Baixar para ler offline






![Por que fragmentar?
- Compartilhamento de dados (confiabilidade)
- Distribuição e paralelização de processamento
(perfomance) [ÖZSU e VALDURIEZ, 2011]
GANHO DE DESEMPENHO
7](https://image.slidesharecdn.com/processamento-consultas-xml-v2-130319120231-phpapp01/85/Processamento-consultas-xml-v2-7-320.jpg)
![Processamento paralelo
• Paralelismo Interconsulta
Processamento simultâneo de diferentes consultas de
baixo custo em nós distintos.
• Paralelismo Intraconsulta
Processamento simultâneo da mesma consulta em
múltiplos nós.
[MATTOSO, 2009]
8](https://image.slidesharecdn.com/processamento-consultas-xml-v2-130319120231-phpapp01/85/Processamento-consultas-xml-v2-8-320.jpg)

![Fragmentação Horizontal
f1
f2
Seleção () Unidade de dados= tuplas
Modelo Relacional
Modelo XML
Seleção () Unidade de dados = árvores [SILVA, 2013]
11](https://image.slidesharecdn.com/processamento-consultas-xml-v2-130319120231-phpapp01/85/Processamento-consultas-xml-v2-11-320.jpg)
![F1Residencial:= <CContatos,σcontato/telefone/tipo=‟Residencial‟>
F2Outros:= <CContatos,σcontato/telefone/tipo <> „Residencial‟>
F1Residencial F2Outros
<contato> <contato>
<id>001</id> <id>002</id>
<nome>Maria Silva</nome> <nome>José Abreu </nome>
<endereco> <endereco>
<logradouro> Rua A </logradouro> <logradouro> Rua C</logradouro>
<numero>10</numero> <numero>155</numero>
<complemento>Casa 3</complemento> <complemento>Ap. 501</complemento>
</endereco> </endereco>
<email>maria.silva@hotmail.com</email> <email>jose.abreu@hotmail.com</email>
<telefone> <telefone>
<tipo> Residencial </tipo> <tipo> Celular </tipo>
<ddd>21</ddd> <ddd>31</ddd>
<numero>22220000</numero> <numero>99990000</numero>
<telefone> <telefone>
</contato> </contato>
[SILVA, 2013, adaptado]
12](https://image.slidesharecdn.com/processamento-consultas-xml-v2-130319120231-phpapp01/85/Processamento-consultas-xml-v2-12-320.jpg)
![Fragmentação Vertical
f1
f2
Projeção ()
Modelo Relacional
Modelo XML
Projeção () [SILVA, 2013]
13](https://image.slidesharecdn.com/processamento-consultas-xml-v2-130319120231-phpapp01/85/Processamento-consultas-xml-v2-13-320.jpg)
![F1Contatos:= <CContatos, π/Contato, /Contato/Telefone>
F2Contatos:= <CContatos, π/Contato/Telefone, {}>
F1Contatos
Esquema Id Logradouro
Nome Número
Logradouro Contato
Id Endereço Complemento
Nome Número e-mail Bairro
Endereço Complemento Cidade
Contato e-mail Bairro
Cidade
Tipo
DDD
F2Contatos
Telefone Tipo
Número
Telefone DDD
Número
[SILVA, 2013]](https://image.slidesharecdn.com/processamento-consultas-xml-v2-130319120231-phpapp01/85/Processamento-consultas-xml-v2-14-320.jpg)

![Fragmentação Virtual
Sub -Query BD
C11
SGBD
DBMS
Sub -Query
C22
SGBD
DBMS BD
Original
C
Query
Sub -Query
C33
SGBD
DBMS BD
Sub -Query
C44
SGBD
DBMS
BD
[MATTOSO et al., 2005, adaptada]
17](https://image.slidesharecdn.com/processamento-consultas-xml-v2-130319120231-phpapp01/85/Processamento-consultas-xml-v2-17-320.jpg)
![Select sum(price) from ITEM Select sum(price) from ITEM
where item_no >= 1 where item_no >= 250,001
and item_no < 250,001 and item_no < 500,001
Select sum(price) from ITEM
Select sum(price) from ITEM Select sum(price) from ITEM
where item_no >= 500,001 where item_no >= 750,001
and item_no < 750,001 and item_no < 1,000,001
[MATTOSO et al., 2005]
18](https://image.slidesharecdn.com/processamento-consultas-xml-v2-130319120231-phpapp01/85/Processamento-consultas-xml-v2-18-320.jpg)

