Baixado 12 vezes






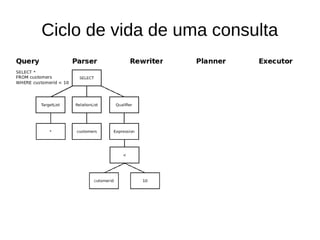
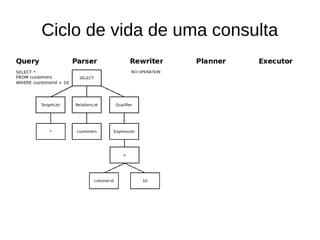
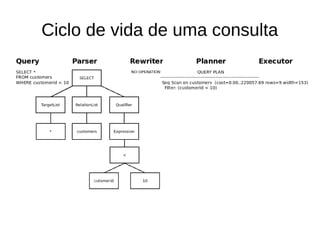
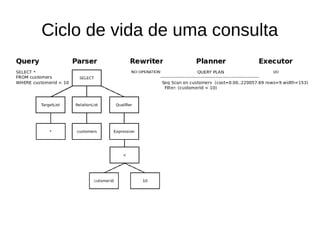
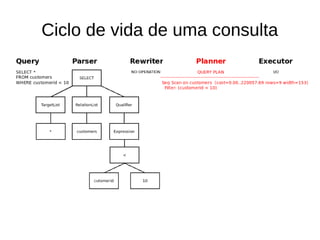










![Custo de uma consulta
explain SELECT * FROM customers WHERE customerid < 10;
Seq Scan on customers (cost=0.00..220060.00 rows=9 width=153)
Filter: (customerid < 10)
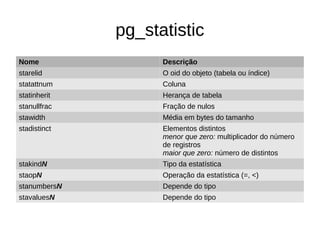
● Rows: estimativa de tuplas a retornar
– Total de tuplas * Selectividade
– Selectividade: (bucks + (val – bucket[min])/bucket[max] – bucket[min]))/total
buckets
● (0 + (10 – 1)/(60000 – 1)/100) = 0,000001500250004166736
– 6000000 * 0,000001500250004166736
– 9.000150002500041600000000](https://image.slidesharecdn.com/usodeestatisticaspelopostgresql-141016150836-conversion-gate01/85/Uso-de-estatisticas-pelo-postgre-sql-26-320.jpg)







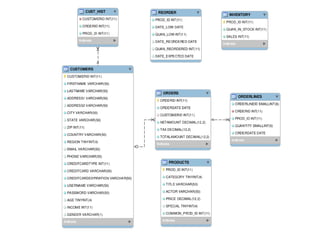
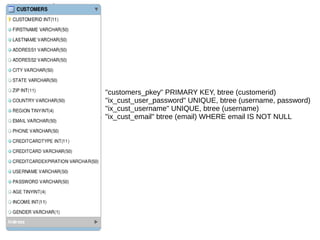
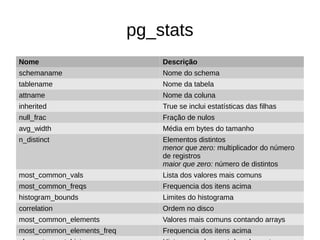
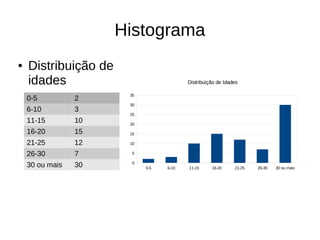
O documento explica como o PostgreSQL usa estatísticas para estimar o custo e número de linhas de consultas SQL, melhorando o desempenho ao reduzir acessos desnecessários ao disco. Detalha onde são armazenadas as estatísticas, seus tipos e como são usadas para cálculos de seletividade que influenciam o planejamento de consultas.










































