Minicurso Introdução ao Controle e machine Learning
2.
Introdução ao Controlee Machine Learning
Prof. Dr. Leonardo Rodrigues
Universidade Federal do Maranhão
3.
▶ Definir oque é inteligência artificial.
▶ Principais Características da IA.
▶ Uso da inteligência artificial na matemática.
▶ Definir uma Rede Neural.
▶ Definir uma EDO Neural
▶ Controle para EDO’s Neurais
Objetivos do Minicurso
4.
▶ Inteligência Artificial(IA) refere-se ao campo da ciência da computação que se concentra
na criação de sistemas capazes de realizar tarefas que normalmente exigiriam inteligência
humana.
▶ Estas tarefas incluem aprendizado, raciocínio, resolução de problemas, percepção,
reconhecimento de padrões, comparação de linguagem natural e interação com o
ambiente.
▶ Ou seja, tentamos reproduzir nas máquinas a capacidade cognitiva humana dos seres
humanos!
▶ E como fazermos isso?
O que é Inteligência da Artificial
5.
Usamos Matemática atravésde algoritmos que são treinados a partir de dados. Esses algoritmos
são executados no computador através de linguagens de programação.
Os segredos Pro Trás da IA
6.
Usamos Matemática atravésde algoritmos que são treinados a partir de dados. Esses algoritmos
são executados no computador através de linguagens de programação.
Se existir um padrão nos dados, um algoritmo será capaz de aprender esse padrão gerando assim
um modelo. Esse modelo pode ser usado com novoc dados para resolver o problema para o qual
ele foi criado.
Os segredos Pro Trás da IA
7.
Usamos Matemática atravésde algoritmos que são treinados a partir de dados. Esses algoritmos
são executados no computador através de linguagens de programação.
Se existir um padrão nos dados, um algoritmo será capaz de aprender esse padrão gerando assim
um modelo. Esse modelo pode ser usado com novoc dados para resolver o problema para o qual
ele foi criado.
Por exemplo
▶ Modelo de IA para classificar imagens ou detectar objetos de imagens;
▶ Modelo de IA para gerar texto;
▶ Modelo de IA para detectar anomalias em transações financeiras.
▶ Modelo de IA para prever as vendas no próximo mês.
▶ Modelo de IA para prever a ocorrência de doenças.
Os segredos Pro Trás da IA
8.
Ou seja, usamosa nossa querida Matemática para tentar reproduzir a inteligência humana nas
máquinas.
Os segredos Pro Trás da IA
9.
Ou seja, usamosa nossa querida Matemática para tentar reproduzir a inteligência humana nas
máquinas.
Fonte: Internet, 2025.
Os segredos Pro Trás da IA
10.
▶ IA Estreita(ouIA Fraca ou Narrow AI): Projetada para executar uma tarefa especifica,
cmo assistentes virtuais, reconhecimento facial, sistemas de recomendação, etc. Não
possui consciência ou entendimento além de suas funções programadas. É o que existe
hoje em termos de IA.
Principais Categorias de IA
11.
▶ IA Estreita(ouIA Fraca ou Narrow AI): Projetada para executar uma tarefa especifica,
cmo assistentes virtuais, reconhecimento facial, sistemas de recomendação, etc. Não
possui consciência ou entendimento além de suas funções programadas. É o que existe
hoje em termos de IA.
▶ IA Geral (ou IA Forte ou AGI - Artificial General Intelligence): Uma IA teórica que
teria a capacidade de entender, aprender e aplicar conhecimento de maneira geral,
semelhante à inteligência humana. Ainda não foi desenvolvida e é um tópico de pesquisa e
debate. Não existe, ainda!
▶ Nota:
Principais Categorias de IA
12.
▶ IA Estreita(ouIA Fraca ou Narrow AI): Projetada para executar uma tarefa especifica,
cmo assistentes virtuais, reconhecimento facial, sistemas de recomendação, etc. Não
possui consciência ou entendimento além de suas funções programadas. É o que existe
hoje em termos de IA.
▶ IA Geral (ou IA Forte ou AGI - Artificial General Intelligence): Uma IA teórica que
teria a capacidade de entender, aprender e aplicar conhecimento de maneira geral,
semelhante à inteligência humana. Ainda não foi desenvolvida e é um tópico de pesquisa e
debate. Não existe, ainda!
▶ Nota:Modelos Generativos Multimodais (que geram texto e imagem, por exemplo) não
são IA Geral, mas sim a junção de vários modelos de IA Estreita em uma única solução
Principais Categorias de IA
13.
▶ Anos 1940-1950:Primeiro Modelo Matemático
▶ 1943: Warren McCullon e Walter Pitts propõem o primeiro modelo matemático de uma rede
neural;
▶ 1950: Alan Turing publica "Computing Machinery and Intelligence"e propõe o Teste de
Turing para determinar se uma máquina exibir comportamento inteligente equivalente ao
humano.
História e Evolução da IA
14.
▶ Anos 1940-1950:Primeiro Modelo Matemático
▶ 1943: Warren McCullon e Walter Pitts propõem o primeiro modelo matemático de uma rede
neural;
▶ 1950: Alan Turing publica "Computing Machinery and Intelligence"e propõe o Teste de
Turing para determinar se uma máquina exibir comportamento inteligente equivalente ao
humano.
▶ Anos 1950 - 1960:Primeiros passos e Surgimento do termo "Inteligência Artificial"
▶ 1956: Conferência de Dartmouth, onde o termo "Inteligência Artificial"surgiu pela primeira
vez. Esta conferência é considerada o ponto de partida oficial do campo da IA.
▶ 1957: Frank Rosenblatt desenvolve o Perceptron, um algoritmo de aprendizado
supervisionado para redes neurais.
▶ 1958: John Mccarthy desenvolve a linguagem de programação LISP, que se torna
fundamental para a pesquisa em IA.
História e Evolução da IA
15.
▶ Anos 1960- 1970: Otimismo e primeiros sistemas
▶ 1965: Joseph Weizenbaum cria o Eliza, um dos primeiros programas de processamento de
linguagem natural.
História e Evolução da IA
16.
▶ Anos 1960- 1970: Otimismo e primeiros sistemas
▶ 1965: Joseph Weizenbaum cria o Eliza, um dos primeiros programas de processamento de
linguagem natural.
▶ 1969: Marvin e Seymour Papert publicam "Percepstrons", mostrando limitações das redes
neurais da época, o que leva a um declínio no interesse por essa abordagem.
História e Evolução da IA
17.
▶ Anos 1970- 1980: "Inverno da IA"e Desenvolvimento dos sistemas Especialistas
▶ 1970: Primeira crise de financiamento para IA, chamada como o "Inverno da IA", devido a
promessas não cumpridas e limitações lógicas.
História e Evolução da IA
18.
▶ Anos 1970- 1980: "Inverno da IA"e Desenvolvimento dos sistemas Especialistas
▶ 1970: Primeira crise de financiamento para IA, chamada como o "Inverno da IA", devido a
promessas não cumpridas e limitações lógicas.
▶ 1972: Prolog, uma linguagem de programação lógica, é desenvolvida por Alain Colmerauer.
História e Evolução da IA
19.
▶ Anos 1970- 1980: "Inverno da IA"e Desenvolvimento dos sistemas Especialistas
▶ 1970: Primeira crise de financiamento para IA, chamada como o "Inverno da IA", devido a
promessas não cumpridas e limitações lógicas.
