Baixar para ler offline









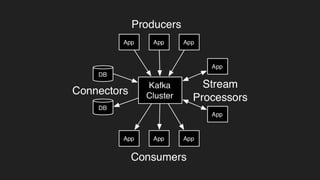


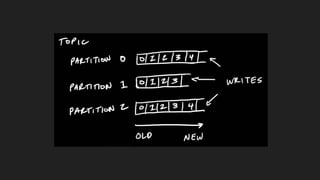


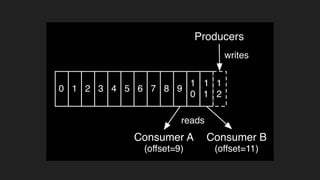



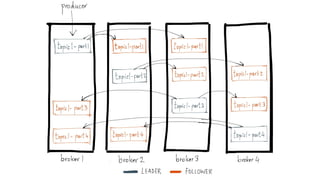







1) O documento discute o uso do Kafka no LinkedIn para suportar o processamento de 1,4 trilhões de mensagens por dia e 175 terabytes de dados. 2) O Kafka foi projetado para mover dados de alta performance de forma distribuída e escalável, servindo como uma única fonte de verdade para o LinkedIn. 3) O documento explica os principais conceitos do Kafka como tópicos, partições, produção e consumo de dados.















![Scala na soundcloud [QCon]](https://cdn.slidesharecdn.com/ss_thumbnails/scalanasoundcloudqcon-141102071122-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)



















