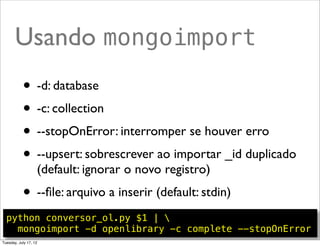
Baixado 18 vezes












![Carga: conversor_ol.py
import sys
import json
import io
def conv_linha(lin, indent=None):
rec_type, rec_key, rec_revision, rec_modified, rec_json = lin.split(u't')
rec = json.loads(rec_json)
rec[u'_id'] = rec_key + u'-' + rec_revision
return json.dumps(rec, indent=indent)
def conv_arquivo(nome_arq, max_lin=sys.maxsize, indent=None):
with io.open(nome_arq, encoding='utf-8') as arq:
for num_lin, lin in enumerate(arq, 1):
if not lin.strip():
continue
saida = conv_linha(lin, indent)
print saida.encode('utf-8')
if num_lin >= max_lin:
break
if __name__=='__main__':
if len(sys.argv) == 2:
converte_arquivo(sys.argv[1])
else:
print 'Modo de usar: %s <ol_dump_file>' % __name__
* https://github.com/ramalho/mongosp
@ramalhoorg
Tuesday, July 17, 12](https://image.slidesharecdn.com/openlibrary-mongodb-120717044627-phpapp01/85/Open-Library-no-Mongodb-12-320.jpg)







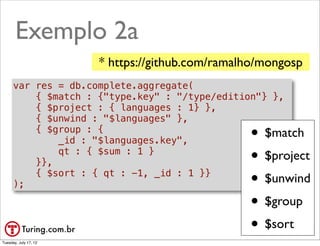






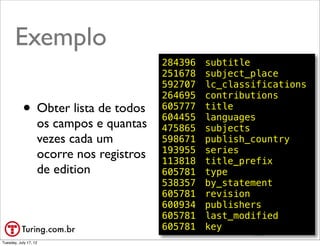

![Reduce
• Todos os pares de («chave», «valor»)
são agrupados em pares pela «chave»:
(«chave»: [«valor0», «valor1», «valor2»])
• A função reduce deve reduzir cada
«array_de_valores» a um único valor
var reduce = function (key, values) {
var total = 0;
values.forEach(function(n) { total += n; });
return total;
}
@ramalhoorg
Tuesday, July 17, 12](https://image.slidesharecdn.com/openlibrary-mongodb-120717044627-phpapp01/85/Open-Library-no-Mongodb-32-320.jpg)
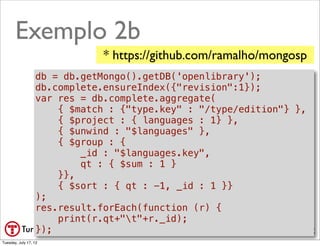
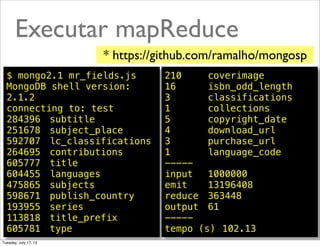
![Executar mapReduce
var res = db.complete.mapReduce(map, reduce, {
"out": { "inline" : 1},
"jsMode": true
});
//exibir resultado
res.results.forEach(function (r) {
print(r.value+"t"+r._id);
});
print("-----");
for (var chave in res.counts) {
if (chave !== "_id") {
print(chave+"t"+res.counts[chave]);
}
}
print("-----");
print("tempo (s)t"+res.timeMillis/1000);
@ramalhoorg
Tuesday, July 17, 12](https://image.slidesharecdn.com/openlibrary-mongodb-120717044627-phpapp01/85/Open-Library-no-Mongodb-33-320.jpg)
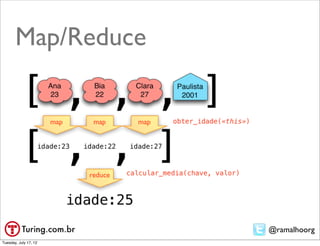
![Resultado de
mapReduce • Usando {"out":
> var res = db.complete.mapReduce(map, { "inline" : 1}}
... reduce, {"out": { "inline" : 1},
... "jsMode": true });
{ [...]
"results" : [ ! ! {
! ! { ! ! ! "_id" : "works",
! ! ! "_id" : "_id", ! ! ! "value" : 4415
! ! ! "value" : 605781 ! ! }
! ! }, ! ],
! ! { ! "timeMillis" : 156659,
! ! ! "_id" : "authors", ! "counts" : {
! ! ! "value" : 469305 ! ! "input" : 1000000,
! ! }, ! ! "emit" : 13196408,
! ! { ! ! "reduce" : 363448,
! ! ! "_id" : "by_statement", ! ! "output" : 61
! ! ! "value" : 538357 ! },
! ! }, ! "ok" : 1,
! ! { }
! ! ! "_id" : "classifications", real! 2m36.696s
! ! ! "value" : 3 user! 0m0.028s
! ! }, sys!0m0.005s
@ramalhoorg
Tuesday, July 17, 12](https://image.slidesharecdn.com/openlibrary-mongodb-120717044627-phpapp01/85/Open-Library-no-Mongodb-34-320.jpg)
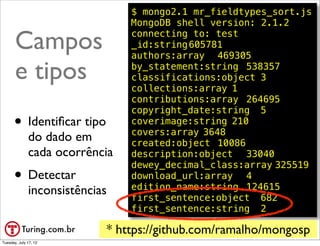