▶ 1972: Prolog, uma linguagem de programação lógica, é desenvolvida por Alain Colmerauer.
▶ 1980: Evolução do primeiros "sistemas especialistas"como DENDRAL, para análise química,
e MYCIN, para diagnóstico médico
História e Evolução da IA
20.
▶ Anos 1990- 2000: IA no Coditiano
▶ 1997: O computador Deep Blue da IBM derrota o campeão do mundial de Xadrez Garry
kasparov, um marco significativ na IA.
História e Evolução da IA
21.
▶ Anos 1990- 2000: IA no Coditiano
▶ 1997: O computador Deep Blue da IBM derrota o campeão do mundial de Xadrez Garry
kasparov, um marco significativ na IA.
▶ 1999: Começam a surgir as poderosas GPUs(Unidades de Processamento Gráfico) da Nvídia,
inicialmente criadas para renderizar jogos de computador, mas que se tornariam o principal
motor de evolução da IA devido à capacidade de paralelizar as operações com matrizes,
operações matmáticas por trás dos algiritmos de redes neurais artificiais. A Nvidia é hoje a
principal fabricante de GPus do mundo e uma das empresas mais valiosas do planeta!
História e Evolução da IA
22.
Ou seja, usamosa nossa querida Matemática para tentar reproduzir a
▶ Anos 2000 - 2010: Ia na Internet, Big Data e GPU
▶ 2005: O termo Big Data fpi definido oela primeira vez, representando grandes volumes de
dados, gerados em alta velocidade e alta variedade. C combustível que a IA precisva.
História e Evolução da IA
23.
Ou seja, usamosa nossa querida Matemática para tentar reproduzir a
▶ Anos 2000 - 2010: Ia na Internet, Big Data e GPU
▶ 2005: O termo Big Data fpi definido oela primeira vez, representando grandes volumes de
dados, gerados em alta velocidade e alta variedade. C combustível que a IA precisva.
▶ 2006: Geoffrey Hinton e seus colegas popularizam o termo "Aprendizado profundo"e
demonstram seu potencial em reconhecimento de padrões;
▶ 2009: O uso de GPU(Unidade de Processamento Gráfico) Começa a ganhar destaque,
acelerando de forma considerável o treinamento e uso dos modelos de IA. Se Big Data foi o
combustível, a GPU foi a ignição.
História e Evolução da IA
24.
▶ Anos 2010- 2020: IA Avançada e Aplicações Práticas
▶ 2012: A arquitetura de aprendizado profundo AlexNet (Rede Neural Convolucional- CNN)
vence a competição de reconhecimento de imagem imageNet, demonstrando o poder das
redes reurais profundas.
História e Evolução da IA
25.
▶ Anos 2010- 2020: IA Avançada e Aplicações Práticas
▶ 2012: A arquitetura de aprendizado profundo AlexNet (Rede Neural Convolucional- CNN)
vence a competição de reconhecimento de imagem imageNet, demonstrando o poder das
redes reurais profundas.
▶ 2016: AlphaGo, da DeepMind, derrota o campeão mundial de Go. um jogo conhecido pro
suas complexidade estratégica.
História e Evolução da IA
26.
▶ Anos 2010- 2020: IA Avançada e Aplicações Práticas
▶ 2012: A arquitetura de aprendizado profundo AlexNet (Rede Neural Convolucional- CNN)
vence a competição de reconhecimento de imagem imageNet, demonstrando o poder das
redes reurais profundas.
▶ 2016: AlphaGo, da DeepMind, derrota o campeão mundial de Go. um jogo conhecido pro
suas complexidade estratégica.
▶ 2017: O paper de pesquisa "Attention is All You Need"lança uma nova maneira de aprender
sequências com base em contexto, através da arquitetura de Transformadores e Módulo de
Atenção.
História e Evolução da IA
27.
▶ Anos 2020-2025: IA Avançada e Aplicações Práticas
▶ 2020: Vários Modelos baseados na arquitetura de Transformadores são propostos uma nova
geração de sistemas de IA, incluindo os modelos GPT.
História e Evolução da IA
28.
▶ Anos 2020-2025: IA Avançada e Aplicações Práticas
▶ 2020: Vários Modelos baseados na arquitetura de Transformadores são propostos uma nova
geração de sistemas de IA, incluindo os modelos GPT.
▶ 2021: IA é amplamente utilizada em diversas áreas, incluindo saúde, finanças, transporte e
entretenimento. Aumentam as preocupações éticas sobre privacidade, viés e impacto no
emprego.
História e Evolução da IA
29.
▶ Anos 2020-2025: IA Avançada e Aplicações Práticas
▶ 2020: Vários Modelos baseados na arquitetura de Transformadores são propostos uma nova
geração de sistemas de IA, incluindo os modelos GPT.
▶ 2021: IA é amplamente utilizada em diversas áreas, incluindo saúde, finanças, transporte e
entretenimento. Aumentam as preocupações éticas sobre privacidade, viés e impacto no
emprego.
▶ 2022: A OpenAI lança o ChatGPT e revela ao mundo a capacidade da IA Generativa(que já
existia antes do ChatGPT).
História e Evolução da IA
30.
▶ Anos 2020-2025: IA Avançada e Aplicações Práticas
▶ 2020: Vários Modelos baseados na arquitetura de Transformadores são propostos uma nova
geração de sistemas de IA, incluindo os modelos GPT.
▶ 2021: IA é amplamente utilizada em diversas áreas, incluindo saúde, finanças, transporte e
entretenimento. Aumentam as preocupações éticas sobre privacidade, viés e impacto no
emprego.
▶ 2022: A OpenAI lança o ChatGPT e revela ao mundo a capacidade da IA Generativa(que já
existia antes do ChatGPT).
▶ 2023: Começa a corrida para construir LLMs(Large Language Models) cada vez mais
poderosos. Desenvolvimento contínuo de IA em áreas como condução autônoma,
diagnóstico médico e assistentes pessoais inteligentes.
História e Evolução da IA
31.
▶ Anos 2020-2025: IA Avançada e Aplicações Práticas
▶ 2020: Vários Modelos baseados na arquitetura de Transformadores são propostos uma nova
geração de sistemas de IA, incluindo os modelos GPT.
▶ 2021: IA é amplamente utilizada em diversas áreas, incluindo saúde, finanças, transporte e
entretenimento. Aumentam as preocupações éticas sobre privacidade, viés e impacto no
emprego.
▶ 2022: A OpenAI lança o ChatGPT e revela ao mundo a capacidade da IA Generativa(que já
existia antes do ChatGPT).
▶ 2023: Começa a corrida para construir LLMs(Large Language Models) cada vez mais
poderosos. Desenvolvimento contínuo de IA em áreas como condução autônoma,
diagnóstico médico e assistentes pessoais inteligentes.
▶ 2024: A MetaAI lança o mais poderos LLM open-source com 405 bilhões de parâmetros.
História e Evolução da IA
32.
▶ Anos 2020-2025: IA Avançada e Aplicações Práticas
▶ 2020: Vários Modelos baseados na arquitetura de Transformadores são propostos uma nova
geração de sistemas de IA, incluindo os modelos GPT.
▶ 2021: IA é amplamente utilizada em diversas áreas, incluindo saúde, finanças, transporte e
entretenimento. Aumentam as preocupações éticas sobre privacidade, viés e impacto no
emprego.
▶ 2022: A OpenAI lança o ChatGPT e revela ao mundo a capacidade da IA Generativa(que já
existia antes do ChatGPT).
