conceitos de bancos de dados relacionais utilizando PostgreSQL. Inclui exemplos de criação de tabelas, tipos de busca como sequencial scan e index scan, diferentes tipos de junções como nested loop, merge join e hash join, e agregações com grupo.














































