Baixado 19 vezes
































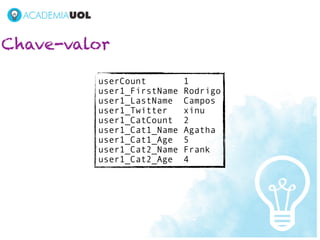
![Bancos de dados de documentos
{
"Cats": [
{
"Age": 5,
"EyeColor": "Blue",
"Name": "Agatha"
},
{
"Age": 4,
"EyeColor": "Blue",
"Name": "Frank"
}
],
"FirstName": "Rodrigo",
"LastName": "Campos",
"TwitterScreenName": "xinu"
}](https://image.slidesharecdn.com/bigdatacampuspartypdf-130202100113-phpapp02/85/The-good-the-bad-and-the-big-data-36-320.jpg)


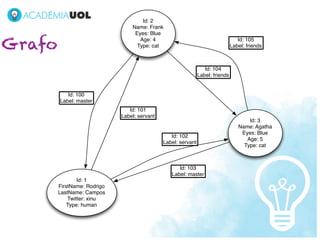
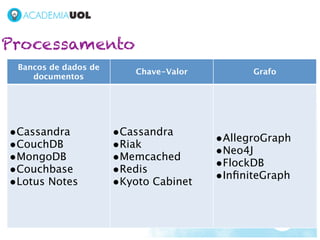


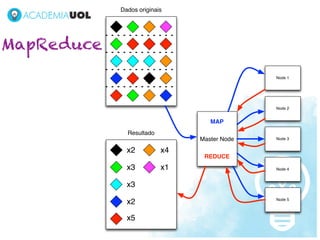


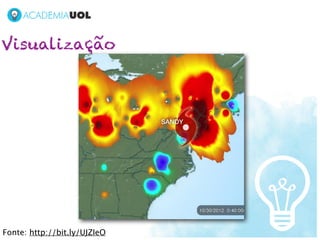





1) O documento discute os desafios do processamento de grandes volumes de dados, conhecidos como Big Data. 2) Novas tecnologias como bancos de dados não-relacionais, MapReduce e visualização de dados são necessárias para lidar com a escala, diversidade e distribuição dos dados. 3) As ferramentas para Big Data ainda estão evoluindo para atender as novas demandas, mas já complementam soluções estabelecidas.















































