Este documento descreve um projeto sobre redes de alto débito e versões do protocolo TCP desenvolvidas para este tipo de redes. O projeto inclui um estudo das limitações do TCP original e das várias versões propostas para melhorar o desempenho em redes de alto débito e latência. Os autores irão implementar e testar uma nova abordagem para o TCP nestas redes, comparando a sua eficiência com outras versões existentes.














![Lista de Figuras
Lista de Figuras
Figura 2.1 – Esquema resumido do processo de conhecimento para a nova versão do protocolo................3
Figura 2.2 – Intercepção da nova versão com a inovação e a precaução necessárias. ..................................5
Figura 2.3 – Representação da matéria que envolve o âmbito......................................................................6
Figura 2.4 – Representação do âmbito, considerando as várias interfaces do TCP. .....................................7
Figura 2.5 – Representação dos tipos de reacção e controlo.........................................................................8
Figura 2.6 – Localização do âmbito através de uma comunicação entre emissor, receptor e rede. ..............8
Figura 2.7 – Representação do WBS...........................................................................................................10
Figura 2.8 – Gráfico de Gantt, representativo da sequência e relacionamento entre actividade.................11
Figura 3.1 – Esquema representativo da relação entre o TCP e os custos económicos. .............................13
Figura 3.2 – Crescimento da largura de banda disponibilizada (Fonte: [67]). ............................................16
Figura 3.3 – Mapa representativo das diversas ligações de alto débito entre continentes (Fonte:
Telegeography Research)............................................................................................................................17
Figura 3.4 – Mapa representativo de toda a disponibilização de largura de banda para Internet nos
diversos continentes (Fonte: Telegeography Research)..............................................................................17
Figura 3.5 – Relação ano, largura de banda teórica disponibilizada e ligações intercontinentais (Fonte:
Telegeography Research)............................................................................................................................18
Figura 3.6 – Tráfego médio, gerado pelas diversas ligações intercontinentais (Fonte: Telegeography
Research).....................................................................................................................................................18
Figura 3.7 – Timeline de desenvolvimento TCP.........................................................................................20
Figura 3.8 – Representação da analogia entre uma região e as versões TCP..............................................23
Figura 3.9 – O Cabeçalho TCP. ..................................................................................................................31
Figura 3.10 – Primeiro segmento TCP de uma sessão de dados.................................................................34
Figura 3.11 – Primeiro segmento TCP, após estabelecimento da sessão....................................................34
Figura 3.12 – Exemplo de troca de dados 1. ...............................................................................................36
xi](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-15-320.jpg)
![TCP em Redes de Elevado Débito
Figura 3.13 – Exemplo de troca de dados 2. .............................................................................................. 37
Figura 3.14 – O mecanismo de Piggybacking (Fonte: Washinton University).......................................... 38
Figura 3.15 – Representação do mecanismo Sliding Window................................................................... 39
Figura 3.16 – Representação das várias movimentações ao longo das trocas de segmentos TCP............. 39
Figura 3.17 – Movimentos do Sliding Window. ........................................................................................ 40
Figura 3.18 – Relação Window/Buffer....................................................................................................... 40
Figura 3.19 – Relação RTT/segmentos TCP.............................................................................................. 42
Figura 3.20 – Relação RTT/Janela. ............................................................................................................ 42
Figura 3.21 – Relação largura de banda/segmentos TCP........................................................................... 43
Figura 3.22 – Problema da janela com ligação de alto débito.................................................................... 43
Figura 3.23 – Reprentação do Silly Window Syndrome (Fonte: [3])......................................................... 44
Figura 3.24 – Cálculo do RTT medido por analisador de tráfego, comparado com o calculado TCP
(Fonte: [1]). ................................................................................................................................................ 47
Figura 3.25 – Representação da técnica exponential backoff..................................................................... 49
Figura 3.26 – Processo de activação do Persist Timer. .............................................................................. 50
Figura 3.27 – Exemplo de funcionamento do protocolo Sack.................................................................... 51
Figura 3.28 – Representação dos blocos da Sack Option........................................................................... 52
Figura 3.29 – Representação do retransmission ambiguity problem.......................................................... 54
Figura 3.30 – Representação dos campos do Timestamp Option............................................................... 55
Figura 3.31 – Análise do tráfego automóvel e populacional (Fonte: Universidade Técnica de Dresden e
Crowd Dynamics)....................................................................................................................................... 59
Figura 3.32 – Exemplo hidráulico de uma situação de congestão (Fonte: [3]). ......................................... 60
Figura 3.33 – Funcionamento da janela de receptor/janela congestão. ...................................................... 61
Figura 3.34 – Representação do estado de equilíbrio (Fonte: [13]). .......................................................... 62
Figura 3.35 – Representação do comportamento do Slow Start (Fonte: [13]). .......................................... 62
Figura 3.36 – Representação da perfomance de uma implementação 4.3BSD (Fonte: [13])..................... 63
Figura 3.37 – Representação da perfomance de uma implementação 4.3 BSD+ (Fonte [13])................... 64
Figura 3.38 – Representação gráfica da relação Slow Start/Congestion Avoidance (Fonte: [1]). ............. 66
Figura 3.39 – Probabilidade de existir perda de segmento......................................................................... 67
xii](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-16-320.jpg)
![Lista de Figuras
Figura 3.40 – Representação dos algoritmos de congestão em funcionamento (Fonte: [6]).......................69
Figura 3.41 – Representação do padrão problemático Fast Retransmit/Fast Recovery. .............................70
Figura 3.42 – Resumo de todas as operações e algoritmos de congestão, proporcionados pelas versões
TCP Tahoe, Reno e newReno. ....................................................................................................................72
Figura 3.43 – Relação throughput/velocidade transmissão [Fonte: [15]]. ..................................................76
Figura 3.44 – Gráfico característico do TCP Vegas....................................................................................77
Figura 3.45 – Comportamento do TCP Reno numa LFN de 10Gbit/s (Fonte: [9]).....................................84
Figura 3.46 – Representação do padrão gráfico do normal TCP (TCP Reno), MulTCP(N=10) e
HighSpeed TCP, numa LFN de 10Gbit/s (Fonte: [9]). ...............................................................................87
Figura 3.47 – Representação das modificações na janela de congestão efectuadas pelo TCP Scalable
(Fonte: [25]). ...............................................................................................................................................88
Figura 3.48 - Representação do padrão gráfico do normal TCP (TCP Reno), MulTCP(N=10) e Scalable
TCP (a=0.01, b=0.125) numa LFN 10Gbit/s (Fonte: [9])...........................................................................88
Figura 3.49 – Representação do algoritmo Binary Search Increase............................................................89
Figura 3.50 – Funções de crescimento BIC e CUBIC (Fonte: [27]). ..........................................................90
Figura 3.51 – Arquitectura FAST TCP (adaptado de [30] )........................................................................91
Figura 3.52 – Representação do funcionamento das janelas de congestão e atraso Compound TCP.........93
Figura 4.1 – Cenário Simulado Inicial. .......................................................................................................97
Figura 4.2 – Cenário Final...........................................................................................................................98
Figura 4.3 – CPU a utilizar 100% da capacidade de processamento ........................................................100
Figura 4.4 – Largura de banda ocupada com velocidade de 1Gbit/s, sem qualquer tipo de atraso...........101
Figura 4.5 – Simulação com atraso de 1000ms e 100Mbit/s (dummynet)................................................102
Figura 4.6 – Simulação com buffer de 16MB e buffer de 67MB (DummyNet). ......................................103
Figura 4.7 – Simulação com buffer máximo de 67MB e atraso de 1000ms (Netem) ...............................104
Figura 4.8 – Simulação com buffer de 16MB e buffer de 67MB, ambos com atraso de 50ms. ...............105
Figura 4.9 – Simulação com atraso configurado a 350ms, 300ms e 250ms..............................................105
Figura 4.10 – Simulação com a versão newReno (amostragem 10s)........................................................107
Figura 4.11 – Simulação com a versão TCP Vegas (amostragem 10s).....................................................108
Figura 4.12 – Simulação com a versão TCP Hybla (amostragem 10s).....................................................108
xiii](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-17-320.jpg)
![TCP em Redes de Elevado Débito
Figura 4.13 – Simulação com a versão Westwood+ (Amostragem 10s).................................................. 109
Figura 4.14 – Simulação com a versão Veno (amostragem 10s). ............................................................ 110
Figura 4.15 – Simulação com a versão Low Priority TCP (amostragem 10s). ........................................ 110
Figura 4.16 – Simulação com a versão HighSpeed TCP (amostragem 10s). ........................................... 111
Figura 4.17 – Simulação com a versão Scalable TCP (amostragem 10s). ............................................... 112
Figura 4.18 - Simulação com a versão BIC (amostragem 10s). ............................................................... 112
Figura 4.19 – Simulação com a versão CUBIC (amostragem 10s).......................................................... 113
Figura 4.20 – Simulação com a versão H-TCP (amostragem a 10s)........................................................ 114
Figura 4.21 – Simulação com a versão H-TCP (amostragem a 5s)......................................................... 114
Figura 4.22 – Simulação com todas as versões testadas........................................................................... 115
Figura 4.23 – Arquitectura NS (Fonte: [106]).......................................................................................... 116
Figura 4.24 – Cenário Lumbbell em NS2................................................................................................. 120
Figura 4.25 – Cenário Internet.................................................................................................................. 120
Figura 5.1 – Técnica de atenuação de Ack Compression......................................................................... 123
Figura 5.2 – Adaptabilidade da versão EIC TCP. .................................................................................... 124
Figura 5.3 – Arquitectura EIC TCP.......................................................................................................... 125
Figura 5.4 – Diagrama de Classes EIC TCP. ........................................................................................... 126
Figura 5.5 – Diagrama de fluxo da recepção de segmentos do EIC TCP................................................. 126
Figura 5.6 – Fluxograma de envio de segmentos do EIC TCP. ............................................................... 127
Figura 5.7 – Algoritmo da abertura de janela do EIC TCP ...................................................................... 128
Figura 5.8 – Simulação com a versão newReno Vs. EIC TCP e somatório das duas. ............................. 130
Figura 5.9 – Simulação com a versão TCP Vegas Vs. EIC TCP e somatório das duas........................... 131
Figura 5.10 - Simulação com a versão TCP Hybla Vs. EIC TCP e somatório das duas.......................... 131
Figura 5.11 – Simulação com a versão TCP Westwood+ Vs. EIC TCP e somatório das duas................ 132
Figura 5.12 – Simulação com a versão TCP Veno Vs. EIC TCP e somatório das duas. ......................... 132
Figura 5.13 – Simulação com a versão TCP Low Priority Vs. EIC TCP e somatório das duas............... 133
Figura 5.14 – Simulação com a versão HighSpeed Vs. EIC TCP e somatório das duas.......................... 134
Figura 5.15 – Simulação com a versão Scalable Vs. EIC TCP e somatório das duas.............................. 134
xiv](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-18-320.jpg)

![TCP em Redes de Elevado Débito
Lista de Tabelas
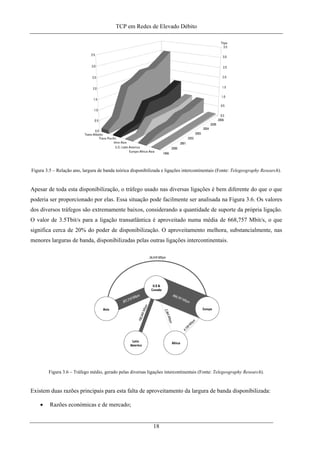
Tabela 3.1 – Valores da Window Scale Option.......................................................................................... 56
Tabela 3.2 – Tamanho do segmento que circula numa rede ethernet TCP/IP............................................ 58
Tabela 3.3 – Tabela com valores de tempo de resposta conforme tipo de ligação (Fonte: [62]). .............. 85
Tabela 3.4 – Valores de percentagem de utilização do TCP Tahoe, Reno e newReno.............................. 95
Tabela 4.1 – Especificações de Hardware e SO usado por PC................................................................... 98
Tabela 4.2 – Definição dos Agentes Emissores TCP. .............................................................................. 117
Tabela 4.3 – Definição dos Agentes Receptores TCP.............................................................................. 118
xvi](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-20-320.jpg)







