Baixar para ler offline
![29/04/2021 – Edgar Messias Mantovani
[São Paulo] MuleSoft Meetup Group
Conectando seu primeiro Hello World Mule ao
Apache Kafka](https://image.slidesharecdn.com/20210429kafkaslides-210430131611/85/Meetup-Mule-SP-Kafka-Edgar-1-320.jpg)
![29/04/2021 – Edgar Messias Mantovani
[São Paulo] MuleSoft Meetup Group
Conectando seu primeiro Hello World Mule ao
Apache Kafka](https://image.slidesharecdn.com/20210429kafkaslides-210430131611/75/Meetup-Mule-SP-Kafka-Edgar-1-2048.jpg)





![11
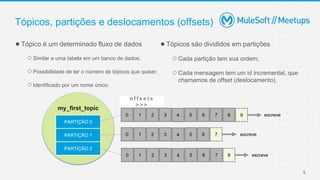
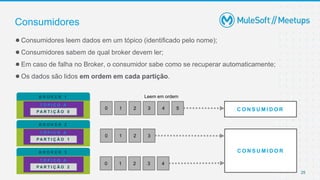
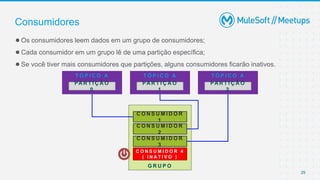
●Um offset só tem importância para aquela determinada partição (uma mensagem por
partição);
●O offset 3 na partição 0 não é a mesma mensagem do offset 3 na partição 1;
●A ordem é garantida somente na partição (não através das partições);
●Os dados são mantidos apenas por determinado período, sendo o padrão 7 dias de retenção;
●Um dado incluído não pode ser alterado (imutabilidade);
●Um dado é associado randomicamente a uma partição a menos que uma KEY seja
Tópicos, partições e deslocamentos (offsets)
stations_topic
PARTIÇÃO 0
PARTIÇÃO 1
PARTIÇÃO 2
1 2 3
1 2 3
1 2 3
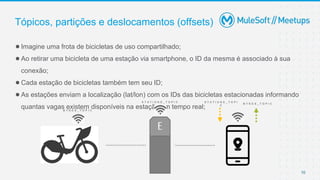
{
"station":{
"id":10,
"occupied_positions":[1,3,5],
"free_positions":[2,4,6]
}
}
{
"station":{
"id":6,
"occupied_positions":[1,2,3],
"free_positions":[4,5,6]
}
}
0
0
0](https://image.slidesharecdn.com/20210429kafkaslides-210430131611/85/Meetup-Mule-SP-Kafka-Edgar-11-320.jpg)

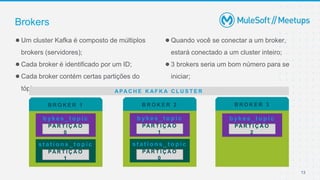
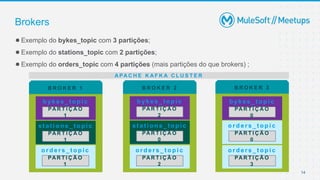
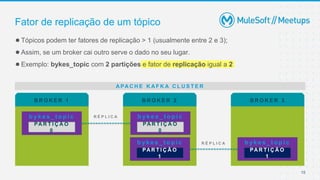

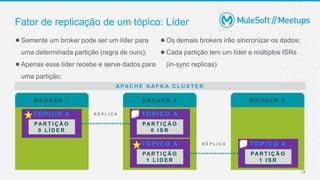








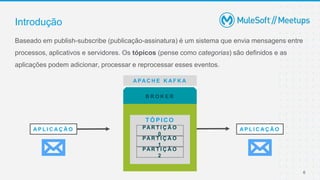
O documento apresenta uma introdução sobre Apache Kafka, abordando seus conceitos fundamentais como tópicos, partições, brokers e replicação. A apresentação também explica o funcionamento de produtores e consumidores no Kafka.



