![Fragmentação Virtual Adaptativa
SGBD
DBMS
SGBD
DBMS
Original
C
Query
SGBD
DBMS
SGBD
DBMS
Subconsultas [MATTOSO et al., 2005,
adaptada]](https://image.slidesharecdn.com/processamento-consultas-xml-v2-130319120231-phpapp01/85/Processamento-consultas-xml-v2-20-320.jpg)




![[MA e SCHEWE, 2003]
Contribuição: Define técnicas de fragmentação horizontal e
vertical em dados XML.
Limitações: DTD (modelo), XML-QL (consulta), somente
documentos, sem alocação, exige projeto de fragmentação.
25/40
25](https://image.slidesharecdn.com/processamento-consultas-xml-v2-130319120231-phpapp01/85/Processamento-consultas-xml-v2-25-320.jpg)
![[BREMER e GERTZ, 2003]
Contribuição: Abordagem para fragmentação
horizontal/vertical e alocação de dados XML.
Limitações: Esquema específico (RepositoryGuide),
baixo desempenho em consultas e atualizações
distribuídas, exige projeto de fragmentação.
26/40
26](https://image.slidesharecdn.com/processamento-consultas-xml-v2-130319120231-phpapp01/85/Processamento-consultas-xml-v2-26-320.jpg)
![[ANDRADE et al., 2006]
Contribuições: Define as técnicas de fragmentação
vertical, horizontal e híbrida, descreve critérios de
correção.
Limitação: Exige projeto de distribuição.
27/40
27](https://image.slidesharecdn.com/processamento-consultas-xml-v2-130319120231-phpapp01/85/Processamento-consultas-xml-v2-27-320.jpg)
![[FIGUEIREDO et al., 2010]
Contribuições: Automatiza as técnicas de fragmentação
e os critérios de correção definidos em [Andrade et al.,
2006], trata da redução de fragmentos irrelevantes.
Limitação: Modelo de consultas utiliza subconjunto
limitado da XQuery, exige projeto de distribuição.
28](https://image.slidesharecdn.com/processamento-consultas-xml-v2-130319120231-phpapp01/85/Processamento-consultas-xml-v2-28-320.jpg)
![Arquitetura Mediador-Adaptadores para o
processamento de consultas XML
[FIGUEIREDO et al., 2010]
29](https://image.slidesharecdn.com/processamento-consultas-xml-v2-130319120231-phpapp01/85/Processamento-consultas-xml-v2-29-320.jpg)
![[KLING et al., 2010]
Contribuições: Automatiza a fragmentação, consulta
e alocação dos dados fragmentados, poda de
fragmentos irrelevantes.
Limitação: Modelo de consultas utiliza subconjunto
limitado da XQuery, não trata da fragmentação híbrida,
exige projeto de distribuição.
30/40
30](https://image.slidesharecdn.com/processamento-consultas-xml-v2-130319120231-phpapp01/85/Processamento-consultas-xml-v2-30-320.jpg)
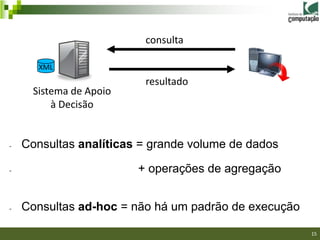
![[RODRIGUES et al., 2011]
Contribuições: Fragmentação virtual para o modelo
XML, não exige projeto de distribuição.
Limitação: Variação do tempo de recuperação da função
position(), desbalanceamento de carga.
31/40
31](https://image.slidesharecdn.com/processamento-consultas-xml-v2-130319120231-phpapp01/85/Processamento-consultas-xml-v2-31-320.jpg)
![/books/book[position()=2)]
32](https://image.slidesharecdn.com/processamento-consultas-xml-v2-130319120231-phpapp01/85/Processamento-consultas-xml-v2-32-320.jpg)
![[RODRIGUES, 2011]
33](https://image.slidesharecdn.com/processamento-consultas-xml-v2-130319120231-phpapp01/85/Processamento-consultas-xml-v2-33-320.jpg)
![Visão Geral da Arquitetura para a
Fragmentação Virtual XML [RODRIGUES et al., 2011]
34](https://image.slidesharecdn.com/processamento-consultas-xml-v2-130319120231-phpapp01/85/Processamento-consultas-xml-v2-34-320.jpg)
![[LIMA et al., 2010]
Contribuições: Ajusta dinamicamente os tamanhos dos
fragmentos durante a execução da consulta, implementa o
balanceamento de carga.
Limitação: Aplicado somente ao modelo relacional.
35/40
35](https://image.slidesharecdn.com/processamento-consultas-xml-v2-130319120231-phpapp01/85/Processamento-consultas-xml-v2-35-320.jpg)