▶ 2023: Começa a corrida para construir LLMs(Large Language Models) cada vez mais
poderosos. Desenvolvimento contínuo de IA em áreas como condução autônoma,
diagnóstico médico e assistentes pessoais inteligentes.
▶ 2024: A MetaAI lança o mais poderos LLM open-source com 405 bilhões de parâmetros.
▶ 2025: Hangzhou DeepSeek Artificial Intelligence Co., Ltd, lançou (LLMs) de código aberto e
oferece serviços como geração de textos, análise de código e resolução de problemas
matemáticos.
História e Evolução da IA
33.
▶ Machine Learning(Aprendizado de Máquinas): Subcampo de IA que utiliza
algoritmos para aprender padrões a partir de dados e fazer previsões ou decisões sem ser
explicitamente programado para cada tarefa.
Técnicas Comuns de IA
34.
▶ Machine Learning(Aprendizado de Máquinas): Subcampo de IA que utiliza
algoritmos para aprender padrões a partir de dados e fazer previsões ou decisões sem ser
explicitamente programado para cada tarefa.
▶ Deep Learning (Aprendizado Profundo): Um tipo de Machine Learning que utiliza
redes artificiais com muitas camadas(redes neurais profundas) para modelar padrões
complexos em grandes quantidades de dados.
Técnicas Comuns de IA
35.
▶ Machine Learning(Aprendizado de Máquinas): Subcampo de IA que utiliza
algoritmos para aprender padrões a partir de dados e fazer previsões ou decisões sem ser
explicitamente programado para cada tarefa.
▶ Deep Learning (Aprendizado Profundo): Um tipo de Machine Learning que utiliza
redes artificiais com muitas camadas(redes neurais profundas) para modelar padrões
complexos em grandes quantidades de dados.
▶ Aprendizado por reforço: Subcampo da IA onde um agente aprende a tomar decisões
sequenciais interagindo com um ambiente. O agente recebe recompensas ou punições com
base nas ações que executa e seu objetivo é maximinizar a recompensa total ao longo do
tempo. Amplamente aplicado em áreas como robótica, jogos, controle de sistemas e robôs
de investimento.
Técnicas Comuns de IA
36.
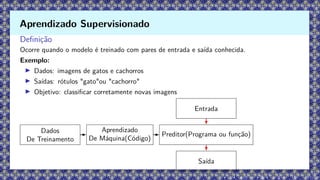
Definição
Ocorre quando omodelo é treinado com pares de entrada e saída conhecida.
Exemplo:
▶ Dados: imagens de gatos e cachorros
▶ Saídas: rótulos "gato"ou "cachorro"
▶ Objetivo: classificar corretamente novas imagens
Dados
De Treinamento
Aprendizado
De Máquina(Código)
Preditor(Programa ou função)
Saída
Entrada
Aprendizado Supervisionado
37.
Definição
O modelo identificapadrões sem que as saídas sejam fornecidas.
Exemplo:
▶ Agrupar clientes por hábitos de compra
▶ Detectar anomalias em sensores industriais
Aprendizado Não Supervisionado
38.
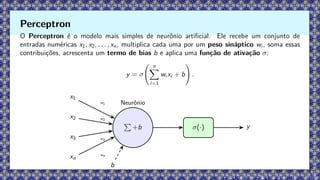
O Perceptron éo modelo mais simples de neurônio artificial. Ele recebe um conjunto de
entradas numéricas x1, x2, . . . , xn, multiplica cada uma por um peso sináptico wi , soma essas
contribuições, acrescenta um termo de bias b e aplica uma função de ativação σ:
y = σ
n
X
i=1
wi xi + b
!
.
x1
x2
x3
xn
P
+b
Neurônio
σ(·) y
b
w1
w2
w3
wn
Perceptron
39.
Uma função deativação é uma transformação não linear aplicada à combinação linear das
entradas de um neurônio.
Ela decide se o neurônio deve “ativar” ou não, permitindo que a rede aprenda relações complexas
e não lineares entre as variáveis de entrada.
Funções mais comuns
▶ Heaviside: σ(x) =
(
0, x < 0
1, x ≥ 0
▶ Sigmoid: σ(x) =
1
1 + e−x
▶ Tanh: σ(x) = tanh(x)
▶ ReLU: σ(x) = max(0, x)
Função de Ativação
40.
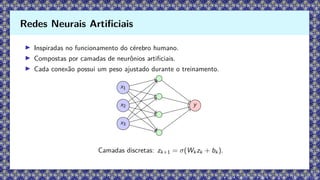
▶ Inspiradas nofuncionamento do cérebro humano.
▶ Compostas por camadas de neurônios artificiais.
▶ Cada conexão possui um peso ajustado durante o treinamento.
x1
x2
x3
y
Camadas discretas: zk+1 = σ(Wk zk + bk ).
Redes Neurais Artificiais
41.
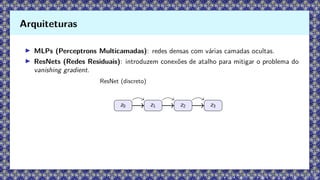
▶ MLPs (PerceptronsMulticamadas): redes densas com várias camadas ocultas.
▶ ResNets (Redes Residuais): introduzem conexões de atalho para mitigar o problema do
vanishing gradient.
ResNet (discreto)
z0 z1 z2 z3
Arquiteturas
42.
▶ ResNet block(discreto): zk+1 = zk + F(zk , Wk ).
▶ Esta forma sugere diferenciação temporal discreta e conduz ao limite contínuo
(∆t → 0).
▶ Motivação: evita degradação de gradiente em redes muito profundas (skip connections).
ResNet e conexões residuais
43.
Enunciado Clássico (Cybenko,1989)
Seja σ : R → R uma função de ativação contínua e não constante, limitada e monótona.
Então, para qualquer função contínua f definida em um compacto K ⊂ Rn
e para todo ε > 0,
existe uma rede neural de uma única camada oculta tal que:
f (x) −
N
X
j=1
αj σ(wj · x + bj ) < ε, ∀x ∈ K.
(Cybenko, 1989; Hornik et al., 1989)
Teorema da Aproximação Universal
44.
Exemplo
Função ReLU Seσ(u) = max(0, u) (ReLU), então a equação se torna:
dx(t)
dt
= W (t) max{0, A(t)x(t) + b(t)}.
Isso significa que a evolução do sistema depende de forma não linear das variáveis latentes:
apenas valores positivos após a transformação A(t)x(t) + b(t) contribuem para a dinâmica.
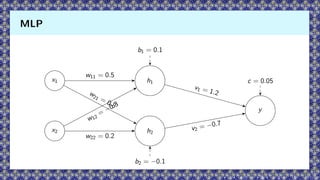
MLP exemplificando
45.
Exemplo
Exemplo de MLPcom ReLU Estrutura:
▶ Entrada: x = (1.0, 2.0)
▶ Camada escondida: 2 neurônios, ativação ReLU
▶ Saída: escalar, ativação identidade
Exemplo com ReLu
Considere um estadolatente vetorial, como a posição e velocidade de um sistema de partículas,
ou a concentração de substâncias químicas em uma reação.
Definição
dz
dt
= f (z, t). (1)
Normalmente resolvemos problemas de valor inicial: dado o estado em um instante t0, quere-
mos calcular o estado futuro em t1. Avaliar esse estado exatamente exige integrar a derivada ao
longo do tempo:
z(t1) = z(t0) +
Z t1
t0
f (z(t), t) dt. (2)
Revisão rápida de EDOs
50.
