Transferir como PDF, PPTX












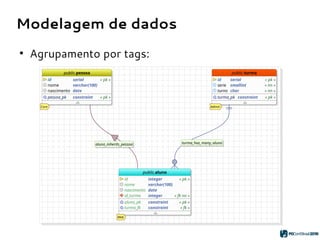



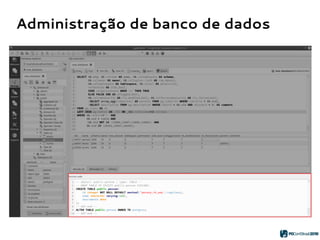
![Geração de código SQL
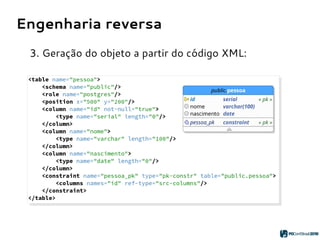
1. Extração dos atributos do objeto:
{name} = “public.pessoa”
{columns} = [ “id serial”,
“nome varchar(100)”,
“nascimento date” ]
{constraints} = “PRIMARY KEY pessoa_pk (id)”
{name} = “public.pessoa”
{columns} = [ “id serial”,
“nome varchar(100)”,
“nascimento date” ]
{constraints} = “PRIMARY KEY pessoa_pk (id)”](https://image.slidesharecdn.com/pgmodelerpgconfbrasilnew-180804181136/85/pgModeler-muito-mais-que-um-modelador-de-bancos-de-dados-PostgreSQL-20-320.jpg)
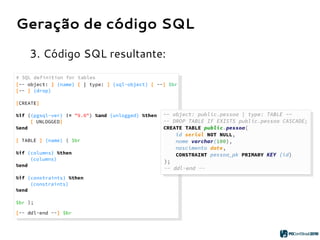
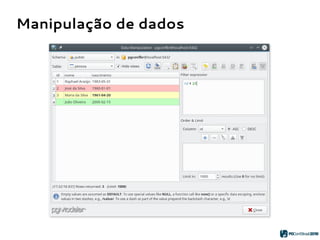
![Geração de código SQL
2. Parsing do template do objeto:
{name} = “public.pessoa”
{columns} = [ “id serial”,
“nome varchar(100)”,
“nascimento date” ]
{constraints} = “PRIMARY KEY
pessoa_pk (id)”
{name} = “public.pessoa”
{columns} = [ “id serial”,
“nome varchar(100)”,
“nascimento date” ]
{constraints} = “PRIMARY KEY
pessoa_pk (id)”](https://image.slidesharecdn.com/pgmodelerpgconfbrasilnew-180804181136/85/pgModeler-muito-mais-que-um-modelador-de-bancos-de-dados-PostgreSQL-21-320.jpg)
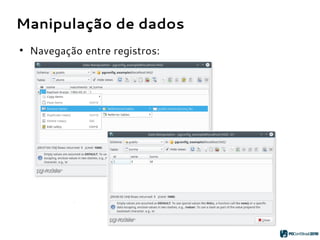
![Geração de código SQL
2. Parsing do template do objeto:
{name} = “public.pessoa”
{columns} = [ “id serial”,
“nome varchar(100)”,
“nascimento date” ]
{constraints} = “PRIMARY KEY
pessoa_pk (id)”
{name} = “public.pessoa”
{columns} = [ “id serial”,
“nome varchar(100)”,
“nascimento date” ]
{constraints} = “PRIMARY KEY
pessoa_pk (id)”](https://image.slidesharecdn.com/pgmodelerpgconfbrasilnew-180804181136/85/pgModeler-muito-mais-que-um-modelador-de-bancos-de-dados-PostgreSQL-22-320.jpg)
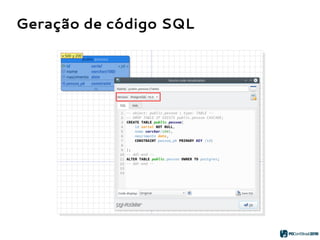