![TCP em Redes de Elevado Débito
2.1.5.1. O Protocolo
O Protocolo TCP tem diversas áreas de estudo. É crucial o rigor em relação a área que o projecto se
insere, sendo que uma expansão demasiada nas restantes áreas deve ser evitada. As áreas de estudo são as
seguintes:
• Transferência de Dados;
• Confiabilidade;
• Controlo de Fluxo;
• Controlo de Congestão;
• Multiplexação;
• Conexões;
• Precedências;
• Segurança;
A principal área onde irá incidir o estudo é o controlo de fluxo e o controlo de congestão. Existe também
uma sub área que também se poderá revelar importante: a transferência dos dados. Informação mais
detalhada sobre o que abrange cada uma das áreas que não se inserem directamente no âmbito deste
projecto poderá ser importante, pois poderá transmitir uma melhor noção acerca do desvio de matéria.
Essa informação poderá ser encontrada principalmente na especificação do protocolo [38]. A Figura 2.3 é
uma representação das áreas em termos de importância para o âmbito.
Figura 2.3 – Representação da matéria que envolve o âmbito.
6](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-28-320.jpg)


![2. Planeamento
estável). Irão também ser utilizadas as aplicações necessárias para geração e monitorização de tráfego da
plataforma Linux, bem como aplicações com intuito estatístico e geradores de atraso. As aplicações que
serão utilizadas durante os testes serão: Xgraph [88], Gnuplot [89], Tcpdump [90], Iperf [91], Dummynet
[92], Netem [93], Trpr [94].
No caso da implementação irá ser utilizado software de simulação, mais propriamente o NS2 [103]
(Network Simulator, versão mais recente estável) para sistema operativo Linux. Poderão também ser
necessárias aplicações para criação de estatísticas geradas por este simulador. Essas aplicações poderão
ser o Xgraph ou o Gnuplot, já utilizados anteriormente.
2.1.7. O Hardware
O Hardware especificamente necessário neste projecto será 3 computadores pessoais com placas de rede
que suportem velocidades de 1Gbps. Adicionalmente será usado um switch de monitores. Este hardware
apenas é necessário para a fase inicial de testes. O caso ideal não é minimamente possível de realizar,
pelo que grande parte dos testes irão recorrer a simulações.
2.1.7.1. A Documentação
Num trabalho de investigação, toda a fase de documentação assume um carácter extra de importância,
i.e., todo o estudo efectuado deve ser correctamente estruturado e descrito em relatório, sob pena de toda
a parte prática de testes não ter a base teórica necessária ao leitor, que, ao contrário dos participantes do
projecto, não esteve presente em toda a investigação. Outra forma de abordar a importância da
documentação neste tipo de projectos, é o facto de um dos seus objectivos ser servir de referência a novos
projectos de investigação da mesma área.
No que diz respeito a toda a parte prática, os caminhos até chegar aos diversos cenários e testes devem ser
documentados, também com o propósito de poder servir de referência a projectos de características
semelhantes.
Os documentos devem também conter referências a diversas fontes informativas, com o intuito de
direccionar quem necessite de abordar um assunto específico mais detalhadamente. Estando o projecto
directamente ligado com a Internet, assim estarão as suas referências principais.
9](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-31-320.jpg)


![TCP em Redes de Elevado Débito
3.Enquadramento ao Protocolo
Como já foi referido anteriormente (ver Cap. 2.1), o protocolo TCP tem diversas áreas de estudo que se
dividem por toda a comunidade de investigação. A principal área de estudo abordada neste projecto teve
um desenvolvimento que originou diversos algoritmos próprios, mas continua a utilizar os mecanismos
essenciais do TCP genérico, para todo o correcto funcionamento do protocolo.
No que diz respeito aos diversos mecanismos de funcionamento, uma correcta explicação de todo o
estudo é essencial para os objectivos posteriores de testes e implementações, pois será a base de toda a
análise. O tipo de funcionamento poderá ser genérico, ou específico ao meio de transmissão de alto
débito.
Neste enquadramento, irão ser analisadas as razões que levaram às modificações do protocolo para que se
verificasse um melhor desempenho; primeiro considerando um meio genérico de transmissão; depois a
verificação de falta de eficiência em certos meios, desenvolvendo soluções; finalmente o meio de alto
débito. Irá também ser analisada toda a evolução no que diz respeito aos desenvolvimentos TCP por parte
de entidades e pessoas.
3.1. Necessidade e Motivação
Num mundo onde a capacidade das infra-estruturas de rede e a sua complexidade estão relacionadas
directamente com o débito na rede, e paralelamente, a entrega dos dados relacionada com o lucro
proporcionado pela infra-estrutura; o TCP assume um papel de importância crítica [9]. Essa importância
crítica, resulta do facto do protocolo ser o responsável pelo transporte fiável e eficiente dos dados. Assim
sendo, quanto melhor for a implementação do protocolo, melhor será a forma de entrega dos dados, e
consequentemente maior será a poupança de custos. Uma representação do tipo de interacções existentes
entre complexidade/capacidade da rede, o seu débito, e posterior entrega dos dados e lucro é representada
na Figura 3.1.
12](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-34-320.jpg)


![3. Enquadramento ao Protocolo
se assim, variadas formas de os eliminar ou minimizar. Este tipo de problemas vai ser focado em todo
este relatório.
A razão do interesse é óbvia: as larguras de banda utilizadas actualmente são de um índice completamente
diferente, comparando com as larguras de banda utilizada na criação dos normais algoritmos de congestão
(Cap. 3.5). Assim sendo, de que vale ter meios de transmissão bastante rápidos, se não existe quem os
consiga utilizar da melhor forma? Este tipo de perguntas foi o principal incentivo à investigação
desenvolvida sobre o protocolo TCP em meios de alto débito.
O limite da largura de banda existente tem vindo a subir de forma cada vez mais abrupta. As razões são
muitas: aumento da procura dos consumidores, aumento dos consumidores, mudança de conteúdos na
Internet, mais comunidades de investigação, etc. Na Figura 3.2 poderá verificar-se a azul o crescimento
verificado e esperado no que diz respeito aos limites máximos de largura de banda; a linha vermelha
corrige para o que se verificou na actualidade mais recente. Através da análise da Figura chegou-se
também a diversas conclusões:
• A largura de banda teve uma fase estática no seu crescimento, de 1980 a 1990. Essa fase deve-se
à prioridade dada a outros parâmetros, para que a criação de uma rede global de computadores
pudesse ser criada e mantida (Internet). Os principais parâmetros foram especificados no
protocolo TCP em 1981 [38];
• A largura de banda inicia o seu crescimento por volta do ano 1990, muito devido à chegada do
Cabo UTP. Os parâmetros para uma rede global estavam estabelecidos, procurava-se agora maior
adesão;
• Em 1995 surge o cabo UTP com capacidade para 100Mbit/s. As velocidades de fibra óptica
acompanhavam as do cabo, mas permitiam maiores distâncias, sendo por isso utilizadas no
backbone da Internet. A Internet é um sucesso, assim como as redes locais;
• A partir de 1995 o crescimento torna-se ainda mais exponencial, sendo alcançadas em 1998
velocidades de 1Gbit/s, tanto por parte do cabo UTP, como da fibra óptica. A velocidade de
1Gbit/s é um ponto crucial para o TCP, pois é a partir desta largura de banda que se começaram a
verificar os variados problemas;
• O crescimento continua passando pelos 10Gbit/s em 1999 [65], chegando a 100Gbit/s em 2005.
Porém estes valores só foram conseguidos através de fibra óptica. Verificam-se neste caso, cada
vez mais, uma perda de eficiência por parte do TCP;
• Esperava-se que por volta de 2010 se atingisse velocidades de 1Tbit/s, porém um recente recorde
de 14Tbit/s foi conseguido [66]. Espera-se então um grande desafio ao TCP.
15](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-37-320.jpg)
![TCP em Redes de Elevado Débito
Figura 3.2 – Crescimento da largura de banda disponibilizada (Fonte: [67]).
Por outro lado, no que diz respeito à largura de banda disponibilizada ao utilizador final, esta tem seguido
quase à regra a lei de Nielsen2
. Utilizando essa mesma regra, e considerando 4Mbit/s (velocidade média
de Internet disponibilizada actualmente ao normal utilizador), estima-se que apenas por volta do ano 2019
a barreira do 1Gbit/s será ultrapassada.
Desta forma, a preocupação com a eficiência do TCP em meios de altos débitos para os utilizadores finais
não é prioritária. A preocupação é totalmente direccionada para as ligações de todo o backbone da
Internet e ligações WAN, principalmente as ligações entre continentes, devido à sua elevada latência. Este
tipo de redes é conhecido como LFN (Long Fat Networks).
Na Figura 3.3 estão dispostas as diversas ligações entre continentes. Essas ligações são as que se sujeitam
mais aos diversos problemas do TCP, considerando as suas versões mais genéricas. Estas ligações variam
na sua maioria de 10Gbit/s a 500Gbit/s, existindo algumas ligações que poderão ultrapassar o limite de
500Gbit/s. As suas latências, geralmente, estão relacionadas com a distância, porém, o próprio meio físico
poderá também estar relacionado. A maioria de todas estas ligações é transatlântica, existindo um número
também significativo na ligação entre a América do Norte e o Japão. O protocolo de transporte utilizado
nestas redes é o TCP em, aproximadamente, 90% das ligações estabelecidas.
2
A Lei de Nielsen é bastante similar à mais popular lei de Moore, a lei defende que considerando o utilizador final, a largura de
banda disponibilizada cresce 50% a cada ano.
16](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-38-320.jpg)

![3. Enquadramento ao Protocolo
Planeamentos de grande procura de largura de banda no futuro e lucro a longo prazo, considerando a
implementação do meio físico apenas numa fase, etc.
• Mecanismos de controlo de congestão, falhas de eficiência a nível do protocolo de transporte, o
TCP.
As razões económicas e de mercado são as maiores responsáveis pela queda acentuada entre tráfego
utilizado e largura de banda disponibilizada. Apesar desse facto, o TCP não está isento de
responsabilidades. O TCP demora bastante a atingir a capacidade máxima da rede, e quando a adquire
existem problemas na sua manutenção (ver Cap. 3.6.1). As redes intercontinentais actuais são, na sua
maioria, construídas usando diversas ligações LFN com routers de alta capacidade. O TCP actual tem de
estar preparado para este tipo de cenário.
As necessidades e motivações aos melhoramentos no protocolo TCP são diversificadas, tais como os seus
variados problemas. Mesmo com todas as limitações, o TCP comportasse até bastante bem na maioria dos
ambientes de rede [9]. Porém, melhorá-lo especificamente para ligações de alto débito poderá trazer
diversas vantagens. Vantagens no campo económico, benefícios ao utilizador doméstico e,
principalmente, o aproveitamento da tecnologia que hoje dispõe são algumas delas.
3.2. O Desenvolvimento
Ao longo do tempo o TCP foi evoluindo de diversas formas, até se tornar no protocolo consistente e
eficaz que hoje é. Como qualquer protocolo, a sua fase inicial diz respeito a todos os mecanismos básicos,
existindo nas fases posteriores um esforço para a sua estabilização e a adição de diversos melhoramentos.
Foram efectuadas diversas melhorias e desenvolvidas várias implementações para aumentar o seu
desempenho, particularmente no caso da rede estar congestionada. O TCP não é desenhado para
funcionar em qualquer tipo de velocidade particular, mas tem o objectivo de usar a banda que lhe
pertence da forma mais eficiente. Essa eficiência foi sempre um ponto crucial, desde a sua especificação
às suas variadas implementações e versões. A Figura 3.7 efectua uma comparação entre a escala temporal
e a largura de banda máxima disponibilizada, representando todos os grandes acontecimentos que
sucederam a este protocolo, com especial ênfase no controlo de congestão do mesmo.
19](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-41-320.jpg)