Na prática, essaintegral é aproximada numericamente. O solucionador mais simples é o método
de Euler, que dá passos na direção do gradiente:
zn+1 = zn + hf (zn, tn), (3)
onde h é o passo temporal.
Figura: Solver adaptativo.
Revisão rápida de EDOs
51.
As Redes Residuais(ResNets) podem ser vistas como aproximações discretas de sistemas
contínuos.
Um bloco residual pode ser escrito como:
hn+1 = hn + F(hn, θn), (4)
o que é análogo ao método de Euler.
Dessa forma, uma ResNet nada mais é do que um solucionador de EDO implícito, discretizado
em camadas.
EDOs Neural
52.
Definição (EDO Neural- Modelo Geral)
Seja z(t) ∈ Rn
o vetor de estado, e F(·, ·) : Rn
× R → Rn
uma função diferenciável
parametrizada por pesos θ. Define-se uma EDO Neural como:
dz(t)
dt
= F(z(t), t, θ), z(t0) = z0.
EDOs Neural
53.
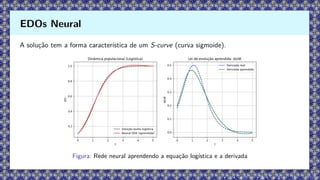
Exemplo 1: CrescimentoLogístico (saturação natural)
Consideremos a equação diferencial logística, que descreve o crescimento populacional limitado
por recursos ambientais:
dz
dt
= rz(1 − z), z(0) = z0, (5)
onde r 0 representa a taxa de crescimento.
A solução exata é dada por:
z(t) =
1
1 +
1
z0
− 1
e−rt
. (6)
EDOs Neural
54.
A solução tema forma característica de um S-curve (curva sigmoide).
Figura: Rede neural aprendendo a equação logística e a derivada
EDOs Neural
55.
Definição (EDO Neural- Forma Explícita)
Sejam A(t) ∈ Rm×n
, W (t) ∈ Rn×m
e b(t) ∈ Rm
funções contínuas no tempo. A EDO Neural
(Equação Diferencial Ordinária Neural) é definida por:
dx(t)
dt
= W (t) σ A(t)x(t) + b(t)
, x(0) = x0,
onde σ é uma função de ativação, como a ReLU.
EDOs Neural
56.
▶ O vetorx(t) ∈ Rn
representa o estado latente do sistema no instante t.
▶ A matriz A(t) atua como uma transformação linear inicial das variáveis de entrada.
▶ O vetor b(t) é o bias (ou termo de deslocamento), que desloca a saída da transformação
linear.
▶ A função de ativação σ (como ReLU, tanh, sigmoid) introduz não linearidade, permitindo
que o sistema represente dinâmicas mais complexas.
▶ A matriz W (t) combina as saídas após a ativação e determina como elas influenciam a
derivada dx
dt .
De forma geral, esta expressão é um caso particular de
dx(t)
dt
= f (x(t), t, θ),
onde θ = {A(t), W (t), b(t)} é o conjunto de parâmetros da rede.
EDOs Neural
57.
O objetivo dotreinamento de uma rede neural é ajustar os parâmetros θ para minimizar uma
função de custo (ou perda), geralmente definida como
L(θ) =
1
N
N
X
k=1
ℓ z(tk ; θ), yk
,
onde z(tk ; θ) é a solução da EDO neural no instante tk , e yk é o dado observado.
Para aplicar métodos de otimização (como gradiente descendente), precisamos do gradiente
∇θL.
Ou seja, para treinar redes neurais, precisamos calcular o gradiente da função objetivo em relação
aos parâmetros θ.
Treinamento da Rede
58.
▶ Fazer backpropagationdiretamente pelo solucionador é inviável devido ao alto custo de
memória e propagação de erros numéricos.
▶ A solução é o método do adjunto, que resolve outra EDO de sensibilidade para trás no
tempo onde a(t) é a variável adjunta.
Figura: Gradiente descendente.
Treinamento da Rede
59.
A solução éutilizar o método do adjunto, que evita guardar a trajetória completa e permite
calcular o gradiente com custo de memória constante.
A ideia central é resolver uma segunda EDO (para trás no tempo), chamada EDO adjunta:
da(t)
dt
= −a(t)⊤ ∂F
∂h
(h(t), t, θ),
onde a(t) é a variável adjunta que acumula a sensibilidade da perda em relação ao estado h(t).
Ideia do Método
60.
1. Definição doproblema: Começamos com a dinâmica
dz
dt
= F(z(t), t, θ), z(0) = z0.
A perda depende de z(T) ou de pontos intermediários z(tk ).
2. Introdução da adjunta: Definimos a variável adjunta a(t) = ∂L
∂z(t) .
3. EDO adjunta: Mostra-se que a(t) satisfaz a equação diferencial
da(t)
dt
= −a(t)⊤ ∂F
∂z
(z(t), t, θ).
Passo a Passo
61.
1. Essa equaçãoé resolvida de trás para frente, a partir da condição final
a(T) =
∂L
∂z(T)
.
2. Gradiente em relação aos parâmetros: Enquanto resolvemos a(t), também podemos
acumular a derivada em relação a θ:
dL
dθ
= −
Z 0
T
a(t)⊤ ∂F
∂θ
(z(t), t, θ) dt.
3. Iteração do treinamento: Com o gradiente ∇θL em mãos, atualizamos os parâmetros
via gradiente descendente:
θ ← θ − η ∇θL(θ).
Treinamento da Rede
62.
▶ Memória constante:não é preciso armazenar todos os estados intermediários da solução.
▶ Generalidade: o método se aplica a qualquer solver de EDO (Runge-Kutta, métodos
implícitos, etc.).
▶ Relação com controle ótimo: o método do adjunto é análogo ao Princípio do Mínimo
de Pontryagin em teoria de controle, onde variáveis adjuntas surgem naturalmente.
Vantagens do Método
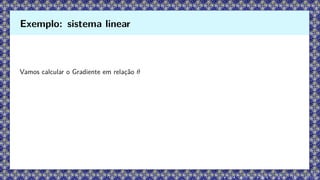
Considere a EDO
dz
dt
=θz, z(0) = z0, θ ∈ R.
A solução explícita(forward) é
z(t) = z0eθt
, z(T) = z0eθT
.
Exemplo: sistema linear
65.
Considere a EDO
dz
dt
=θz, z(0) = z0, θ ∈ R.
A solução explícita(forward) é
z(t) = z0eθt
, z(T) = z0eθT
.
Escolhemos a perda
L = 1
2 z(T) − ztarget
2
.
Exemplo: sistema linear
Vamos calcular oGradiente em relação θ
dL
dθ
=
dL
dz(T)
·
dZ(T)
dθ
= (z(T) − ztarget) · z0TeθT
= (z(T) − ztarget) T z(T),
pois, z(T) = z0eθT
Exemplo: sistema linear
68.
A equação doadjunto no caso escalar é
da
dt
= −
∂F
∂z
a(t) = −θ a(t).
Exemplo: sistema linear
69.
A equação doadjunto no caso escalar é
da
dt
= −
∂F
∂z
a(t) = −θ a(t).
A solução integrada para trás (backward), escrita em forma fechada é
a(t) = a(T) eθ(T−t)
.
Exemplo: sistema linear
70.
A equação doadjunto no caso escalar é
da
dt
= −
∂F
∂z
a(t) = −θ a(t).