![{
"subtitle": "Ausbau und Planung der petrochemischen und energieintensiven
Industrien zum Zeitpunkt des zweiten Golfkriegs",
Um registro
"subject_place": [
"Middle East."
],
"lc_classifications": [
"HD9579.C33 M6284 1991"
],
"contributions": [
"Helmschrott, Helmut."
],
"title": "Industrialisierung der arabischen OPEC-Lau0308nder und des Iran",
"languages": [
{
"key": "/languages/ger"
}
],
"subjects": [
"Petroleum chemicals industry -- Middle East.",
"Petroleum industry and trade -- Middle East.",
"Gas industry -- Middle East."
],
"publish_country": "gw ",
"series": [
"Ifo Forschungsberichte der Abteilung Entwicklungslau0308nder ;",
"Nr. 74",
"Ifo Forschungsberichte der Abteilung Entwicklungslau0308nder ;",
"74."
],
"title_prefix": "Die ",
"type": {
"key": "/type/edition"
},
• 25 campos neste
"by_statement": "von Axel J. Halbach, Helmut Helmschrott.",
"revision": 1,
"publishers": [
"Ifo Institut fuu0308r Wirtschaftsforschung",
"Weltforum Verlag"
],
"last_modified": {
registro
"type": "/type/datetime",
"value": "2008-04-01T03:28:50.625462"
},
"key": "/books/OL1656964M",
"authors": [
{
"key": "/authors/OL45038A"
}
],
"publish_places": [
"Muu0308nchen"
],
"pagination": "viii, 270 p. :",
"lccn": [
"91218377"
],
"notes": {
"type": "/type/text",
"value": "Includes bibliographical references (p. 268-270)."
},
"number_of_pages": 270,
"isbn_10": [
"3803903955"
],
"publish_date": "1991",
"_id": "/books/OL1656964M-1"
}
@ramalhoorg
Tuesday, July 17, 12](https://image.slidesharecdn.com/openlibrary-mongodb-120717044627-phpapp01/85/Open-Library-no-Mongodb-38-320.jpg)
![Chave estrangeira
"title": "Industrialisierung der arabischen...",
"revision": 1,
"publishers": [
"Ifo Institut fuu0308r Wirtschaftsforschung",
"Weltforum Verlag"
],
"last_modified": {
"type": "/type/datetime",
"value": "2008-04-01T03:28:50.625462"
},
"key": "/books/OL1656964M",
"authors": [
{
"key": "/authors/OL45038A"
}
],
"publish_places": [
"Muu0308nchen"
],
@ramalhoorg
Tuesday, July 17, 12](https://image.slidesharecdn.com/openlibrary-mongodb-120717044627-phpapp01/85/Open-Library-no-Mongodb-39-320.jpg)
![Refatoração do esquema
• Usar key+revision como chave primária _id
• Manter campos key e revision separados
• Para fazer pseudo-auto join recuperando o
histórico de um registro bibliográfico
• Embutir (embed) campo nome do autor no
documento
"authors": [
{
"key": "/authors/OL45038A",
"name": "W. A. Mozart"
}
], @ramalhoorg
Tuesday, July 17, 12](https://image.slidesharecdn.com/openlibrary-mongodb-120717044627-phpapp01/85/Open-Library-no-Mongodb-40-320.jpg)




O documento descreve um projeto para analisar e modelar os dados da Open Library usando MongoDB. Ele discute a conversão e importação dos dados, análise com o framework de agregação e Map/Reduce, e refatoração do modelo de dados para MongoDB.




























