![3. Enquadramento ao Protocolo
O desenvolvimento foi dividido em três ciclos, bastante fáceis de distinguir devido à divergência de
objectivos.
1ºCiclo – A Especificação
O ciclo inicial que representa todo o nascimento deste protocolo. As primeiras necessidades para a
criação do protocolo, todas as noções teóricas iniciais, os mecanismos básicos para funcionamento
prático, a primeira implementação num sistema operativo, o primeiro algoritmo com o objectivo de
melhorar a eficiência; todos estes são acontecimentos da fase mais imatura deste protocolo.
2º Ciclo – A Congestão
O acontecimento que marca a passagem do 1º para o 2ºciclo é a observação dos colapsos existentes nas
redes de computadores, devido à existência um deficiente controlo de congestão. Foi o 1º grande desafio a
este protocolo. A partir do desenvolvimento do primeiro algoritmo de controlo de congestão, verificou-se
a importância extrema deste tipo de controlo, para toda a eficiência do protocolo. Foram ainda efectuados
ainda outros melhoramentos como o ECN [49] ou o Sack [43].
3ºCiclo – A Congestão em alto débito
Ao contrário do que se passou na passagem do 1º para o 2ºciclo, não existe um acontecimento marcante.
O 3ºciclo começa quando a largura de banda disponibilizada assume valores, aos quais os normais
algoritmos de controlo de congestão e outros mecanismos, não se conseguem adaptar devidamente.
Verifica-se novamente uma perda de eficiência e um novo desafio ao TCP, criando a comunidade de
investigação diversas modificações ao protocolo, com vista a melhorar o seu desempenho em redes de
alto débito.
3.2.1. Entidades e Pessoas
O TCP em todo o seu desenvolvimento esteve ligado a diversas entidades e diversas pessoas. Tal como
qualquer outro protocolo de redes, a entidade principal no que diz respeito à obtenção de standards é o
IETF. Por outro lado, existe um conjunto de entidades e pessoas que são responsáveis pela “alimentação”
de ideias ao IETF, sendo sempre esta a entidade que monitoriza a coerência e efectua a aprovação das
mesmas.
As versões e alguns mecanismos do TCP, ao contrário de muitas modificações em outros protocolos,
estão muito associadas às pessoas responsáveis pelo seu desenvolvimento. Esse facto acontece devido ao
21](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-43-320.jpg)
![TCP em Redes de Elevado Débito
grande esforço individual, desenvolvido pelas mesmas na sua modificação ao protocolo. Um bom
exemplo é o nome dos diversos algoritmos utilizados pelo TCP (ver Cap. 3.3.3).
O esforço dispendido divide-se principalmente em três componentes, que estão também bastante
relacionados com os ciclos de desenvolvimento (ver Cap. 3.2):
• Melhoramentos nos mecanismos genéricos;
• Melhoramentos no controlo de congestão;
• Melhoramentos no controlo de congestão para alto débito.
3.2.1.1. Mecanismos genéricos
Os mecanismos genéricos foram especificados principalmente dentro dos próprios grupo de trabalho da
IETF, sendo ainda hoje esta entidade, a principal responsável pelos melhoramentos e adições deste tipo de
mecanismos. Os dois grupos da IETF relacionados com o TCP actualmente são: TCP Maintenance and
Minor Extensions [68] e Transport Area Working Group [69]. Estes dois grupos são bastante recentes
(2004 e 2001), pelo que na fase inicial do TCP, o grupo responsável por este tipo de mecanismos foi o
Networking Workgroup. Este grupo que na altura incluía tudo o que dizia respeito a redes de
computadores.
O Grupo TCP Maintenance and Minor Extensions é, actualmente, o grupo responsável pelo tipo de
mecanismos genéricos do TCP. É um grupo específico ao protocolo TCP que diz respeito ao
desenvolvimento do que se tratam como pequenos melhoramentos ao protocolo. Para modificações de
maior nível ao protocolo, existe o Transport Area Working Group. Por vezes a dimensão do
melhoramento pode tornar-se complicada de analisar, por essa mesma razão os dois grupos cooperam
bastante entre si, de forma a controlarem os seus âmbitos e objectivos.
A adição ou melhoramento de algum mecanismo genérico, não transforma o TCP numa nova versão, i.e.,
considera-se uma nova versão quando se verifica a existência de melhoramentos ou adições na parte do
algoritmo de congestão AIMD, Slow Start, Fast Recovery, etc. (ver Cap. 3.5). Assim sendo, considera-se
então uma nova versão, quando existe uma modificação significativa na forma de funcionamento do
protocolo, logo os mecanismos/algoritmos de congestão, elaborados pelo IETF e propostos ao IETF,
fazem na sua grande maioria, parte do Transport Area Working Group.
O desenvolvimento de mecanismos genéricos funciona, ainda, em paralelo com todos os melhoramentos
que dizem respeito à congestão, apesar de se ter verificado mais activo no 1ºciclo (especificação do
protocolo) de desenvolvimento.
22](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-44-320.jpg)

![TCP em Redes de Elevado Débito
mais genérica de qualquer implementação TCP, i.e., quando se fala em TCP, normalmente refere-se ao
TCP na sua versão Reno. Para além de ser a versão mais conhecida do TCP, é também a que serve de
base à maioria de todas as outras, principalmente as versões de alto débito (Cap. 3.6).
Para além da extrema importância dos algoritmos desenvolvidos, Van Jacobson deu o primeiro passo para
um largo conjunto de versões e algoritmos específicos para os problemas de congestão de rede. As
comunidades de investigação repararam na extrema importância do problema congestão, e o que ela
implicava na estabilidade e eficiência da Internet. Essa estabilidade e eficiência, proporcionada pelos
diversos melhoramentos feitos vieram impulsionar imenso todo o estudo sobre o TCP.
Van Jacobson contribuiu ainda para diversos mecanismos genéricos do TCP e diversos analisadores de
rede. Na altura do desenvolvimento do TCP Tahoe e Reno, Jabobson investigava no Lawrence Berkeley
Laboratory [70] da Universidade da California, tendo sido contratado com o objectivo urgente de resolver
os colapsos da Internet devido a situações congestão.
Actualmente é investigador na PARC (Paco Alto Research Center) [71]. Recebeu diversos prémios
devido à importância de todo o seu desenvolvimento, entre eles, o ACM SIGCOMM Award 2001e o Koji
Kobayashi Computers and Communications Award por parte da IEEE.
Mais informação: ver http://en.wikipedia.org/wiki/Van_Jacobson
• Lawrence Brakmo
Após o impulso dado pelo TCP Reno ao controlo de congestão, Brakmo especificou e implementou um
algoritmo com o mesmo objectivo do Reno, mas com um funcionamento totalmente diferente. À versão
implementada foi dado o nome de TCP Vegas (ver Cap. 3.5.4), devido principalmente às divergências de
características com o Reno (Vegas é a concorrente do Reno, no que diz respeito à maior cidade de
entretenimento do estado do Nevada, EUA). As versões do TCP para alto débito são sempre baseadas ou
no Reno, ou no Vegas, pelo que a importância da versão de Brakmo passa principalmente pela adição de
uma alternativa aos algoritmos do Reno.
Brakmo investigava no Laboratory of Computer Science da Universidade do Arizona na altura do
desenvolvimento da sua versão.
Mais informação: ver http://www.brakmo.org/lawrence/
24](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-46-320.jpg)
![3. Enquadramento ao Protocolo
• Janey Hoe
Janey Hoe foi a responsável por um melhoramento do protocolo TCP na sua versão Reno. O
melhoramento foi de tal forma importante que modificou o nome da versão, sendo a versão com o
melhoramento efectuado chamada de newReno. A versão newReno encerrou um ciclo de melhoramentos
relacionados com o controlo de congestão, sendo que a sua versão (a mais comum, ver Cap. 3.7),
funciona, apesar das suas limitações, bastante bem na maioria dos meios.
Por vezes nas implementações, não existe distinção entre a versão Reno e newReno, sendo apenas
apresentada a versão Reno, que na realidade é newReno. Hoe investigava no Laboratory for Computer
Science do MIT (Massachutetts Institute of Technology), quando desenvolveu a versão newReno.
Depois do newReno, não é conhecido qualquer desenvolvimento no protocolo TCP por parte de Janey
Hoe. Terminou assim, tanto uma fase de desenvolvimento TCP na área da congestão, como o seu próprio
contributo ao protocolo.
Como já foi referido acima, as versões do protocolo ganham por vezes um carácter muito pessoal. De tal
forma acontece essa situação, que na fase inicial quando apenas a ideia estava especificada, se referia às
versões do TCP como a versão do Jacobson, a versão de Brakmo, ou a versão do Hoe. Apesar desta
situação, existia obviamente um grupo de trabalho mais vasto a trabalhar nas diversas versões. A
importância da própria universidade ao direccionar muita da sua investigação para à área de congestão do
TCP, também não deve ser desvalorizada.
Uma entidade também bastante importante, principalmente no que diz respeito a troca de ideias no meio
académico foi a ACM (Association for Computing Machinery).
ACM/SIGCOMM
Fundado em 1947, teve um papel preponderante na área das telecomunicações, funcionando variadas
vezes quase em regime competitivo com o IEEE (Institute of Electrical & Electronics Engineers) [72].
Apesar da competitividade, as direcções tomadas eram bastante diferentes. O IEEE baseava-se
principalmente na parte da elaboração de standards e hardware; abordando a ACM a parte mais teórica
25](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-47-320.jpg)
![TCP em Redes de Elevado Débito
das redes de telecomunicações, e as relações específicas entre utilizadores e rede. A ACM tinha também
melhor definido o seu principal objectivo: a inovação.
Analisado o âmbito da ACM, não é complicado adivinhar que os algoritmos de congestão do TCP seriam
abordados. Em 1969 foi criado o SIGCOMM dedicada exclusivamente às redes de comunicação. Os SIGs
(Special Interest Groups) [73] são grupos de estudo específico que incluem diversos grupos de
investigação académicos, e que têm associados a distribuição de jornais e conferências sobre a matéria em
questão. O jornal saiu pela primeira vez em 1970, tendo sido organizada a primeira conferência
SIGCOMM em 1986. A conferência anual da SIGCOMM atraiu os melhores artigos e debates sobre rede
de computadores, abordando tanto a parte teórica, como diversos testes práticos.
Alguns desses artigos e debates revelaram-se completamente revolucionários e marcantes. Sendo 1986 (o
mesmo ano da primeira SIGCOMM), o ano em que se começam a verificar os primeiros colapsos na rede
devido a congestão, o TCP teve nas diversas SIGCOMMs, artigos e debates de extrema importância. A
título de exemplo o TCP na sua versão Tahoe foi apresentado na SIGCOMM88, o Reno na
SIGCOMM99, o TCP Vegas na SIGCOMM94 e o TCP newReno na SIGCOMM96 [74]. A SIGCOMM
ainda existe actualmente, mas ao contrário do que aconteceu nas conferências passadas já não é
apresentada investigação absolutamente inovadora, tendo sido o seu prestígio afectado.
Mais informações: ver http://www.acm.org e http:// www.sigcomm.org
3.2.1.3. Melhoramentos controlo de congestão para alto débito
O 2ºCiclo no desenvolvimento do controlo de congestão é marcado pela série de versões do protocolo
TCP na tentativa de o adaptar a diversos meios específicos, principalmente os meios de alto débito. A
abordagem para aumentar a eficiência do TCP foi-se multiplicando pelas comunidades de investigação,
existindo agora métodos implícitos e explícitos (ver Cap. 2.1.5.2) para controlo de congestão que se
foram desenvolvendo após a fase Reno. Existe também um conhecimento bem mais vasto sobre o TCP e
o seu controlo de congestão, o que não se verificava na altura do Reno. Devido a esse conhecimento
formou-se um núcleo bem mais completo na investigação, implementação e documentação de tudo o que
é controlo de congestão. O desafio para o TCP usando banda larga nunca foi tão grande, mas a
comunidade de investigação também nunca esteve tão bem preparada, não existindo maior prova do que a
quantidade de versões existentes.
Novas comunidades deram origem a algumas novas instituições, com pessoas que se notabilizaram pela
eficiência das suas versões e seu empenho no desenvolvimento específico para alto débito.
26](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-48-320.jpg)
![3. Enquadramento ao Protocolo
• ICIR
Em 1999 foi formado o ICIR (Internet Center for Internet Research), pertencente ao ICSI (International
Computer Science Institute) [75]. O ICSI é afiliado com a Universidade da Califórnia, que como foi
referido (ver Cap. 3.2.1.2), tem grande história na investigação sobre controlo de congestão no TCP.
Além disso, surgiu exactamente na altura dessa investigação (1988, TCP Tahoe), muito devido às
limitações dos ambientes de investigação académicos proporcionados pelos laboratórios da universidade.
O ICSI continua a ser uma instituição sem fins lucrativos, mas é bastante mais ligado ao mundo
empresarial e a todo o resto do globo. O ICIR é um grupo de trabalho do ICSI completamente
direccionado para a estabilidade das redes e Internet. Existindo no controlo de congestão uma relação
directa com toda a estabilidade das redes, este grupo foca-se essencialmente neste tipo de controlo.
Mais informações: ver http://www.icir.org/
• Sally Floyd
Sally ingressou no ICIR aquando da criação da entidade. A quantidade de projectos em que se envolveu e
está envolvida é imensa, sendo a principal impulsionadora do desenvolvimento do controlo de congestão
para alto débito e elevadas latências. A sua versão HighSpeed TCP (ver Cap. 3.6.2) é a versão específica
para alto débito mais amadurecida, considerando implementação e testes práticos reais; sendo a versão
mais próxima de se tornar standard para alto débito. Apesar da importância da sua versão, é também a
responsável por mecanismos de congestão explícitos (ver Cap. 2.1.5.2), tais como o QuickStart [54] e o
ECN [49], ou ainda mecanismos de controlo de filas como o RED (Random Early Detection) [76].
A preocupação no desenvolvimento de aplicações simuladoras de variados ambientes de rede é também
uma constante, estando envolvida em diversos projectos do tipo com vista a facilitar cada vez mais
desenvolvimentos na área.
Elaborou diversas RFCs da IETF, mesmo antes de entrar no ICIR, uma delas foi toda a especificação [52]
do algoritmo de congestão de Janey Hoe. Sally continua a investigar no ICIR, sendo a sua página pessoal
um bom ponto de partida para qualquer investigação na área de congestão do TCP para alto débito.
Mais informações: http://www.icir.org/floyd
27](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-49-320.jpg)
![TCP em Redes de Elevado Débito
• PFLDnet
A importância que a PFLDnet (Protocols for fast long distance networks) tem em relação aos
melhoramentos no controlo de congestão para alto débito é muito similar à importância da SIGCOMM
para os normais algoritmos de congestão.
A PFLDnet nasce por diversos motivos: perda de prestígio por parte da SIGCOMM, necessidade de
conferências mais especializadas, a imensa investigação sobre redes de alto débito e seus protocolos.
Devido a todas essas razões, em 2003 surge a primeira conferência, dando origem a apresentações e
debates sobre a globalidade dos assuntos deste tipo de redes. Obviamente os protocolos de transporte
específicos para alto débito foram o assunto principal. Os pontos de destaque em relação ao controlo de
congestão, considerando todas as conferências até agora realizadas, foram:
PFLDnet2003 – HighSpeed TCP (ver Cap. 3.6.2); QuickStart; DCCP (Datagram Congestion Control
Protocol, ver RFC 4340); Scalable TCP (ver Cap. 3.6.3); testes de prova da falta de eficiência; buffers e
sistemas operativos. [77]
PFLDnet2004 – Ponto de situação após primeira PFLDnet; Normalização dos testes; LCA (Loss-Based
Congestion Avoidance) VS DCA (Delay-Based Congestion Avoidance) (ver Cap. 3.5.6); HighSpeed TCP
LP; XCP (eXplicit Control Protocol, ver); Hamilton TCP (ver Cap. 3.6.5); variados testes aos novos
protocolos. [78]
PFLDnet2005 – CUBIC (Versão melhorada do Binary Increase Congestion Control, ver); testes de
atribuição de recursos (fairness); Layering TCP (LTCP); TCP Africa. [79]
PFLDnet2006 – Debates sobre o estado dos variados protocolos; Compound TCP (ver Cap. 3.6.7);
continuação dos testes. [80]
Os assuntos dividem-se entre novos algoritmos de congestão (Highspeed TCP, Scalable TCP, CUBIC,
etc.), mecanismos de congestão explícitos (QuickStart, DCCP, XCP), testes e debates sobre os resultados.
O protocolo de transporte TCP não é o único abordado nestas conferências, existindo também outros
protocolos da mesma camada e investigações em outras camadas. Estar com atenção a tudo o que se passa
nestas conferências é um passo extremamente importante na actualização de todo o desenvolvimento em
28](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-50-320.jpg)