A solução integrada para trás (backward), escrita em forma fechada é
a(t) = a(T) eθ(T−t)
.
Além disso,
∂F
∂θ
(z, t, θ) = z(t).
Exemplo: sistema linear
71.
A equação doadjunto no caso escalar é
da
dt
= −
∂F
∂z
a(t) = −θ a(t).
A solução integrada para trás (backward), escrita em forma fechada é
a(t) = a(T) eθ(T−t)
.
Além disso,
∂F
∂θ
(z, t, θ) = z(t).
Portanto, o gradiente em relação a θ é
dL
dθ
=
Z T
0
a(t)
∂F
∂θ
(z(t), t, θ) dt =
Z T
0
a(T) eθ(T−t)
· z0eθt
dt.
Exemplo: sistema linear
72.
Simplificando:
dL
dθ
= a(T) z0eθT
ZT
0
dt = a(T) z0eθT
T.
Como a(T) = z(T) − ztarget e z0eθT
= z(T), obtemos finalmente
dL
dθ
= z(T) − ztarget
T z(T).
Resultado coincide com o gradiente direto.
Exemplo: sistema linear
73.
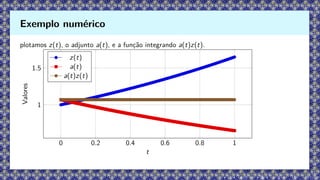
Consideremos a EDOlinear
dz
dt
= θz, z(0) = z0,
com z0 = 1, θ = 0.5 e horizonte T = 1. A solução explícita é z(t) = z0eθt
. Tomamos função
de perda
L(θ) = 1
2 z(T) − yT
2
,
com yT = 1.0. Defina a(t) = ∂L/∂z(t). Tem-se a(T) = z(T) − yT e
da
dt
= −θ a(t).
O gradiente em relação a θ é
dL
dθ
=
Z T
0
a(t) z(t) dt.
Exemplo numérico
74.
plotamos z(t), oadjunto a(t), e a função integrando a(t)z(t).
0 0.2 0.4 0.6 0.8 1
1
1.5
t
Valores
z(t)
a(t)
a(t)z(t)
Exemplo numérico
75.
A integral numéricaaproximada de a(t)z(t) em [0, T] (regra do trapézio) fornece o gradiente:
c
dL
dθ
= 1.072248e + 00
O valor analítico é dado por
dL
dθ
= (z(T) − yT ) z(T) T = 1.069561e + 00.
Exemplo numérico
Definição (Sistema LinearControlável)
Considere o sistema:
dx(t)
dt
= Ax(t) + Bu(t).
Diz-se que o sistema é controlável se, para todo par x0, xT , existe u(·) tal que x(0) = x0 e
x(T) = xT .
Aprendizagem supervisionada por controle
78.
Teorema (Kalman)
O sistemaé controlável se e somente se a matriz de controlabilidade:
C = [B AB A2
B · · · An−1
B]
tem posto completo, isto é, rank(C) = n.
Aprendizagem supervisionada por controle
79.
Considere o sistemalinear:
d
dt
x(t) = Ax(t) + Bu(t),
com
A =
0 1
0 0
, B =
0
1
.
Exemplo de Sistema Linear Controlável
80.
Considere o sistemalinear:
d
dt
x(t) = Ax(t) + Bu(t),
com
A =
0 1
0 0
, B =
0
1
.
Matriz de controlabilidade:
C =
B AB
.
Exemplo de Sistema Linear Controlável
81.
Considere o sistemalinear:
d
dt
x(t) = Ax(t) + Bu(t),
com
A =
0 1
0 0
, B =
0
1
.
Matriz de controlabilidade:
C =
B AB
.
Calculando:
AB =
0 1
0 0
0
1
=
1
0
, C =
0 1
1 0
.
Exemplo de Sistema Linear Controlável
82.
Considere o sistemalinear:
d
dt
x(t) = Ax(t) + Bu(t),
com
A =
0 1
0 0
, B =
0
1
.
Matriz de controlabilidade:
C =
B AB
.
Calculando:
AB =
0 1
0 0
0
1
=
1
0
, C =
0 1
1 0
.
Como det(C) = −1 ̸= 0, temos posto completo (2).
Exemplo de Sistema Linear Controlável
83.
Considere o sistemalinear:
d
dt
x(t) = Ax(t) + Bu(t),
com
A =
0 1
0 0
, B =
0
1
.
Matriz de controlabilidade:
C =
B AB
.
Calculando:
AB =
0 1
0 0
0
1
=
1
0
, C =
0 1
1 0
.
Como det(C) = −1 ̸= 0, temos posto completo (2).
Conclusão: o sistema é controlável.
Exemplo de Sistema Linear Controlável
84.
Considere o sistemafísico massa–mola (sem amortecimento):
mẍ(t) = u(t),
onde x(t) é a posição e u(t) é a força aplicada.
Sistema Massa–Mola como Sistema Contro-
lável
85.
Considere o sistemafísico massa–mola (sem amortecimento):
mẍ(t) = u(t),
onde x(t) é a posição e u(t) é a força aplicada.
Definindo x1(t) = x(t) e x2(t) = ẋ(t), obtemos:
x(t) =
x1(t)
x2(t)
, ẋ(t) =
0 1
0 0
x(t) +
0
1
m
u(t).
Sistema Massa–Mola como Sistema Contro-
lável
86.
Considere o sistemafísico massa–mola (sem amortecimento):
mẍ(t) = u(t),
onde x(t) é a posição e u(t) é a força aplicada.
Definindo x1(t) = x(t) e x2(t) = ẋ(t), obtemos:
x(t) =
x1(t)
x2(t)
, ẋ(t) =
0 1
0 0
x(t) +
0
1
m
u(t).
Este é exatamente o sistema do exemplo anterior, portanto é controlável.
Sistema Massa–Mola como Sistema Contro-
lável
87.
Associamos o sistemaadjunto:
−p′
(t) = A∗
p(t), p(T) = pT .
A solução é:
p(t) = eA∗
(T−t)
pT , 0 ≤ t ≤ T.
Escolhemos o controle:
u(t) = B∗
p(t) = B∗
eA∗
(T−t)
pT .
Sistema Adjunto
88.
A solução dex(t) é dada por:
x(T) = eAT
x0 +
Z T
0
eA(T−s)
Bu(s) ds.
Substituindo u(s) = B∗
eA∗
(T−s)
pT :
x(T) = eAT
x0 +
Z T
0
eA(T−s)
BB∗
eA∗
(T−s)
ds
!
pT .
Gramiana de Controlabilidade
WT =
Z T
0
eAs
BB∗
eA∗
s
ds.
A condição de alcance é:
WT pT = xT − eAT
x0.
Estado Final e Gramiana de Controlabilidade
89.
Queremos minimizar aenergia do controle:
J(pT ) =
1
2
Z T
0
∥u(t)∥2
dt =
1
2
Z T
0
∥B∗
p(t)∥2
dt.
Substituindo p(t) = eA∗
(T−t)
pT :
J(pT ) =
1
2
p⊤
T
Z T
0
eA(T−s)
BB∗
eA∗
(T−s)
ds
!
pT =
1
2
p⊤
T WT pT .
Funcional a Minimizar
90.
Minimizamos J(pT )sujeito à restrição
WT pT = xT − eAT
x0.
Se WT é inversível (sistema controlável), temos:
pT = W −1
T xT − eAT
x0
.