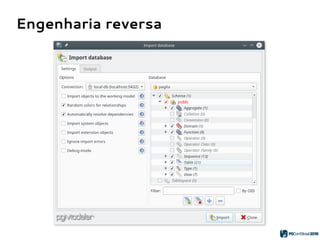






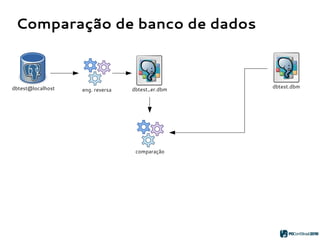
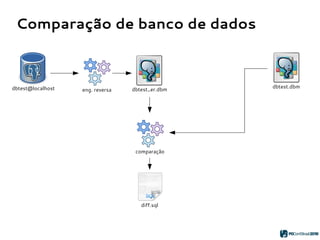
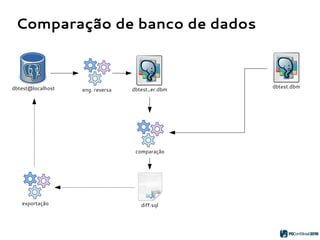
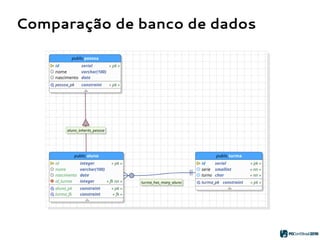
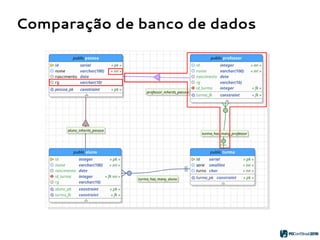


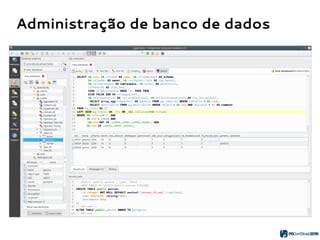
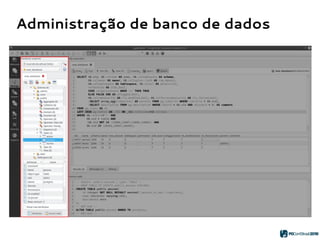
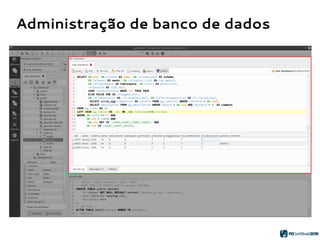





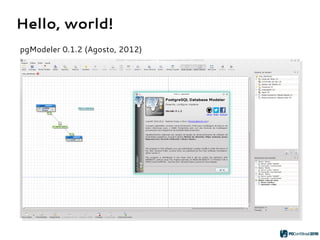
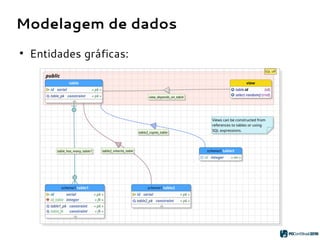
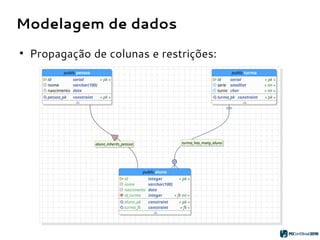
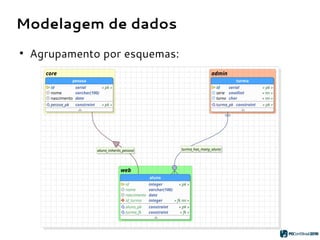
O PGModeler é uma ferramenta de modelagem de banco de dados para PostgreSQL, desenvolvida por Raphael Araújo e Silva, que surgiu da necessidade de uma documentação mais eficiente e da falta de ferramentas acessíveis. A ferramenta permite modelagem de dados, geração de código SQL e engenharia reversa, estando disponível para as principais plataformas desktop e federando funcionalidades avançadas, como suporte a tipos de dados geoespaciais e integração com plugins. Criado em 2006 e lançado sob a licença GPL, o PGModeler continua a evoluir com melhorias na interface e novas funcionalidades.



























