Baixado 10 vezes



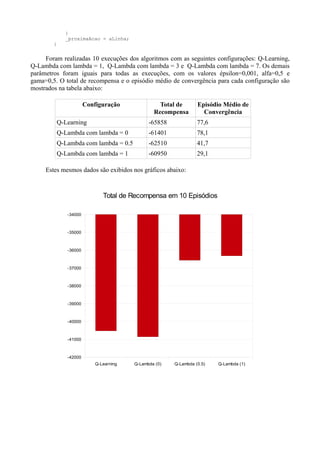
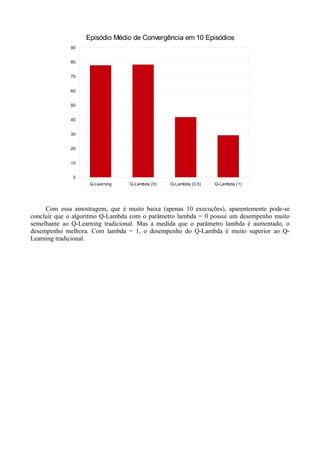

O documento compara os algoritmos Q-Learning e Q-Lambda no problema do "Cliff-walking" usando C#. Q-Lambda com λ=1 teve melhor desempenho, convergindo mais rápido e obtendo maior recompensa total do que Q-Learning e Q-Lambda com outros λ valores.



