![TCP em Redes de Elevado Débito
3.3. TCP
O principal protocolo da camada de transporte é composto talvez pela maior quantidade de mecanismos
de todos os protocolos de redes. Esse facto acontece devido a interligação do protocolo com variados
meios e tecnologias, obrigando o TCP a estar constantemente a adaptar-se. Todos os mecanismos aqui
referenciados têm uma relação directa com a eficiência nas redes de computadores. Para além desses,
existem outros mecanismos que não serão abordados, por não terem qualquer relação com o âmbito deste
projecto.
Para além dos mecanismos, variados algoritmos foram também desenvolvidos, sendo que o cabeçalho
necessita igualmente apresentação devido à sua importância. A própria apresentação do cabeçalho origina
a posterior apresentação de alguns aspectos diferenciadores deste protocolo de transporte orientado à
ligação5
e Full-Duplex6
.
3.3.1. O cabeçalho
O cabeçalho TCP é o responsável por toda a comunicação entre emissor e receptor. Foi especificado
juntamente com a especificação do protocolo [38], tendo sido alvo, ao longo do tempo, de algumas
modificações, devido principalmente ao seu carácter adaptativo com as diversas tecnologias que vão
emergindo. As modificações passaram essencialmente pela adição de novos campos. O cabeçalho TCP,
sem opções, ocupa exactamente o mesmo tamanho do cabeçalho IPv4 (Internet Protocol Version 4), i.e.,
20 bytes.
Os campos apresentados na Figura 3.9 já incluem os campos adicionados recentemente, sendo que pode
ser encontrado em diversa documentação versões do cabeçalho mais antigas. A vermelho estão os campos
relacionados com o controlo de congestão, os dados estão representados a verde.
5
Existe sempre uma negociação emissor/receptor acerca do estabelecimento de uma sessão de dados.
6
Permite o envio e recepção de ambos os extremos no contexto de apenas existir uma sessão estabelecida.
30](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-52-320.jpg)

![TCP em Redes de Elevado Débito
• Flags
Existem duas flags directamente ligadas ao controlo de congestão explícito (ver Cap. 2.1.5.2) adicionadas
mais recentemente (ano de 2001) [81].
- A flag ECE tem o objectivo de negociar o mecanismo de ECN entre dispositivos;
- A flag CWR (Congestion Window Reduced) é activada depois da negociação, sendo um pedido explícito
para reduzir a taxa de transmissão do emissor;
Todas as outras flags não estão relacionadas com mecanismos de congestão, servindo como bits de
controlo de variadas situações.
- A flag URG activa o campo Urgent Pointer fazendo com que o pacote seja marcado como urgente. O
que fazer com pacotes deste tipo depende das aplicações;
- PHS é a abreviação para Push. Quando esta flag está activa, o receptor notifica o emissor para que que
envie todos os dados que tem, sem que seja considerado o campo Window. Esta flag não é praticamente
utilizada, pelo que as implementações não costumam fornecer, sequer, forma de a activar;
- As flags RST, SYN e FIN servem para controlo das sessões de dados. RST abrevia Reset, requisitando
uma paragem brusca na sessão de dados. A SYN notifica o estabelecimento de uma sessão TCP (SYN é a
abreviatura de Syncronization). FYN abrevia Finalize, terminando a sessão de dados normalmente.
• Window
O número de bytes que o receptor está preparado para receber.
• Checksum
Para detecção de erros do cabeçalho e dos dados.
• Urgent Pointer
Se a flag URG estiver activada, então este campo representa o endereço do último segmento TCP urgente.
• Options
O campo Options é responsável por toda a parte opcional do cabeçalho TCP, permitindo assim ao
cabeçalho uma maior capacidade de adaptação às diversas situações a que está sujeito. A única opção
definida na primeira especificação do cabeçalho foi a opção MSS (Maximum Segment Size). Actualmente
existem diversas opções [82] tendo sido os meios de alto débito, um dos principais responsáveis [RFC
1323] pelo aumento das mesmas. Devido à abundância desses meios, actualmente, essas opções
tornaram-se as mais utilizadas.
As opções mais importantes estão todas relacionadas com a requisição de eficiência por partes da rede,
algumas delas são: MSS, Timestamp, Window Scale, Sack Permitted e Sack.
32](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-54-320.jpg)
![3. Enquadramento ao Protocolo
- O MSS permite a um extremo da rede notificar o outro acerca do tamanho máximo do segmento TCP
que poderá enviar. Esta função, combinada com o facto de o próprio emissor poder também limitar os
segmentos que envia através do MTU (Maximum Trasmit Unit), evita que o segmento TCP seja
fragmentado em caminhos com MTU pequeno. A opção MSS armazena o valor máximo do segmento
TCP;
- A Timestamp Option foi das primeiras opções a ser criada devido ao aparecimento das redes de alto
débito. O seu objectivo principal é uma medição mais precisa do RTT (Round Trip Time, ver Cap.
3.3.2.3). Este mecanismo será explicado em maior detalhe no 3.3.4.1.
- A Window Scale Option foi também criada principalmente devido às redes de alto débito. O objectivo é
aumentar o número de bits que o normal campo Window permite, sendo este campo um valor escalar que
multiplica o valor existente pelo campo Window inicial. O mecanismo que utiliza esta opção será também
explicado em maior detalhe no Cap. 3.3.4.2.
- Sack Permitted e Sack são duas opções que pertencem ao mecanismo Sack (Selective Acknowledgment,
ver Subsecção). Uma delas é responsável pela negociação emissora/receptor sobre a utilização do Sack
durante a ligação. Se o Sack for activado na ligação, a opção Sack será a responsável pelos blocos de
segmentos já recebidos pelo receptor.
Todas estas opções são negociadas durante o estabelecimento da sessão dados, i.e., em pacotes com a flag
SYN activa. É pois necessário que emissor e receptor permitam o uso da respectiva opção.
As seguintes figuras são parte de uma normal conexão em HTTP (hypertext transfer protocol) à Internet.
Foram capturadas pelo analisador de tráfego Ethereal [83]. Nas duas figuras são visíveis os estados de
todos os campos do cabeçalho perante diferentes situações.
A Figura 3.10 é o primeiro segmento TCP, sendo responsável pelo estabelecimento da sessão. O número
de sequência é mostrado como “relative sequence numbers”, sendo representado por “0”. Esta situação
acontece na maioria dos analisadores de tráfego, com o intuito de facilitar resoluções de problemas no
estabelecimento da ligação. O número de sequência real, neste caso, será um número completamente
aleatório, sendo os segmentos TCP seguintes até ao estabelecimento da ligação esse número mais um,
consecutivamente (no analisador as sequências são representadas por 1, 2, 3, 4, etc.).
Nas flags verifica-se que o SYN está activo, sinal que está a ser estabelecida uma ligação. Os próximos
pacotes até ao final do estabelecimento também terão a flag SYN activada.
O tamanho da Window que é notificado é o tamanho máximo do campo Window (o campo window tem
16 bits, 65535). Para mais do que 65535 bytes é necessário usar a Window Scale Option (ver ).=16
2
33](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-55-320.jpg)

