Transferir como PDF, PPTX








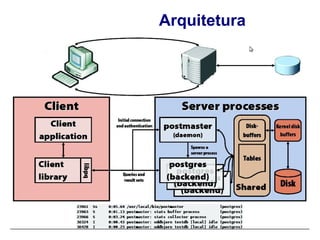
















O documento apresenta uma oficina básica sobre PostgreSQL ministrada por Fabrizio de Royes Mello. A agenda inclui introdução ao PostgreSQL, preparação do servidor, e manipulação de bancos de dados. O público aprenderá sobre instalação, configuração de clusters, criação e remoção de bancos de dados no PostgreSQL.










































