O controle ótimo é:
u∗
(t) = B∗
eA∗
(T−t)
W −1
T xT − eAT
x0
.
Solução do Problema de Mínima Energia
91.
A energia mínimaé dada por:
Jmin =
1
2
(xT − eAT
x0)⊤
W −1
T (xT − eAT
x0) .
▶ WT inversível ⇐⇒ o sistema é controlável.
▶ A lei de controle u∗
(t) = B∗
p(t) fornece o controle de menor energia.
▶ O vetor adjunto p(t) carrega a informação “dual” da dinâmica.
Energia Mínima e Interpretação
92.
Para realizarmos ocontrole de Aprendizado Supervisionado podemos fazer das seguintes formas,
por exemplo:
1. Treinamento da Rede Neural
2. Controle simultâneo ou por conjunto de EDOs Neurais
Controle em EDO Neural
93.
Para realizarmos ocontrole de Aprendizado Supervisionado podemos fazer das seguintes formas,
por exemplo:
1. Treinamento da Rede Neural
2. Controle simultâneo ou por conjunto de EDOs Neurais
Decorre que podemos fazer a seguinte mudança:
fθ ≈
n
X
j=1
wk σ(aj · x + bj ) ⇔ xk+1 = xk + hwk σ(ak · x + bk )
⇔
dx(t)
dt
= W (t)σ(A(t)x(t) + b(t)). (7)
Controle em EDO Neural
94.
Definição (Treinamento daRede Neural)
Seja f : Rn
× Rm
× [0, T] → Rn
um campo vetorial contínuo e Lipschitz em x, e considere o
sistema controlado
ẋ(t) = f (x(t), u(t), t), x(0) = x0.
Um controle neural é uma função u(t) = hθ(x(t), t) parametrizada por uma rede neural, e uma
aproximação neural da dinâmica é uma função gγ(x, u, t) tal que gγ ≈ f quando a rede é
suficientemente expressiva.
Controle em EDO Neural
95.
x1
x2
Alvo
x∗
(T)
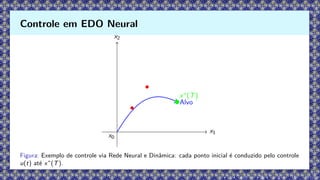
x0
Figura: Exemplo decontrole via Rede Neural e Dinâmica: cada ponto inicial é conduzido pelo controle
u(t) até x∗
(T).
Controle em EDO Neural
96.
Considere o sistemamassa–mola controlado por uma força u(t):
ẋ1(t) = x2(t), ẋ2(t) = −kx1(t) + u(t), x(0) = x0 =
1
0
,
onde x1 é a posição, x2 é a velocidade e k 0 é a constante da mola.
Exemplo Controlado Neural
97.
Controle Neural: parametrizamosu(t) por uma rede neural:
u(t) = hθ(x(t), t), hθ(x, t) = w1 tanh(w2x1 + w3x2 + w4t),
com parâmetros θ = {w1, w2, w3, w4} aprendidos.
Exemplo: Controlando a Rede Neural
98.
Controle Neural: parametrizamosu(t) por uma rede neural:
u(t) = hθ(x(t), t), hθ(x, t) = w1 tanh(w2x1 + w3x2 + w4t),
com parâmetros θ = {w1, w2, w3, w4} aprendidos.
Aproximação Neural da Dinâmica: aproximamos o campo vetorial f (x, u, t) por uma rede
neural gγ(x, u, t):
f (x, u, t) =
x2
−kx1 + u
≈ gγ(x, u, t) =
σ(a1x1 + a2x2 + a3u + a4t)
σ(b1x1 + b2x2 + b3u + b4t)
,
onde σ é uma função de ativação e γ = {ai , bi } são os parâmetros da rede.
Exemplo: Controlando a Rede Neural
99.
Controle Neural: parametrizamosu(t) por uma rede neural:
u(t) = hθ(x(t), t), hθ(x, t) = w1 tanh(w2x1 + w3x2 + w4t),
com parâmetros θ = {w1, w2, w3, w4} aprendidos.
Aproximação Neural da Dinâmica: aproximamos o campo vetorial f (x, u, t) por uma rede
neural gγ(x, u, t):
f (x, u, t) =
x2
−kx1 + u
≈ gγ(x, u, t) =
σ(a1x1 + a2x2 + a3u + a4t)
σ(b1x1 + b2x2 + b3u + b4t)
,
onde σ é uma função de ativação e γ = {ai , bi } são os parâmetros da rede.
Interpretação:
▶ O sistema físico é controlado por u(t)
▶ hθ aprende a força ideal para atingir objetivos.
▶ gγ aproxima a dinâmica real, mesmo que f não seja conhecida explicitamente.
Exemplo: Controlando a Rede Neural
100.
Teorema (Controle viaTreinamento da Rede Neural)
Dado um alvo x∗
(T) ∈ Rn
e ε 0, existe uma rede neural de controle hθ e uma rede de
dinâmica gγ tal que a solução do sistema aproximado
˙
x̂(t) = gγ(x̂(t), hθ(x̂(t), t), t), x̂(0) = x0,
satisfaz
∥x̂(T) − x∗
(T)∥ ε.
Além disso, se f ∈ Ck
, pode-se garantir gγ → f em norma Ck
localmente, com redes
suficientemente expressivas.
Controlado Neural
101.
Demonstração.
A prova seguedo teorema de universalidade das redes neurais:
1. Aproximação da dinâmica: Como f é contínua (ou Ck
), pelo teorema universal de
aproximação existe uma rede neural gγ tal que, para qualquer δ 0,
sup
x,u,t∈K
∥gγ(x, u, t) − f (x, u, t)∥ δ,
em qualquer compacto K ⊂ Rn
× Rm
× [0, T].
Controlado Neural
102.
Demonstração.
A prova seguedo teorema de universalidade das redes neurais:
1. Aproximação da dinâmica: Como f é contínua (ou Ck
), pelo teorema universal de
aproximação existe uma rede neural gγ tal que, para qualquer δ 0,
sup
x,u,t∈K
∥gγ(x, u, t) − f (x, u, t)∥ δ,
em qualquer compacto K ⊂ Rn
× Rm
× [0, T].
2. Aproximação do controle: Queremos um controle u(t) que leve x(t) ao alvo x∗
(T). Por
resultados de controle ótimo e existência de soluções para EDOs Lipschitz, existe uma função
contínua u∗
(t) que alcança o alvo. Pelo teorema universal, existe uma rede neural hθ que
aproxima u∗
(t) arbitrariamente bem em norma L∞
.
Controlado Neural
103.
Demonstração.
3. Dinâmica aproximadacom controle neural: Se escolhermos δ suficientemente pequeno
na aproximação de f e hθ ≈ u∗
, a solução x̂(t) do sistema aproximado satisfaz, por
estabilidade de EDOs Lipschitz:
∥x̂(T) − x∗
(T)∥ ε,
para qualquer ε 0.
Controlado Neural
104.
Demonstração.
3. Dinâmica aproximadacom controle neural: Se escolhermos δ suficientemente pequeno
na aproximação de f e hθ ≈ u∗
, a solução x̂(t) do sistema aproximado satisfaz, por
estabilidade de EDOs Lipschitz:
∥x̂(T) − x∗
(T)∥ ε,
para qualquer ε 0.
4. Regularidade: Se f ∈ Ck
, a aproximação gγ pode ser feita também em norma Ck
,
garantindo que derivadas até ordem k do sistema aproximado se aproximem de f .