![3. Enquadramento ao Protocolo
segmento volta a ser retransmitido. Para este procedimento o emissor guarda uma cópia do
segmento transmitido, pronta a ser retransmitida;
• Quando o TCP recebe os segmentos de dados do receptor ele envia uma notificação ao emissor,
essa notificação é chamada de acknowledgement, ou abreviando, ack;
• TCP mantém um checksum no seu cabeçalho. O checksum é extremo-a-estremo, com o objectivo
de detectar qualquer modificação dos dados na rede. Se um segmento chegar ao receptor com o
checksum inválido o TCP automaticamente o descarta, não transmitindo qualquer ack de
recepção.
• Os segmentos TCP são transmitidos em pacotes IP, podendo chegar fora de ordem ao receptor
por diversas razões, algumas delas de encaminhamento. Devido a essa razão, o receptor TCP
consegue voltar a sequenciar os dados se necessário, passando os dados de forma correcta para a
aplicação;
• Os dados podem também chegar em duplicado, nesse caso o receptor TCP descarta os pacotes
redundantes;
• Cada extremo de uma conexão TCP tem um tamanho de buffer finito. O receptor TCP só permite
ao outro extremo lhe enviar dados para os quais o seu buffer está preparado. [1]
Todos estes funcionamentos são conseguidos através de mecanismos interligados, sendo a base de todo o
protocolo. Para qualquer posterior desenvolvimento a nível de congestão no TCP é necessária a
aprendizagem de alguns deles, principalmente aqueles directamente ligados à eficiência.
3.3.2.1. Acks e Piggybacking
Os acks são uma presença constante em todos os protocolos orientados à ligação, esta situação não foge a
regra no protocolo TCP. Numa sessão de dados os acks servem, essencialmente, para existir notificação
de recebimento por parte de determinada entidade receptora, a partir daí a entidade emissora descarta toda
a responsabilidade no envio do segmento TCP a que foi notificada a recepção. A entidade receptora será
agora a responsável por todo o posterior tratamento ao segmento, sendo o seu normal destino os buffers
do processo aplicacional. Outro procedimento que irá acontecer no receptor é o descarte da cópia
guardada do segmento a que foi notificada a recepção, o que irá disponibilizar mais espaço no buffer
emissor.
Cada ack preenche o campo number acknowledgement com o próximo número de sequência que pretenda
receber. Se entretanto o segmento TCP que se pretenda não chegue ao receptor, o ack enviado para cada
segmento TCP recebido (que não seja o pretendido), é o ack com o pacote pretendido.
35](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-57-320.jpg)




![TCP em Redes de Elevado Débito
• A janela abre quando o limite direito avança para a direita, permitindo a mais dados serem
enviados. Esta situação acontece quando o processo aplicacional receptor liberta dados no buffer,
sendo posteriormente aumentado o valor da janela oferecida;
• A janela encolhe quando o limite direito se movimenta para o lado esquerdo. Esta situação
acontece quando o valor da janela oferecida é diminuído. Esta situação não é aconselhada
[RFC1222].
Estes três movimentos estão representados sucintamente na Figura 3.17.
Figura 3.17 – Movimentos do Sliding Window.
Com Sliding Window, para cada segmento recebido não é necessário uma notificação imediata do ack,
sendo o ack enviado posteriormente, utilizando a propriedade cumulativa. Além disso, devido ao facto do
Sliding Window manter a rede completamente saturada com segmentos, consegue um melhor throughput
do que um protocolo apenas com o simples mecanismo de acks [2].
O Tamanho da janela (buffer)
O processo aplicacional a usufruir largura de banda de rede é, geralmente, o principal responsável pelas
respectivas mudanças no tamanho da janela disponível. A Figura 3.18 exemplifica todo o funcionamento
de libertação do buffer, e posterior aviso da janela. O pacote IP é entregue pela camada de rede e é
processado pelo TCP até entrar para o processo aplicacional; quanto mais rápido for o processo a tratar os
dados, mais vazio ficará o buffer, sendo posteriormente maior o valor da janela oferecida.
Figura 3.18 – Relação Window/Buffer.
40](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-62-320.jpg)
![3. Enquadramento ao Protocolo
O tamanho da janela8
é um aspecto que afecta directamente a perfomance do TCP. O tamanho da janela
deve ser adaptado à disponibilidade da largura de banda e ao atraso da ligação em questão. Maiores
larguras de banda e maiores atrasos implicam sempre maiores janelas.
Alguns sistemas operativos limitam também a perfomance TCP por não terem o tamanho de janela
adequada às ligações de que usufruem, um desses casos é o Windows XP. O sistema operativo mais
usado nos dias de hoje utiliza para ethernet uma janela de 17520KBytes, i.e., utiliza aproximadamente
metade do valor máximo da janela, podendo piorar se o outro extremo utilizar Options como Sack ou
Timestamp. Em ligações ethernet que suportem 1Gbit/s, a largura de banda nunca consegue ser
correctamente aproveitada com uma janela deste tamanho [84], mesmo com atrasos na ordem dos 0.1ms.
A janela pode ser aumentada no sistema operativo [85] melhorando a perfomance, mas o aproveitamento
total da largura de banda nunca é conseguido. É de referir que a versão de TCP (TCP Reno) utilizada no
Windows também prejudica a perfomance, considerando ligações de alto débito (ver Cap. 3.6.1).
No Linux o tamanho da janela vem por omissão o máximo (64K), sendo a perfomance a mesma que nos
sistemas Windows, se for considerada a mesma versão de protocolo e o mesmo atraso.
O tamanho da janela TCP de forma a utilizar a largura de banda de forma eficiente pode ser calculado
utilizando a seguinte fórmula:
(sec)*sec)/(arg)( RTTbitsbandadeuraLBDPCapacidade =
Esta fórmula permite-nos obter a capacidade da rede, também chamado de BDP (Bandwidth Delay
Product). Este valor pode variar, tal como foi dito anteriormente, conforme os valores de largura de banda
e RTT. O valor da janela para aproveitar a largura de banda de forma eficiente é igual ao valor do BDP. O
valor recomendado é duas vezes o BDP.
Existem também algumas recomendações acerca do valor inicial da janela por parte da IETF [50].
A Relação com o RTT
Podemos comparar o RTT com o comprimento de um canal de dados. Se o comprimento do canal de
dados é maior, então existirá consequentemente uma maior capacidade da rede (BDP) no transporte dos
dados. Existindo mais capacidade, significa automaticamente, mais segmentos TCP a circular na rede. A
Figura 3.19 exemplifica a relação entre segmentos e RTT; o dobro do RTT, o dobro dos segmentos.
8
Janela neste caso é o equivalente a dizer “buffer”. Existe também a definição de “window” como buffer disponível, como é o
caso da Figura 3.17. A razão é esse ser o nome do campo do cabeçalho TCP.
41](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-63-320.jpg)


