Baixar para ler offline







![MAP-REDUCED EM (MREM)
Decomposição do EM básico utilizando algoritmo MapReduce.
Uma vez que todos os registos dos dados de entrada são independentes um
do outro para o cálculo das estatísticas, eles podem ser processados em
paralelo. Os registros de entrada podem ser divididos entre vários Mappers,
cada um executando o E-Step . O M-step é realizada sobre os Reducers.
E- Step: Cada mapper toma como entrada a estrutura da RB, a estimativa
atual de parâmetros t, a decomposição da JT, e os dados incompletos D. Um
contador acompanha o passo acumulando a contagem dos registros de
entrada para [xi, Xi]. PARA TODAS AS COMBINAÇÕES POSSÍVEIS ENTRE
OS ESTADOS DOS PAIS COM OS FILHOS
Uma vez que o mapeador processa todos os registros atribuídos a ele, ele
emite um par chave-valor intermediário para cada entrada de mapa de hash.
Esta chave intermediária garante que todas as variáveis com os mesmos
pais são agrupados e transformados em uma mesma tarefa de redução.](https://image.slidesharecdn.com/scalingbayesiannetworkparameterlearningwithexpectationmaximizationv2-130523121945-phpapp01/85/Scaling-bayesian-network-parameter-learning-with-Hadoop-9-320.jpg)






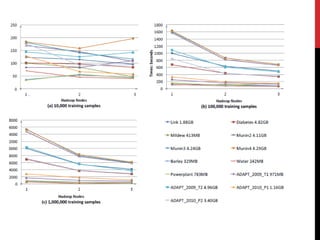

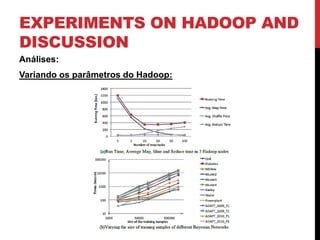

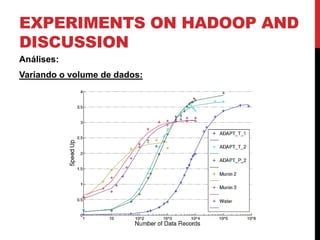

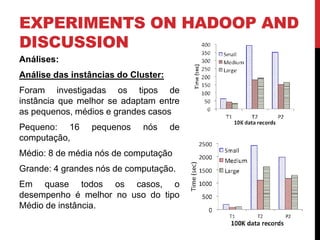





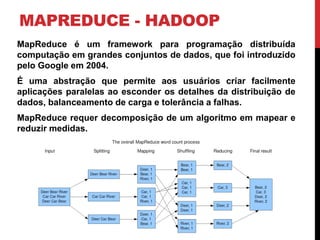
Este documento descreve pesquisas sobre acelerar o aprendizado de parâmetros de redes Bayesianas usando Hadoop e MapReduce. Os autores implementaram algoritmos tradicionais e o algoritmo EM no Hadoop para aprendizagem de parâmetros, testando em várias redes Bayesianas complexas. Os experimentos mostraram que o MapReduce pode reduzir significativamente o tempo de processamento para grandes conjuntos de dados, em comparação com métodos sequenciais. As análises indicaram que o desempenho depende do tamanho e estrutura da rede, além

























![[Estácio - IESAM] Automatizando Tarefas com Gulp.js](https://cdn.slidesharecdn.com/ss_thumbnails/estcio-iesamautomatizandotarefascomgulp-151220144313-thumbnail.jpg?width=640&height=640&fit=bounds)







![[Fapan] criando aplicações mobile híbridas com ionic framework](https://cdn.slidesharecdn.com/ss_thumbnails/fapancriandoaplicaesmobilehbridascomionicframework-151127135603-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)

