Baixado 15 vezes



















































![local key = KEYS[1]
local value = KEYS[2]
local decoder = __LUA(decode)__() -- substituir por f_93983…()
local encoder = __LUA(encode)__() -- antes de utilizar
local sereal_string = redis.call( 'get‟ , key )
local decoded_string = decoder.decode_sereal(sereal_string)
local decoded_number = tonumber(decoded_string)
sereal_string = encoder.encode_sereal(decoded_number + value)
return redis.call( 'set‟ , key , sereal_string)
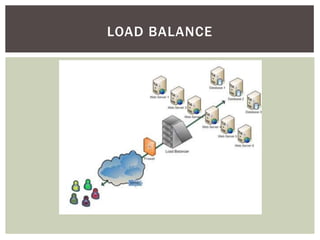
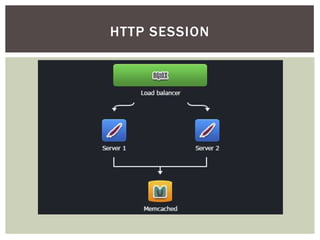
REDIS : EXEMPLOS
INCREMENTAR VALOR SERIALIZADO](https://image.slidesharecdn.com/qconsp-130831071006-phpapp02/85/Big-Data-Performance-Posix-RTB-no-mercado-de-publicidade-online-66-320.jpg)









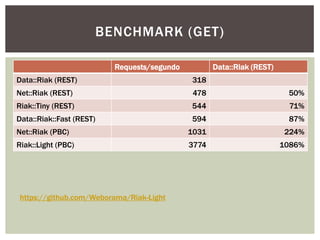







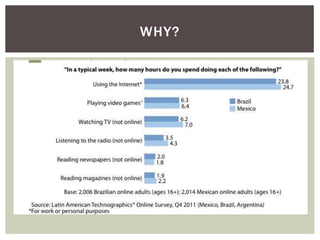
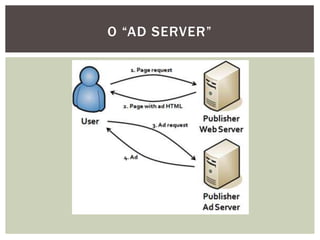
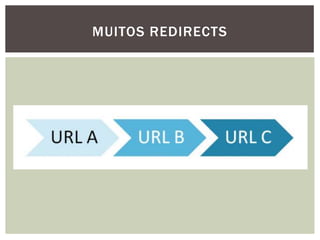
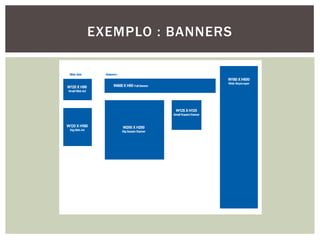
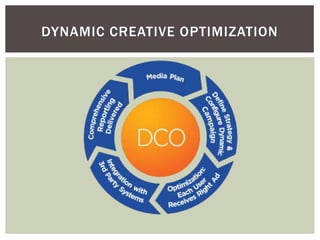
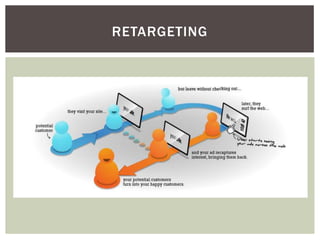
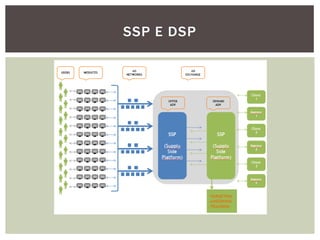
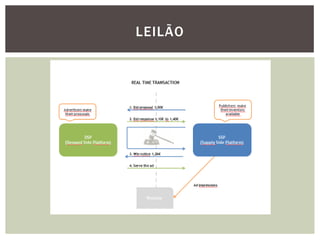
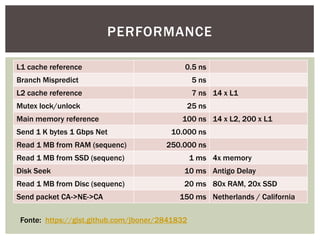
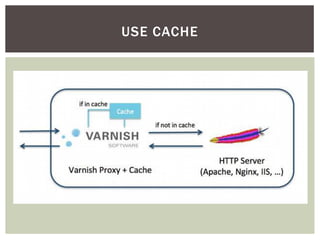
Tiago Peczenyj apresenta sobre propaganda na web, incluindo técnicas como retargeting, real time bidding e uso de big data para segmentar audiências e melhorar a performance de campanhas online. Ele também discute desafios de escalabilidade em sistemas de publicidade e ferramentas como Redis e Riak para armazenamento e processamento de grandes volumes de dados.






