![TCP em Redes de Elevado Débito
janelas nos próprios sistemas operativos, ou utilizando a Window Scale Option (ver Cap. 3.3.4.2). Novos
problemas a que estão inerentes as ligações de alto débito irão sendo explicados.
Silly Window Syndrome
A condição Silly Window Syndrome10
pode acontecer em qualquer implementação que possua
mecanismos de janela. Foi verificada pela primeira vez formalmente em 1982 [39]. O que se verifica,
quando esta situação ocorre, são pequenas trocas de segmentos TCP em vez dos segmentos completos.
A causa é muitos simples, o receptor está constantemente a oferecer pequenas janelas, em vez de esperar
por maiores janelas. Do outro lado, o emissor está constantemente a enviar pequenos segmentos de dados
em vez de esperar por dados adicionais. A Figura 3.23 representa todo o processo de ocorrência do Silly
Window Syndrome. A janela (buffer) do receptor está cheia sendo que a aplicação lê apenas um byte da
janela, libertando 1 byte na respectiva janela; o byte livre é então notificado ao emissor; o emissor
transmitirá então um segmento com 1 byte, enchendo de novo a janela.
Figura 3.23 – Reprentação do Silly Window Syndrome (Fonte: [3]).
As soluções passam por modificações por parte de emissor e receptor. Em relação ao receptor a solução é
clara: o emissor não deve oferecer pequenas janelas. A janela só deve então aumentar perante duas
situações:
• A janela pode ser aumentada até ao valor de um segmento TCP (utilizando o valor MSS
negociado);
• A janela pode ser aumentada, apenas, até ao valor da sua metade.
10
Por vezes também referenciado como SWS. Devido ao facto de não ser um protocolo ou mecanismo optou-se pela definição
extensa.
44](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-66-320.jpg)
![3. Enquadramento ao Protocolo
No extremo responsável pela emissão as seguintes opções devem ser tomadas, bastando uma ser
verdadeira para se poder executar o envio:
• Enviar apenas quando um segmento TCP tem o seu valor máximo (utilizando o valor MSS
negociado);
• Enviar apenas quando o segmento é, pelo menos, metade da maior janela alguma vez oferecida
pelo receptor;
• Enviar todos os dados em buffer caso existam dados por confirmar (à espera de ack) não estando
o algorirmo de Nagle (ver Cap. 3.3.3.1) activo.
A situação de Silly Window Syndrome está directamente relacionada com o persist timer (ver Cap.
3.3.2.4) e com o algoritmo de Nagle. As ligações mais sujeitas a esta situação são claramente ligações
com emissores rápidos e receptores lentos.
3.3.2.3. Estimação do RTT
“Um bom estimador de RTT, o núcleo do temporizador de retransmissão, é a mais importante
característica para a implementação de um protocolo que pretende suportar grandes cargas”. [13]
A medição do RTT tem sido alvo de preocupação desde a inicial especificação do TCP [38], tendo
sofrido duas importantes modificações. O RTT reflecte o estado da rede, sendo, tal como o desempenho
das ligações, bastante variável ao longo do tempo da sessão de dados. A estimação correcta de toda essa
variância é o objectivo de toda a estimação do RTT.
A primeira medida que o TCP efectua é o cálculo em relação a um segmento TCP e respectivo ack,
garantindo a receptividade desse segmento. É de realçar de novo a propriedade cumulativa, que neste caso
é o principal problema de medição RTT, na medida em que não existe uma relação de um para um entre
segmento TCP e respectivo ack.
A especificação inicial calculava o RTT através de uma relação ponderada entre o RTT medido11
e o
antigo RTT. A relação é dada pela seguinte fórmula:
MRR )1( αα −+←
RTTEstimadorR =
11
Sempre que se falar de RTT medido, está-se a referir à medição entre segmento TCP e qualquer ack que notifique a sua
receptividade.
45](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-67-320.jpg)
![TCP em Redes de Elevado Débito
medidoValorM =
9.0== entoarredondamdefactorα
Sendo o factor de arredondamento aconselhado igual a 0.9, 90% do valor calculado (R) irá ter como base
o antigo valor, e 10% do valor calculado irá ter como base o novo valor medido. A passagem de RTT
para o temporizador, também conhecido como RTO (Retransmission Timeout Value) é feita com recurso
a outra fórmula:
βRRTO =
2== atrasodoriaçãovadefactorβ
O factor de variação do atraso é recomendado na especificação ser igual a 2. Este factor de variação pode
ser optimizado à ligação conforme os seus atrasos inerentes.
Van Jacobson (ver Cap. 3.2.1.2) detalhou os problemas desta fórmula [13] na estimação dos RTT,
nomeadamente o facto da variação do atraso ser um parâmetro difícil e pouco coerente de escolher,
obrigando muitas vezes a retransmissões desnecessárias. Foram então definidas novas fórmulas que
estimam o RTT com base na média e variância:
AMErr −=
médiaA =
medidoValorM =
Esta primeira fórmula é também responsável pelo cálculo da média de todos os RTT calculados. Err é a
diferença entre o valor RTT medido é a média. A média e o desvio são calculados da seguinte forma:
)|(| DErrhDD −+←
gErrAA +←
DesvioD =
4
1
== desviodoganhoh
8
1
== médiadaganhog
A média tem um valor ponderado g que é recomendado de valor 0.125. De igual forma existe um ganho h
para o desvio com recomendação de 0.25. Ao ser aumentado o ganho do desvio, significa que o RTO terá
um aumento mais acentuado. O RTO é dado por:
46](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-68-320.jpg)
![3. Enquadramento ao Protocolo
DARTO 4+=
Existem porém uma modificação para a situação inicial na troca de dados:
DARTO 2+=
Esta última fórmula faz com que o RTO não seja tão elevado na sua fase inicial. A Figura 3.24 representa
uma comparação do valor estimado com o valor real fornecido por um analisador de tráfego; o eixo dos
xx é o valor RTT/RTO, o eixo dos yy o tempo em segundos; no início o valor calculado (calculated RTO)
começa por ser alto, tornando-se a estimação ao longo do tempo de transmissão bem mais perfeita.
Figura 3.24 – Cálculo do RTT medido por analisador de tráfego, comparado com o calculado TCP (Fonte: [1]).
A segunda modificação, a adição de um campo timestamp option já teve a sua introdução anteriormente
(ver Cap. 3.3.1) e vai ser explicada em maior detalhe na (ver Cap. 3.3.4.1).
A implementação das formas de estimar o RTT varia imenso. Existem pequenas modificações nas
fórmulas, medições feitas apenas por janela, etc. Essencialmente é o tipo de ligações que define as
implementações; por exemplo, no caso de existir apenas uma medição do RTT por janela, essa situação
funciona bastante bem para baixas larguras de banda, mas levanta diversos problemas para alto débito,
onde uma estimação detalhada do RTT se revela crucial.
A estimação do RTT está directamente associada a um temporizador de retransmissão, porém esta
associação verifica-se apenas para a primeira retransmissão. Existem também algumas situações onde o
RTT não deve ser medido (ver Cap. 3.3.3.2). O funcionamento dos temporizadores após a primeira
retransmissão vai ser explicada seguidamente.
47](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-69-320.jpg)
![TCP em Redes de Elevado Débito
3.3.2.4. Os Temporizadores
“Um elemento crítico de qualquer implementação é a estratégia timeout/retransmissão”. [1]
Os temporizadores são essenciais a toda a eficiência da rede, na medida em que mal configurados podem
significar desnecessárias transmissões/retransmissões. As retransmissões são iniciadas por dois tipos de
eventos: timeouts e acks duplicados; as retransmissões devido a acks duplicados são explicadas no Cap.
3.5.1.1.
Retransmit timer
A implementação/configuração do retrasmit timer12
pode por vezes se tornar complicada. Algumas
complicações surgem perante as seguintes situações:
• Timeout um pouco maior que o RTT;
Esta situação é a mais comum. Se tudo estivesse em equilíbrio então a situação ideal seria o temporizador
igual ao RTT, porém os atrasos vão variando ao longo de toda a ligação e têm que ser definidas margens
de aceitação para certos atrasos. A solução neste caso prende-se essencialmente com uma correcta
estimação do RTT, e um bom conhecimento da rede em questão, principalmente os atrasos a que pode
estar inerente.
• Timeout demasiado pequeno;
Esta situação pode ocorrer, geralmente, quando a rede está sujeita a muitas perdas e tem poucos atrasos,
nesse caso são usados temporizadores pequenos pois o grau de desconfiança na rede é elevado.
Temporizadores pequenos em redes com algum atraso e perdas pouco relevantes significam, geralmente,
retransmissões desnecessárias.
• Timeout demasiado longo;
Situação ocorrente quando existe um grau de confiança elevado na rede (em relação às perdas), ou o
atraso da rede é elevada. Numa rede que não reúna essas características irá ser verificado uma reacção
bastante lenta aquando da perca de um qualquer segmento TCP.
Quando ocorre um timeout são executadas duas operações: retransmissão do segmento TCP que causou o
timeout e o reiniciar do temporizador. O temporizador altera também o seu tempo conforme o número de
12
Termo mais usado, que corresponde a temporizador de retransmissão.
48](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-70-320.jpg)


![3. Enquadramento ao Protocolo
Delayed Ack Timer
Na parte do receptor existe o delayed ack timer. Este temporizador define o tempo que o receptor deve
esperar, entre o correcto receber do segmento e o envio do respectivo ack. A espera é útil para
optimização da largura de banda, notificando vários segmentos num só ack (propriedade cumulativa),
sendo também útil para o mecanismo de piggybacking (ver Cap. 3.3.2.1). Os valores de timeout deste
temporizador variam bastante de implementação para implementação, sendo o valor mais usado 200ms.
3.3.2.5. Sack
O Sack é um protocolo especificado formalmente em 1996 [43] com o objectivo de melhorar todo o
mecanismo de acknowledgment. Os mecanismos de acknowledgment (ver Cap 3.3.2.1) devido à
propriedade cumulativa têm algumas vantagens e desvantagens, o Sack fixou-se em todas a desvantagens
desta propriedade. As desvantagens são:
• A recepção de segmentos fora de sequência nunca tem associado um ack;
• O receptor manda acks duplicados;
• O emissor apenas pode receber uma notificação de segmento recebido (ack) por RTT.
Este protocolo usa as opções do TCP Sack Permitted e Sack (ver Cap. 3.3.2.5). A opção Sack armazena os
blocos de dados que já foram recebidos, permitindo ao protocolo TCP, além da notificação do normal
ack, a notificação de diversos blocos de dados já recebidos. A Figura 3.27 exemplifica o funcionamento
do Sack; São enviados 5 blocos de dados (100, 200, 300, 400 e 500), 2 deles (200 e 400) são perdidos;
após o esgotar do delay ack timer é enviado o normal ack 200, mas com a notificação de que os blocos
500-600 e 300-400 já foram recebidos, ajudando assim o emissor a melhor decidir o que transmitir.
Figura 3.27 – Exemplo de funcionamento do protocolo Sack.
51](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-73-320.jpg)
![TCP em Redes de Elevado Débito
A Sack Option é de comprimento variável, com limite para quatro blocos, sendo composta da forma
representado na Figura 3.28. O limite direito representa o primeiro número de sequência desse bloco, o
limite esquerdo é o número a seguir ao último número de sequência do bloco.
Figura 3.28 – Representação dos blocos da Sack Option.
Existe uma extensão feita a este protocolo a que foi dado o nome de D-Sack [47] . Esta opção pretende
utilizar o primeiro bloco Sack para notificação de segmentos duplicados. O objectivo principal é notificar
ao emissor que foram efectuadas retransmissões desnecessárias. Desta forma, o emissor poderá reagir,
anulando por exemplo os algoritmos de controlo de congestão. Esta extensão ainda possui poucas
implementações e quando existe implementação não se verifica por omissão.
3.3.3. Os algoritmos
Existem vários tipos de algoritmos no TCP. Um algoritmo no TCP caracteriza-se por poucas linhas de
código, aquando das implementações. Geralmente alteram também de forma muito significativa o
desempenho da rede. Os algoritmos surgem, também geralmente, associados ao seu criador dividindo-se
em três tipos:
• Algoritmos de controlo de congestão;
Algoritmos que previnem o emissor de não congestionar toda a rede.
• Algoritmos de controlo de erros;
Algoritmos de recuperação para situações de perdas de segmentos.
• Algoritmos de controlo de fluxo.
Algoritmos que previnem o emissor de não sobrecarregar o receptor com informação, tentando que o
mesmo envie os dados de forma adequada à largura de banda.
O objectivo de cada tipo de algoritmo é diferente, mas toda a implementação é feita de forma combinada,
fazendo com que uma correcta separação entre eles não se verifique simples de efectuar.
52](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-74-320.jpg)
![3. Enquadramento ao Protocolo
Os algoritmos de congestão e de controlo de erros vão ser analisados mais à frente (ver Cap. 3.6), sendo
agora analisados dois algoritmos, correspondentes ao controlo de fluxo.
3.3.3.1. Algoritmo de Nagle
O primeiro algoritmo, definido para optimizar a ocupação da rede por parte do TCP, foi especificado em
1984 [40]. O nome atribuído foi o nome do seu criador (John Nagle), tendo sido um algoritmo criado na
fase inicial dos colapsos da Internet (ver Cap. 3.2) e por isso considerado, por vezes, o primeiro algoritmo
de congestão. Porém, geralmente são referidos como algoritmos congestão outro tipo de algoritmos,
criados um pouco mais tarde (ver Cap. 3.6).
O algoritmo especifica que quando uma ligação TCP tem segmentos que ainda não foram confirmados da
recepção, pequenos segmentos não podem ser enviados, até que os acks sejam recebidos. Em vez dessa
situação, pequenas quantidades de dados da aplicação vão sendo somadas, sendo posteriormente enviadas
apenas num segmento TCP quando todos os ack chegarem. O algoritmo é extremamente simples e de
uma tremenda utilidade, pois em situações de congestão, se existirem aplicações interactivas16
na rede o
desempenho da rede aumenta exponencialmente. Além disso, não precisa de qualquer tipo de
sincronização adicional, pois à medida que a rede vai ficando descongestionada (acks a chegar) mais
rápida será a transmissão dos dados.
3.3.3.2. Algoritmo de Karn
Especificado em 1987 [10], este algoritmo está directamente ligado à estimação de RTT (ver Cap.
3.3.2.3). Phil Karn reparou num problema de ambiguidade durante as retransmissões a que foi dado o
nome de retransmission ambiguity problem.
Um segmento é transmitido e para esse segmento o retransmission timer esgota, enviando um novo
segmento; de seguida é recebido um ack do segmento retransmitido. A pergunta que agora se faz é se este
ack é do segmento transmitido atrasado ou do segmento restransmitido? A resposta seria fácil se existisse
forma de saber que o primeiro segmento tinha sido perdido, porém não existe nenhum mecanismo que
permita essa verificação. De qualquer forma, se ele for correctamente recebido não há forma alguma de
saber a que segmento se refere o ack. A Figura 3.29 representa a situação de ambiguidade atrás explicada.
16
Este tipo de aplicações tem a característica de enviar uma grande quantidade de pequenos segmentos de dados para a rede.
53](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-75-320.jpg)