Portanto, com redes suficientemente expressivas, é possível projetar um controle neural que
leva a dinâmica aproximada arbitrariamente perto do alvo.
Controlado Neural
105.
Considere o sistemadinâmico controlado em R2
:
ẋ1(t) = −x2(t) + u1(t),
ẋ2(t) = x2
1 (t) − x2(t) + u2(t),
x(0) = x0 = (0, 0),
(8)
onde u(t) = (u1(t), u2(t)) é o controle.
Objetivo: Determinar analiticamente uma lei de controle u(t) que leve o estado até x∗
(T) =
(2, 1) no tempo final T = 3 e discutir a aplicação do teorema de controle neural.
Exercício de Aplicação
106.
A equação (8)é não-linear devido ao termo x2
1 . Para obter uma solução analítica aproximada,
linearizamos o sistema em torno do ponto inicial x0 = (0, 0):
x2
1 ≈ 0 (primeira ordem).
Assim, o sistema linearizado é:
ẋ(t) ≈ Ax(t) + Bu(t),
onde
x =
x1
x2
, u =
u1
u2
, A =
0 −1
0 −1
, B = I2.
O sistema linearizado é controlável (det([B, AB]) ̸= 0), então podemos usar realimentação para
garantir x(T) = x∗
(T).
Assumimos uma trajetória desejada xd (t) conectando x0 a x∗
(T) linearmente:
Solução Analítica – 1. Linearização Local
107.
xd (t) =x0 +
t
T
(x∗
(T) − x0) =
t
T
2
1
=
2t
3
t
3
.
A derivada da trajetória desejada é:
ẋd (t) =
2
3
1
3
.
Uma lei de controle que força x(t) = xd (t) é:
u(t) = ẋd (t) − Axd (t),
ou seja:
u1(t) =
2
3
− (0 · x1 − 1 · x2) =
2
3
+ x2(t) =
2
3
+
t
3
,
u2(t) =
1
3
− (0 · x1 − 1 · x2) =
1
3
+ x2(t) =
1
3
+
t
3
.
Solução Analítica – 2. Lei de Controle
108.
Substituindo u(t) nosistema linearizado:
ẋ1 = −x2 + u1 = −
t
3
+
2
3
+
t
3
=
2
3
, ẋ2 = −x2 + u2 = −
t
3
+
1
3
+
t
3
=
1
3
.
Integrando:
x1(t) =
Z t
0
2
3
dt =
2t
3
, x2(t) =
Z t
0
1
3
dt =
t
3
.
No tempo final T = 3:
x1(3) = 2, x2(3) = 1,
ou seja, o alvo é atingido exatamente.
Solução Analítica – 3. Solução do Sistema
Linearizado
109.
Na implementação numérica,as redes gγ e hθ podem ser treinadas para reproduzir essa trajetória,
aproximando o sistema não-linear original, incluindo o termo x2
1 , e garantindo a convergência até
x∗
(T).
Figura: Controle de Rede Neural
Ilustração
110.
Motivação:
Uma das ideiascentrais em EDOs Neural com Controle (NODEC) é que problemas de classifica-
ção supervisionada podem ser reinterpretados como problemas de controle ótimo. Cada ponto
de dados é tratado como um estado inicial de uma dinâmica contínua, e o objetivo é guiá-lo até
uma região do espaço correspondente à sua classe.
Classificação via Controle em EDOs Neurais
111.
Teorema (Classificação porControle Simultâneo de EDOs Neurais)
Em dimensão d ≥ 2, dado um horizonte de tempo [0, T], é possível conduzir um número finito
de itens arbitrários {x0
1 , . . . , x0
N} ⊂ Rd
a subconjuntos abertos predefinidos {Ω1, . . . , ΩN} ⊂ Rd
,
correspondentes às suas classes, por meio de controles em partes constantes.
Ou seja, existe uma função de controle por partes u(t) ∈ Upw tal que, para cada i = 1, . . . , N,
a solução da dinâmica
ẋi (t) = fθ(xi (t), u(t)), xi (0) = x0
i ,
satisfaz
xi (T) ∈ Ωi .
Classificação via Controle em EDOs Neurais
112.
Este resultado garanteque uma EDO Neural com controle pode atuar como um classificador
universal. Cada dado inicial x0
i segue uma trajetória dinâmica até cair na região Ωi associada à
sua classe.
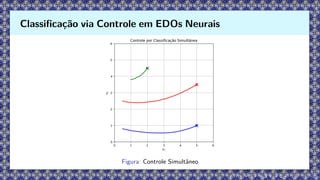
Ω1
Ω2
Ω3
x0
1
x0
2
x0
3
Figura: Exemplo de classificação dinâmica: cada ponto inicial é conduzido pelo controle u(t) até a
região correspondente à sua classe.
Classificação via Controle em EDOs Neurais
113.
Demonstração.
▶ O espaçode controles Upw é suficientemente rico para guiar os estados.
▶ O sistema é controlável em pedaços, pois em cada intervalo de tempo o controle u(t)
direciona o fluxo das partículas.
▶ A concatenação de intervalos de controle permite separar as trajetórias de cada xi ,
enviando-as às regiões-alvo.
▶ A demonstração rigorosa usa resultados de controlabilidade de sistemas bilineares e
propriedades de universalidade das redes neurais.
OBs: Este teorema mostra que problemas clássicos de classificação supervisionada podem ser
reescritos como problemas de controle simultâneo em sistemas dinâmicos. Isso abre caminho
para novos algoritmos híbridos, onde técnicas de controle ótimo e aprendizado profundo se
unem.
Classificação via Controle em EDOs Neurais
114.
Exemplo
Considere
▶ x(t) ∈R2
: estado do sistema
▶ u(t) ∈ R2
: controle aplicado
dx(t)
dt
= fθ(x(t), u(t)), x(0) = x0
Neural ODE: a função fθ é parametrizada por uma rede neural:
fθ(x, u) = W2 σ
W1
x(t)
u(t)
+ b1
+ b2
Classificação via Controle em EDOs Neurais
115.
▶ x0 =[0.5, 0.8], [0.5, 2.5], [1.0, 3.8]
▶ [x; u] ∈ R4
: concatenação estado-controle
▶ W1 ∈ Rh×4
, b1 ∈ Rh
: pesos e bias da camada oculta
▶ W2 ∈ R2×h
, b2 ∈ R2
: pesos e bias da camada de saída
▶ σ = tanh : função de ativação não-linear
▶ h = 32 no código
Resumo: a dinâmica do sistema depende do estado e do controle de forma não-linear e aprendida
pela rede neural. O controle u(t) será otimizado para levar x(t) até os alvos desejados.
Classificação via Controle em EDOs Neurais
Chen, R. T.Q.; Rubanova, Y.; Bettencourt, J.; Duvenaud, D.
Neural Ordinary Differential Equations. Advances in NeurIPS, 31:6571–6583, 2018.
Chi, C.
NODEC: Neural ODE for Optimal Control of Unknown Dynamical Systems. arXiv:2401.01836v1, 2024.
Geshkovski, B.; Zuazua, E.
Turnpike in Optimal Control of PDEs, ResNets, and Beyond. Acta Numerica, 31:135–263, 2022.
Jin, W.; Wang, Z.; Yang, Z.; Mou, S.
Pontryagin Differentiable Programming: An End-to-End Learning and Control Framework. Proc. NeurIPS, 2020.
