Baixar para ler offline









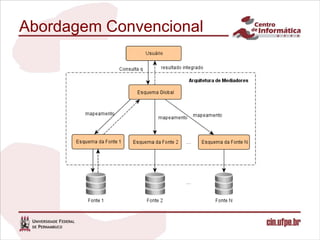
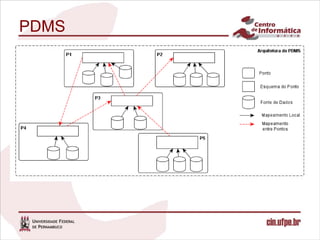







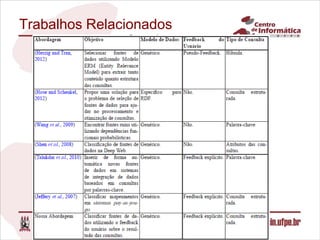
















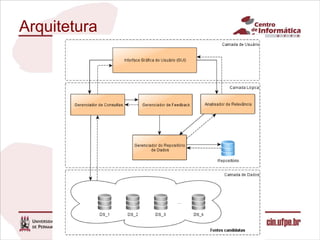
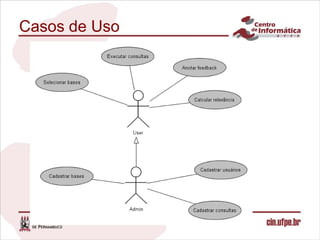


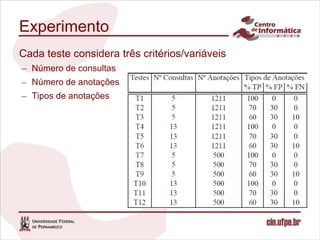

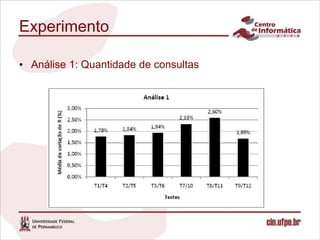
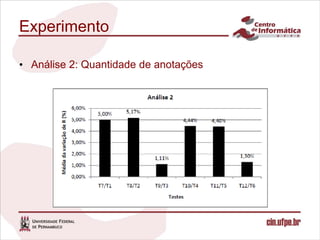
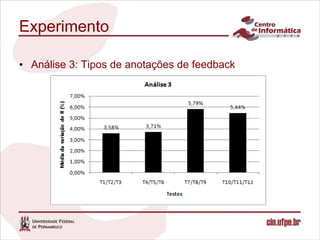






O documento descreve uma abordagem para classificar fontes de dados candidatas a serem incluídas em um sistema de integração de dados pay-as-you-go utilizando o feedback do usuário. A abordagem define métricas para medir a relevância das fontes com base no feedback sobre os resultados de consultas. Um algoritmo é proposto para calcular os valores de relevância e classificar as fontes. Experimentos validam o comportamento da medida de relevância em diferentes cenários.










































![[TCC] Agrupamento de Instâncias](https://cdn.slidesharecdn.com/ss_thumbnails/sicgqiess26hdubkliv2-signature-6fa52222291d6953defa944f5a36f4ef6925c30c04abbe4995ae2e0607f11440-poli-160717235713-thumbnail.jpg?width=640&height=640&fit=bounds)