![3. Enquadramento ao Protocolo
problemática surge quando os números de sequência esgotam antes do tempo deste temporizador,
fazendo com que os números de sequência se possam repetir na mesma ligação.
Para a solução destes três problemas foram criados três mecanismos especificados em 1992 [42],
juntamente com as alterações ao cabeçalho.
3.3.4.1. Timestamp Option
A timestamp option foi a última modificação mais relevante, aplicada aos estimadores de RTT. O
conceito é a adição de uma nova marcação de tempo em cada segmento TCP. A essa marcação, o receptor
responderá na forma de um echo reply17
. A forma como essa opção está estruturada é representada na
Figura 3.30. O primeiro campo (TS Value) é preenchido pelo emissor, o segundo campo (Tsecr) é
preenchido pelo receptor.
Figura 3.30 – Representação dos campos do Timestamp Option.
Existem várias considerações a ter nesta troca de valores. O facto de o preenchimento ser um echo reply
traz consigo duas vantagens: não é necessário qualquer tipo de sincronização (para além da já existente
nos normais mecanismos TCP), não é necessário o receptor saber como está estruturada a informação no
campo preenchido pelo receptor. O valor do TS Value é um valor fornecido pelo relógio do sistema.
Também devido ao echo reply por parte do receptor foi necessário a criação de duas formas de
funcionamento:
• Se um ack estiver a utilizar a propriedade cumulativa a notificar o emissor, o valor do Timestamp
Option será sempre o do primeiro segmento que for recebido;
• Se um segmento estiver fora de sequência, implicando que um antigo segmento foi perdido,
quando esse segmento é recebido, o valor da Timestamp Option será o do segmento perdido.
Através destes mecanismos, esta opção permite saber para além do RTT do último segmento a ser
recebido, o do primeiro. Desta forma o RTT terá uma melhor estimação, ganhado o TCP uma melhor
preparação para redes de alto débito.
17
O emitido pelo emissor será igual ao preenchido pelo receptor.
55](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-77-320.jpg)



![TCP em Redes de Elevado Débito
Figura 3.32 – Exemplo hidráulico de uma situação de congestão (Fonte: [3]).
Devido ao facto de as redes de computadores, principalmente a Internet, não terem a mesma capacidade
ao longo da ligação, entende-se facilmente a razão dos colapsos. Assim sendo, a solução foi abordar os
problemas de duas formas: o controlo da capacidade da rede e o controlo da capacidade do receptor.
As soluções vieram em forma de versões TCP com os seus algoritmos de congestão que se vieram a
verificar de extrema importância.
3.5.1. TCP Tahoe
“Os caminhos óbvios para implementar um protocolo de transporte baseado em janela, pode resultar,
exactamente, no comportamento errado no que diz respeito à congestão da rede”. [13]
O TCP Tahoe é especificado em 1988 [13], num paper que se viria a tornar um clássico23
no ramo das
redes de computadores. O nome “Tahoe” não surgiu aquando da sua especificação, sendo o nome
atribuído, posteriormente, após implementação dos algoritmos e mecanismos de congestão em BSD
(Berkeley Software Distribution). A versão é caracterizada essencialmente pela adição de uma nova
janela (janela de congestão), e os algoritmos de congestão Slow Start e Fast Retrasmit.
23
Definição usada para referir algo que, actualmente, ainda se verifique uma grande referência.
60](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-82-320.jpg)
![3. Enquadramento ao Protocolo
3.5.1.1. Janela de Congestão
A janela de congestão24
é uma segunda janela, com o intuito de solucionar a situação de congestão na
rede (a congestão no receptor é já solucionada pela janela referida anteriormente). A janela de congestão
não tem qualquer tipo de relação com o receptor, funcionando como uma forma de controlo de fluxo por
parte do emissor. O papel do emissor será transmitir o mínimo destas duas janelas; o receptor pode
oferecer assim determinada janela, mas o emissor através da sua janela de congestão poderá saber que ao
injectar segmentos até aquele limite irá congestionar a rede. A Figura 3.33 exemplifica a relação entre as
duas janelas. A janela irá oferecer 8Kb ao emissor para enviar, por outro lado a sua janela de congestão só
lhe permite 4Kb; finalmente serão enviados os 4Kb.
Figura 3.33 – Funcionamento da janela de receptor/janela congestão.
A janela de congestão irá funcionar em conjunto com os algoritmos de congestão, variando o seu valor
conforme os acontecimentos da rede. É de referir também que o valor da janela é medido em bytes e não
em segmentos.
3.5.1.2. Slow Start
“Um novo pacote não pode ser colocado na rede até que um velho pacote saia. A física do fluxo prevê
que os sistemas com esta propriedade deve ser robustos em relação à congestão“. [13]
O mecanismo de acks (ver Cap. 3.3.2.1) funciona basicamente como o relógio do TCP. Essa situação
permite ao TCP adquirir outra propriedade: self-clocking25
. Esta propriedade permite ao TCP adquirir um
determinado ritmo, onde os acks conseguem ser gerados à mesma velocidade dos segmentos. Desta forma
é atingido o estado de equilíbrio representado na Figura 3.34, onde os variados tempos de transmissão são
sempre mantidos.
24
Muitas vezes referenciado como congestion window ou cwnd.
25
Termo mais usado, correspondente a auto sincronização.
61](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-83-320.jpg)
![TCP em Redes de Elevado Débito
Figura 3.34 – Representação do estado de equilíbrio (Fonte: [13]).
O objectivo será, então, conseguir manter este estado de equilíbrio na rede. O problema principal é iniciar
esse mesmo estado de equilíbrio, sendo o Slow Start, o responsável por essa mesma inicialização.
O processo de funcionamento do Slow Start é observar a velocidade a que devem ser injectados os
segmentos na rede, através da velocidade a que os acks são devolvidos por parte do receptor.
O valor inicial da janela de congestão representa o primeiro segmento que será enviado, esse valor será o
MSS negociado, aquando do estabelecimento da ligação. A partir do primeiro segmento enviado, para
cada ack recebido (do segmento enviado), a janela de congestão será incrementada em mais um
segmento.
A Figura 3.35 demonstra este comportamento. O emissor começa por transmitir um segmento e espera
pelo seu ack; quando o ack é recebido a janela de congestão é aumentada de 1 (1) para 2 (2, 3) segmentos;
quando cada ack desses segmentos chega ao emissor, a janela de congestão é aumentada para 4
segmentos (4, 5, 6, 7); após os acks, a janela aumenta para 8 segmentos (8, 9, 10, 11, 12, 13, 14, 15); a
multiplicação continua a subir exponencialmente até ocorrer alguma situação que active outro algoritmo.
Figura 3.35 – Representação do comportamento do Slow Start (Fonte: [13]).
62](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-84-320.jpg)
![3. Enquadramento ao Protocolo
Como já foi anteriormente referido (ver Cap. 3.2), as primeiras implementação foram feitas em BSD que
na altura ia na sua versão 4.3. Uma exemplo de uma rede com essa implementação é representado na
Figura 3.36. A rede em questão é uma rede ethernet de 10Mbit/s característica da altura, com ligação
backbone de 230.4Kbit/s; o eixo dos xx representa o tempo, o yy representa o número de sequência dos
segmentos, a linha a tracejado representa a largura de banda disponibilizada; para aproveitar ao máximo
os segmentos deviam seguir a linha a tracejado, porém, esse comportamento não se verifica, sendo o
tráfego caracterizado por constantes retransmissões que pioram ao longo do tempo, existindo até
segmentos retransmitidos 4 e 5 vezes. O aproveitamento da largura de banda por parte desta rede, não
surpreendentemente, será cerca de 35%.
Figura 3.36 – Representação da perfomance de uma implementação 4.3BSD (Fonte: [13]).
A mesma rede, com exactamente as mesmas configurações da representada na Figura 3.35, sendo alterado
apenas a implementação para BSD 4.3+, é agora representada na Figura 3.36. Esta implementação foi
uma versão intermédia entre a versão BSD 4.3 e a BSD 4.3 Tahoe, que apenas implementava o algorimo
Slow Start. Os melhoramentos verificados são: excepto até ao 16º segmento, os segmentos seguem
exactamente a linha da largura de banda disponibilizada; são correctamente26
enviados cerca de 155
segmentos, ao longo de aproximadamente 9 segundos (para o mesmo tempo, a antiga implementação
enviava correctamente cerca de 65). Não existe qualquer retransmissão, limitando os “tempos mortos” do
emissor ao tempo de chegada dos acks.
26
Correctamente neste caso implica o envio sem descarte e com ack (excepto nos segmentos finais que poderão ainda não ter
sido notificados).
63](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-85-320.jpg)
![TCP em Redes de Elevado Débito
Figura 3.37 – Representação da perfomance de uma implementação 4.3 BSD+ (Fonte [13]).
A única desvantagem que se retira deste algoritmo são os 2 segundos iniciais em que se afasta um pouco
da largura de banda disponibilizada, após os 2 segundos o termo “slow” 27
perde todo o seu sentido,
superando em velocidade de pacotes enviados correctamente qualquer outra implementação feita.
A melhoria de perfomance proporcionada por este algoritmo em relação aos normais mecanismos
implementados não deixou qualquer dúvida às comunidades de investigação, passando rapidamente a ser
adoptado em qualquer rede de computadores e principalmente na Internet.
O slow start, tal como os algoritmos que irão posteriormente ser explicados, teve origem em algoritmos
implementados anteriormente pela DEC (Digital Equipment Corportaion) [86], nomeadamente o CUTE
(Congestion Control Using Timeouts at the End-to-End) [11]. Especificados em 1986, dois anos antes do
TCP Tahoe, estes algoritmos deram origem ao termo “Linear Decrease and Sudden Decrease”, que viria
a ser adaptado pelas versões TCP como AIMD (Additive Increase and Multiplicate Decrease). Os
algoritmos AIMD são caracterizados pela aplicação de multiplicações, adições e divisões na janela de
congestão conforme a correspondente situação da rede.
O Slow Start é especialmente importante na medida em que a maioria das ligações TCP não dura muito
tempo, assim sendo, muitas das vezes apenas este algoritmo é invocado.
27
O inglês “slow” significa lento.
64](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-86-320.jpg)

![TCP em Redes de Elevado Débito
Para esta relação é necessário o uso de duas simples variáveis: cwnd29
, responsável pelo tamanho actual
da janela de congestão; ssthresh, o threshold30
do Slow Start onde poderá ocorrer congestão.
O relacionamento entre Slow Start e Congestion Avoidance baseia-se essencialmente nos seguintes
pontos:
• Quando a congestão ocorre, verificada pelas possíveis indicações, metade do valor da janela de
congestão ficará guardado na variável ssthresh, ficando esse o limite da zona de congestão;
• Se existir um timeout, adicionalmente a variável cwnd baixa para o valor MSS inicial;
• Quando é notificada a recepção de novos segmentos, a forma como a janela é aumentada depende
da situação que o emissor pensa estar a rede. Se ssthreshcwnd ≤ não se passou o limite de
congestão, sendo usado o normal crescimento Slow Start; se pelo contrário ,
então passou-se o limite de congestão, sendo usado o incremento Congestion Avoidance.
ssthreshcwnd ≥
A Figura 3.38 demonstra como os algoritmos e respectivas variáveis se relacionam. O eixo dos xx
representa os RTT, o eixo dos yy representa o valor da cwnd em segmentos. Pressupõe-se nesta
representação que uma anterior situação de congestão já sucedeu aquando do segmento 32, sendo
verificado um timeout; por essa mesma razão o ssthresh ficou armazenado com o valor 16; de seguida o
Slow Start começa novamente a partir do 1º segmento até ao 16º segmento (valor do ssthresh); após
ultrapassar o valor do ssthresh entrou-se na zona de possível congestão, diminuindo assim a velocidade
de envio.
Figura 3.38 – Representação gráfica da relação Slow Start/Congestion Avoidance (Fonte: [1]).
29
Por vezes utilizada para referenciar a própria janela de congestão, neste caso referenciada como uma variável.
30
O inglês “threshold” significa ponto inicial, neste caso referenciado como ponto inicial de congestão.
66](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-88-320.jpg)

