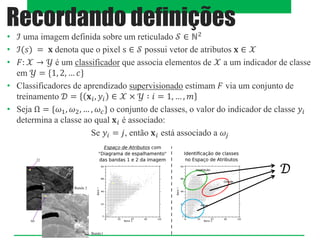
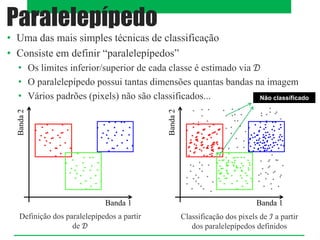
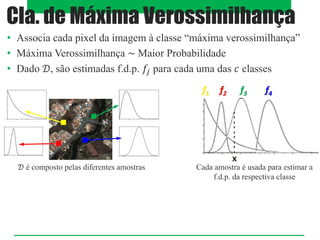
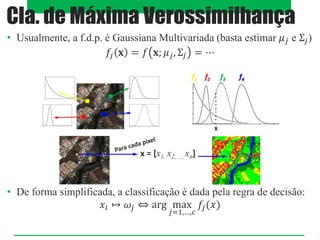
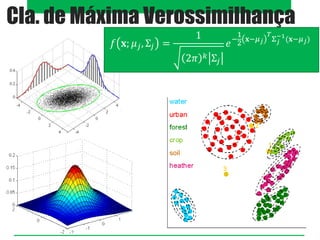
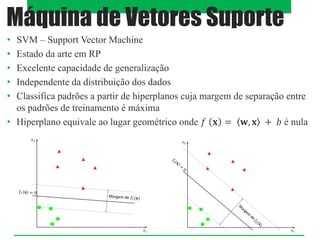
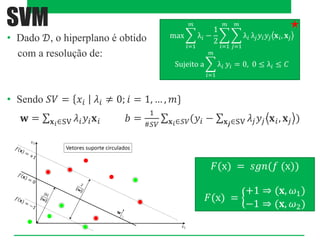
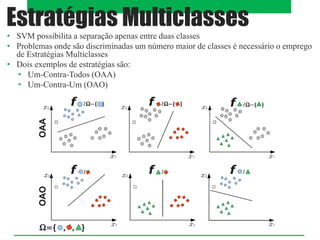
O documento aborda classificadores de aprendizado supervisionado, destacando técnicas como paralelepípedos, mínima distância e máxima verossimilhança para classificar pixels em imagens. Também menciona o método k-vizinhos mais próximos e a utilização de máquinas de vetores de suporte (SVM) para categorizar padrões com máxima margem de separação. Estratégias multiclasses são discutidas, incluindo abordagens como um-contra-todos e um-contra-um.



![• Realiza a classificação segundo exemplos (conjunto de
treinamento) mais próximos [segundo uma métrica] no
espaço de atributos
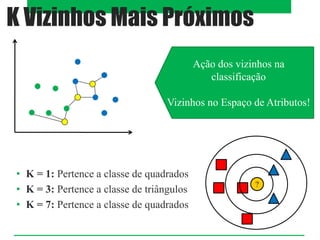
K Vizinhos Mais Próximos
?
i. Definir o número de vizinhos mais próximos (𝐾)
ii. Calcular a distância entre o exemplo
desconhecido e os exemplos do conjunto de
treino
iii. Identificar os 𝐾 vizinhos mais próximos
iv. Utilizar o rótulo da classe dos vizinhos mais
próximos que é mais frequente para determinar o
rótulo da classe do exemplo desconhecido](https://image.slidesharecdn.com/aula17-classsupervisionada-241203204819-919a63b8/85/AULA-SVM-Primeira-aplicacao-Supervisionada-8-320.jpg)










![[José Ahirton Lopes] Support Vector Machines](https://cdn.slidesharecdn.com/ss_thumbnails/joseahirtonlopes-apresentacaosupportvectormachines-180326014519-thumbnail.jpg?width=640&height=640&fit=bounds)



![[José Ahirton Lopes] Treinamento - Árvores de Decisão, SVM e Naive Bayes](https://cdn.slidesharecdn.com/ss_thumbnails/treinamentodeveloperssp-180611021639-thumbnail.jpg?width=640&height=640&fit=bounds)


![ML - ensemble methods [pt-br]](https://cdn.slidesharecdn.com/ss_thumbnails/ml-ensemblemethods-160727181249-thumbnail.jpg?width=640&height=640&fit=bounds)











