Baixar para ler offline

















![Armazenamento, Indexação e Recuperação de Informação – MSI – 2015/2016
Mário Monteiro - 77910 || Emanuel Pires - 77994
21
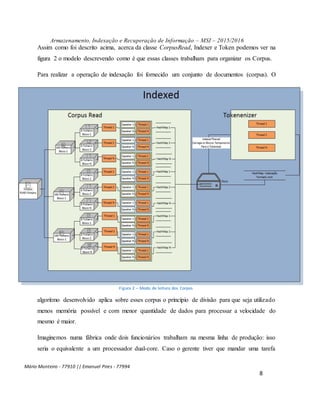
Definir o número de blocos de memória a processar tem a ver com a quantidade de HasHMap
a ser utilizado para armazenar informação durante o processo de corpus Read e de
Tokenização, os mesmos são armazenados no disco para continuação do processo de
indexação, visto a sua permanência na memória, irá sobrecarregar a mesma.
Definir o número de Blocos de Corpus, tem a ver com o número de corpus a ser carregado e
processado por cada threads que é criada conforme a configuração do número de blocos de
memória, vide figura 2.
Definir o limite de memória que a aplicação deve chegar tem a ver com o ultimo limite que a
aplicação deve suportar durante o processo de indexação.
Todas essas configurações são carregadas e armazenadas num ficheiro de configuração por
isso o utilizador pode aceitar ou não a configuração por defeito.
Após escolher a opção executar Indexação é apresentada as opções de execução.
Opção 1 - é para arrancar com a execução em si. Durante a execução aparece no output o tempo
de início e os números de grupos de corpus em execução, ao terminar a indexação aprece o
tempo final.
Opção 2 [Desativar] Stopwords, significa que o algoritmo vai ser executado removendo do
corpus todos os Stopwords, caso se pretenda deixar os Stopwords nos corpos deve ser escolhida
esta opção, o utilizador pode ativar ou desativar execução de Stopwords.
Opção 3 [Desativar] Steamer, significa que o algoritmo vai ser executado aplicando algoritmo
de Steamer sobre os termos, caso se pretenda deixar os termos sem aplicar o Steamer deve ser
escolhida esta opção.
Opção 4 pode ser escolhida os dois modos de execução ao mesmo tempo. Vide a figura 12.](https://image.slidesharecdn.com/relatrio-airtp2v2-160317123623/85/Armazenamento-Indexacao-e-Recuperacao-de-Informacao-21-320.jpg)



Este documento descreve um algoritmo de indexação invertida desenvolvido em Java para realizar pesquisa de informação em um corpus de documentos. O algoritmo utiliza múltiplas threads para ler e processar os documentos em paralelo, cria um índice invertido com termos e suas ocorrências nos documentos, e permite pesquisas por termos simples e combinados.





















