Kidger, P.; Morrill, J.; Foster, J.; Lyons, T.
Neural Controlled Differential Equations for Irregular Time Series. Advances in NeurIPS, 2020. arXiv:2005.08926.
Ruiz-Balet, D.; Zuazua, E.
Neural ODE Control for Classification, Approximation, and Transport. SIAM Review, 65(3):735–773, 2023.
Turing, A.
Computing Machinery and Intelligence. Mind, 59(236), 433–460, 1950.
Referências











































![Exemplo
y = W (2)
h + b(2)
= [1.2 − 0.7]
0.0
1.1
+ 0.05
y = 1.2 · 0.0 + (−0.7) · 1.1 + 0.05
y = −0.72
Resultado final: para x = (1.0, 2.0), a rede retorna y ≈ −0.72.
Passo 2 – Saída](https://image.slidesharecdn.com/minicursoufca-251219143011-73d88bbb/85/Minicurso-Introducao-ao-Controle-e-machine-Learning-47-320.jpg)























![A integral numérica aproximada de a(t)z(t) em [0, T] (regra do trapézio) fornece o gradiente:
c
dL
dθ
= 1.072248e + 00
O valor analítico é dado por
dL
dθ
= (z(T) − yT ) z(T) T = 1.069561e + 00.
Exemplo numérico](https://image.slidesharecdn.com/minicursoufca-251219143011-73d88bbb/85/Minicurso-Introducao-ao-Controle-e-machine-Learning-75-320.jpg)

![Teorema (Kalman)
O sistema é controlável se e somente se a matriz de controlabilidade:
C = [B AB A2
B · · · An−1
B]
tem posto completo, isto é, rank(C) = n.
Aprendizagem supervisionada por controle](https://image.slidesharecdn.com/minicursoufca-251219143011-73d88bbb/85/Minicurso-Introducao-ao-Controle-e-machine-Learning-78-320.jpg)















![Definição (Treinamento da Rede Neural)
Seja f : Rn
× Rm
× [0, T] → Rn
um campo vetorial contínuo e Lipschitz em x, e considere o
sistema controlado
ẋ(t) = f (x(t), u(t), t), x(0) = x0.
Um controle neural é uma função u(t) = hθ(x(t), t) parametrizada por uma rede neural, e uma
aproximação neural da dinâmica é uma função gγ(x, u, t) tal que gγ ≈ f quando a rede é
suficientemente expressiva.
Controle em EDO Neural](https://image.slidesharecdn.com/minicursoufca-251219143011-73d88bbb/85/Minicurso-Introducao-ao-Controle-e-machine-Learning-94-320.jpg)





![Demonstração.
A prova segue do teorema de universalidade das redes neurais:
1. Aproximação da dinâmica: Como f é contínua (ou Ck
), pelo teorema universal de
aproximação existe uma rede neural gγ tal que, para qualquer δ 0,
sup
x,u,t∈K
∥gγ(x, u, t) − f (x, u, t)∥ δ,
em qualquer compacto K ⊂ Rn
× Rm
× [0, T].
Controlado Neural](https://image.slidesharecdn.com/minicursoufca-251219143011-73d88bbb/85/Minicurso-Introducao-ao-Controle-e-machine-Learning-101-320.jpg)
![Demonstração.
A prova segue do teorema de universalidade das redes neurais:
1. Aproximação da dinâmica: Como f é contínua (ou Ck
), pelo teorema universal de
aproximação existe uma rede neural gγ tal que, para qualquer δ 0,
sup
x,u,t∈K
∥gγ(x, u, t) − f (x, u, t)∥ δ,
em qualquer compacto K ⊂ Rn
× Rm
× [0, T].
2. Aproximação do controle: Queremos um controle u(t) que leve x(t) ao alvo x∗
(T). Por
resultados de controle ótimo e existência de soluções para EDOs Lipschitz, existe uma função
contínua u∗
(t) que alcança o alvo. Pelo teorema universal, existe uma rede neural hθ que
aproxima u∗
(t) arbitrariamente bem em norma L∞
.
Controlado Neural](https://image.slidesharecdn.com/minicursoufca-251219143011-73d88bbb/85/Minicurso-Introducao-ao-Controle-e-machine-Learning-102-320.jpg)



![A equação (8) é não-linear devido ao termo x2
1 . Para obter uma solução analítica aproximada,
linearizamos o sistema em torno do ponto inicial x0 = (0, 0):
x2
1 ≈ 0 (primeira ordem).
Assim, o sistema linearizado é:
ẋ(t) ≈ Ax(t) + Bu(t),
onde
x =
x1
x2
, u =
u1
u2
, A =
0 −1
0 −1
, B = I2.
O sistema linearizado é controlável (det([B, AB]) ̸= 0), então podemos usar realimentação para
garantir x(T) = x∗
(T).
Assumimos uma trajetória desejada xd (t) conectando x0 a x∗
(T) linearmente:
Solução Analítica – 1. Linearização Local](https://image.slidesharecdn.com/minicursoufca-251219143011-73d88bbb/85/Minicurso-Introducao-ao-Controle-e-machine-Learning-106-320.jpg)




![Teorema (Classificação por Controle Simultâneo de EDOs Neurais)
Em dimensão d ≥ 2, dado um horizonte de tempo [0, T], é possível conduzir um número finito
de itens arbitrários {x0
1 , . . . , x0
N} ⊂ Rd
a subconjuntos abertos predefinidos {Ω1, . . . , ΩN} ⊂ Rd
,
correspondentes às suas classes, por meio de controles em partes constantes.
Ou seja, existe uma função de controle por partes u(t) ∈ Upw tal que, para cada i = 1, . . . , N,
a solução da dinâmica
ẋi (t) = fθ(xi (t), u(t)), xi (0) = x0
i ,
satisfaz
xi (T) ∈ Ωi .
Classificação via Controle em EDOs Neurais](https://image.slidesharecdn.com/minicursoufca-251219143011-73d88bbb/85/Minicurso-Introducao-ao-Controle-e-machine-Learning-111-320.jpg)



![▶ x0 = [0.5, 0.8], [0.5, 2.5], [1.0, 3.8]
▶ [x; u] ∈ R4
: concatenação estado-controle
▶ W1 ∈ Rh×4
, b1 ∈ Rh
: pesos e bias da camada oculta
▶ W2 ∈ R2×h
, b2 ∈ R2
: pesos e bias da camada de saída
▶ σ = tanh : função de ativação não-linear
▶ h = 32 no código
Resumo: a dinâmica do sistema depende do estado e do controle de forma não-linear e aprendida
pela rede neural. O controle u(t) será otimizado para levar x(t) até os alvos desejados.
Classificação via Controle em EDOs Neurais](https://image.slidesharecdn.com/minicursoufca-251219143011-73d88bbb/85/Minicurso-Introducao-ao-Controle-e-machine-Learning-115-320.jpg)





![[OFICIAL] Grupo #8 - Inteligência Artificial.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/oficialgrupo8-intelignciaartificial-250829005537-a41f4694-thumbnail.jpg?width=640&height=640&fit=bounds)











