![2 cluster
1 for $r in doc(„books.xml‟)//book
subconsultas
[position() >= 1 and position() < 2000]
consulta
BD where $r/book[@year=“2003”]
for $r in doc(„books.xml‟)//book
... [position() >= 2001 and position() <
for $r in doc(„books.xml‟)//book 4000]
where $r/book[@year=“2003”]
where $r/book[@year=“2003”]
BD
for $r in doc(„books.xml‟)//book
[position() >= 4001 and position() <
for $r in doc(„books.xml‟)//book
8000]
[position() >= 1 and position() < 20000] where $r/book[@year=“2003”]
where $r/book[@year=“2003”] for $r in doc(„books.xml‟)//book
for $r in doc(„books.xml‟)//book [position() >= 8001 and position() <
10500]
[position() >= 20001 and position() < 40000] where $r/book[@year=“2003”]
where $r/book[@year=“2003”] 38/40
38](https://image.slidesharecdn.com/processamento-consultas-xml-v2-130319120231-phpapp01/85/Processamento-consultas-xml-v2-38-320.jpg)

![FVA-
XML
Arquitetura Mediador-Adaptadores para o
processamento de consultas XML
[FIGUEIREDO et al., 2010]
40](https://image.slidesharecdn.com/processamento-consultas-xml-v2-130319120231-phpapp01/85/Processamento-consultas-xml-v2-40-320.jpg)


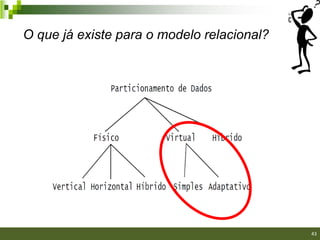
![O que já existe para o modelo XML?
Trabalho Armazena- Técnica Frag- Modelo Consulta Exige
mento mentação Projeto Frag.
[FIGUEIREDO et SD e MD Horizontal, XML XQuery Sim
al., 2006] vertical e Schema
híbrida
[KLING et al., SD e MD Horizontal, XML XQuery Sim
2010] vertical Schema
[RODRIGUES et SD e MD Virtual Simples XML XQuery Não
al., 2011] Schema
Nossa Proposta SD e MD Virtual XML XQuery Não
Adaptativa Schema
44/40
44](https://image.slidesharecdn.com/processamento-consultas-xml-v2-130319120231-phpapp01/85/Processamento-consultas-xml-v2-44-320.jpg)

![[SILVA JÚNIOR, 2012]
46](https://image.slidesharecdn.com/processamento-consultas-xml-v2-130319120231-phpapp01/85/Processamento-consultas-xml-v2-46-320.jpg)



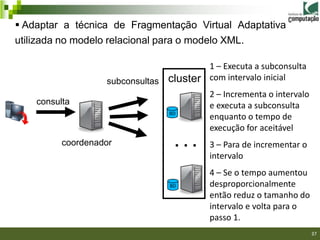
A dissertação propõe uma técnica de fragmentação virtual adaptativa para processamento eficiente de consultas XML em ambientes distribuídos, sem necessidade de projeto prévio de fragmentação. A solução é baseada em trabalhos anteriores sobre fragmentação virtual para dados relacionais e XML, mas automatiza o processo de fragmentação durante a execução da consulta.



























