Baixar para ler offline





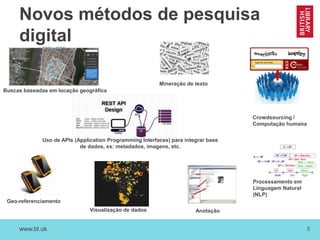


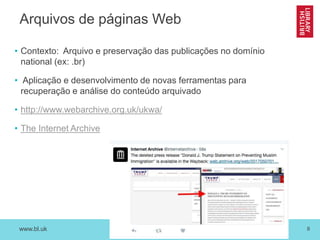

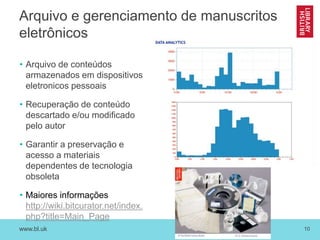






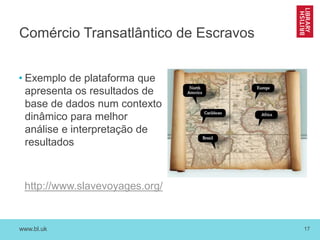







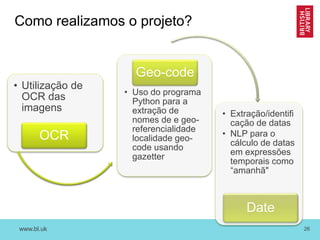


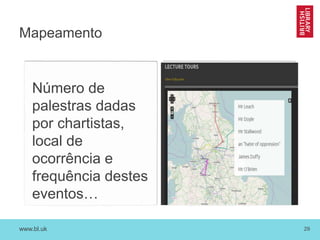
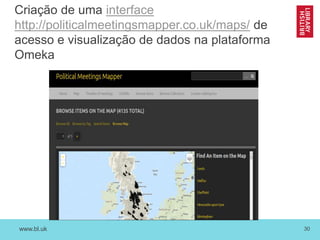
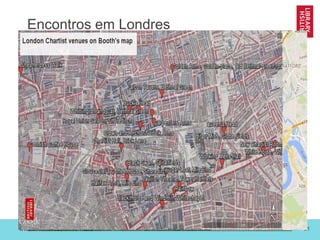




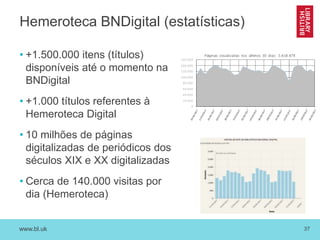



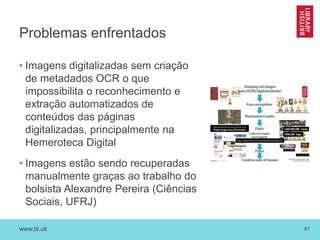





O documento discute as novas funções das instituições de memória cultural no século 21, incluindo a digitalização, preservação e disponibilização de acervos digitais, a promoção de pesquisa digital e o papel das bibliotecas como centros de capacitação. Também resume vários projetos digitais que utilizam novas tecnologias como reconhecimento óptico de caracteres, georreferenciamento e crowdsourcing para analisar e disponibilizar acervos históricos.



















