![TCP em Redes de Elevado Débito
3.5.2. TCP Reno
Em 1990 Van Jacobson (ver Cap. 3.2.1.2), continuando a precisa análise de eficiência das redes de
computadores efectua modificações ao algoritmo Congestion Avoidance [14]. O algoritmo principal desta
nova versão é o Fast Recovery.
3.5.2.1. Fast Recovery
Fast Recovery permite uma recuperação mais rápida, enviando menos. As modificações efectuadas
devem-se em grande parte a uma situação verificada: apesar de um ack duplicado poder indicar
congestão, significa também que um segmento chegou bem ao receptor e saiu da rede. Foram
especificadas as seguintes situações:
• Por cada vez que cada ack duplicado chegar ao emissor, em vez de usar a normal forma de
incrementação Congestion Avoidance, incrementa-se a cwnd no valor de um segmento;
• Quando o segmento é retransmitido devido ao algoritmo Fast retransmit, a cwnd assume o valor
do ssthresh mais três segmentos. Desta forma é feito directamente Congestion Avoidance em vez
de iniciar Slow Start, o valor dos três segmentos é devido ao facto de 3 acks duplicados
significarem que 3 segmentos saíram da rede;
• Transmite um segmento se for permitido pela cwnd e pela janela do receptor;
• Quando tudo voltar ao normal e novos segmentos notificados ao emissor, a cwnd toma o valor do
ssthresh, de forma a ser feita a normal incrementação Congestion Avoidance em vez do Slow
Start.
A Figura 3.40 exemplifica uma situação com todos os algoritmos de congestão em funcionamento (Slow
Start, Congestion Avoidance, Fast Retransmit e Fast Recovery). O eixo dos xx representa o tempo, o eixo
dos yy a janela de congestão; o valor máximo do yy é o valor do ssthresh, que será por sua vez o tamanho
máximo da janela do receptor (64KB). O algoritmo inicial é o Slow Start que é automaticamente
invocado; passado algum tempo um timeout ocorre e o ssthresh toma metade do valor da cwnd; o Slow
Start inicia outra vez, mas agora, quando atinge o valor do ssthresh o limite de congestão é atingido e o
Congestion Avoidance invocado com a sua incrementação 1/cwnd; o próximo acontecimento é uma perda
detectada pelo 3º ack duplicado, sendo então invocado o Fast Retransmit que rapidamente transmite o
segmento, sem que exista tempo morto por parte do emissor; por fim é invocado o Fast Recovery ficando
a cwnd com o valor de ssthresh mais a adição de 3 segmentos, entrando directamente em Congestion
Avoidance. Continuando, ainda são invocados mais duas vezes o Fast Retransmit, Fast Recovery e
Congestion Avoidance sucessivamente.
68](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-90-320.jpg)
![3. Enquadramento ao Protocolo
Figura 3.40 – Representação dos algoritmos de congestão em funcionamento (Fonte: [6]).
Van Jacobson acabava aqui o seu ciclo de algoritmos, porém um melhoramento final aos seus algoritmos
ia ainda ser efectuado. Todos os algoritmos de congestão anteriormente referenciados ficaram
referenciados em RFC [45].
3.5.3. TCP newReno
Janey Hoe (ver Cap. 3.2.1.2 ) iria desenvolver o último algoritmo deste ciclo. Especificado numa primeira
vez em 1996 [19] e finalmente em RFC em 1999 [46] e 2004 [52], este foi talvez o algoritmo que mais
demorou a ser adoptado. Essa tardia adopção deveu-se provavelmente ao facto de as melhorias não se
verificarem tão grandes, quanto as verificadas aquando da criação dos anteriores algoritmos.
O newReno foca, essencialmente, a fraca capacidade do Reno em recuperar de uma múltipla perda de
segmentos. Verificou-se que para uma única perda de segmento a recuperação é bastante boa, mas que
passando esse limite a perfomance torna-se bastante reduzida.
O problema acontece aquando da activação do algoritmo Fast Retransmit. Como foi referenciado
anteriormente, o algoritmo Fast Retransmit é activado sempre que o emissor recebe um terceiro ack
duplicado, sendo que o segmento é rapidamente retransmitido. A situação problemática surge quando
para a mesma janela mais de um segmento se perdeu, sendo necessário mais do que uma transmissão.
Imaginando que o 3ºack duplicado é o 1, ao retransmitir é recebido o ack do 2; a situação não é normal,
pois até receber o 3ºack duplicado foram pelo menos enviados 3 segmentos e no funcionamento normal
existe um ack de n segmentos. Assim sendo, existe uma alta probabilidade de o 3 estar perdido que não
foi considerada nos algoritmos anteriores.
69](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-91-320.jpg)

![3. Enquadramento ao Protocolo
o Se o 3ºack duplicado for menor que a variável recover então estamos perante um Partial
Ack, i.e., não foram recebidos todos os segmentos;
Neste caso não são efectuado nem Fast Retransmit nem Fast Recovery. O valor ssthresh não vai
ser afectado nem a cwnd, porém será enviado um segmento por RTT. Esse envio acontece pois
cada vez que um ack duplicado chegue ao emissor a janela do receptor irá permitir mais um
envio, como a janela de congestão como não foi diminuída irá permiti-lo, até todos os segmentos
da janela serem retransmitidos.
o Se o 3ºack duplicado for maior que a variável recover então todos os segmentos foram
correctamente recebidos.
Funcionamento normal31
por parte do Fast Retransmit e Fast Recovery.
As semelhanças nas preocupações entre TCP newReno e Sack (ver Cap. 3.3.2.5) são bem notórias: ambos
se preocupam com a optimização na retransmissão de segmentos. Apesar dessa situação o TCP newReno
com Sack supera em perfomance o normal Reno com Sack. Existe porém um cenário onde o Reno tem
melhor perfomance: sem perdas, mas com suficiente reordenamento para o emissor receber 3ºack e ser
“enganado” por não se tratar de uma perda. Com Reno apenas um segmento seria transmitido, com
newReno o “engano” dá origem a uma sucessão de retransmissões.
O newReno após algum tempo foi totalmente adoptado em todas as implementações. Muitas
implementações actuais não diferenciam Reno e newReno, considerando o primeiro como o segundo, e
nunca o segundo como o primeiro.
A recuperação de perdas é ainda actualmente um problema muito debatido e nada simples de resolver, foi
especificada uma RFC específica para esse procedimento [48].
A Figura 3.42 é um resumo de todas as versões TCP até agora explicadas. Todos são implementados em
conjunto, pelo que é normal existir dificuldade em definir o âmbito de cada um. O Fast Retransmit perde
todo o seu objectivo sem Fast Recovery, o Congestion Avoidance perde o objectivo se for retirado o Slow
Start.
31
Normal neste caso significa o funcionamento da versão anterior (TCP Reno).
71](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-93-320.jpg)
![TCP em Redes de Elevado Débito
Figura 3.42 – Resumo de todas as operações e algoritmos de congestão, proporcionados pelas versões TCP Tahoe, Reno e
newReno.
Ao longo do desenvolvimento notou-se também, cada vez mais, uma análise mais pormenorizada da
perfomance. A versão newReno foi detectada por variados testes e uma análise pormenorizada detectou
um padrão de menor perfomance. Esta seria a forma com que actualmente se desenvolvem as novas
versões: análise de perfomance, análise de padrões de menor perfomance, verificação da existência de
problemas, implementação da solução.
3.5.4. TCP Vegas
“O principal resultado que se verifica neste paper é o facto do Vegas conseguir atingir entre 40 a 70%
melhor throughput que o Reno”. [15]
O TCP Vegas foi especificado por Lawrence Brakmo (ver Cap. 3.2.1.2) em 1994 [15]. O seu objectivo foi
providenciar novos horizontes a todo controlo de congestão, propondo modificações para que o TCP
pudesse explorar esses mesmos horizontes.
Essas modificações dividem-se em sete melhoramentos, com o principal objectivo de aumentar o
throughput da rede e diminuir as perdas. Os melhoramentos são:
1. Melhoria significativa nos mecanismos de estimação RTT;
2. Melhor retransmissão de segmentos;
3. Melhor retransmissão, considerando múltiplas perdas;
4. Ajustamento à forma como é estabelecido o redimensionamento da janela de congestão no
Reno;
5. Melhor espaçamento entre os segmentos;
72](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-94-320.jpg)

![TCP em Redes de Elevado Débito
Melhoria para melhor espaçamento entre os segmentos
Verificou-se que no Reno grande parte das perdas é devido a bursts32
de segmentos. A razão dos bursts é
principalmente falhas nos mecanismos responsáveis pelo self-clocking. As duas razões para isso acontecer
são:
• Acks largamente cumulativos;
Geralmente esta situação acontece quando o receptor acumula bastantes notificações de segmentos para
poder fazer piggybacking (ver Cap. 3.3.2.1).
• Ack Compression.
Este mecanismo foi descrito pela primeira vez em 1992 [12]. A razão prende-se com o facto de os buffers
acumularem diversos segmentos nas suas filas de espera33
e quando geralmente a aplicação os retira,
retira-os bruscamente dando origem a acks muito poucos espaçados.
O TCP Reno não controla a forma como o espaçamento entre segmentos é efectuado. A janela de
congestão apenas limita a quantidade de segmentos a enviar, não implementando qualquer mecanismo de
controlo de espaçamento. Desta forma, a probabilidade das filas encherem é bastante grande.
O valor ideal de espaçamento é dado pela seguinte fórmula:
)(
cwnd
MaxSegment
RTTSeqSpacing =
Esta fórmula é utilizada pelo TCP Vegas no mecanismo Spike Supression. Este mecanismo consiste em
permitir apenas um envio de 2 vezes o MaxSegment por cada intervalo SegSpacing. O total de bytes que
se poderá transmitir continua limitado pela janela de congestão, porém, desta forma é apenas permitido
transmitir 2 vezes o número ideal de bytes por SegSpacing.
Outra forma de tratar a congestão
Como já foi visto anteriormente, o TCP Reno utiliza a perda de segmentos como sinal de congestão. Não
existe qualquer mecanismo no TCP Reno que permite detectar estados antecipados de congestão, desta
forma o TCP não previne mas apenas reage. O TCP Reno é assim considerado um protocolo reactivo e
não proactivo.
O TCP Vegas traz como principal novidade a sua proactividade (ver Cap. 2.1.5.2) já referida
anteriormente para tratar a congestão. Assim sendo, as abordagens para tratar a congestão poderão agora
ser divididas por:
32
O inglês “burst” significa rajada, neste caso referenciado a segmentos em rajada.
33
Filas de espera neste caso têm um significado genérico, não estando presente qualquer mecanismo específico.
74](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-96-320.jpg)

![TCP em Redes de Elevado Débito
As decisões referentes ao redimensionamento da janela de congestão são:
• Se α<Diff então a janela de congestão irá aumentar linearmente no valor de 1/cwnd;
• Se β>Diff então a janela de congestão irá diminuir no valor de 1/cwnd;
• Se βα << Diff então a janela será mantida.
A Figura 3.43 representa o funcionamento do TCP Vegas, considerando a relação entre a velocidade de
transmissão e a diferença de throughput verificada. Quanto maior o throughput actual, maior será a
velocidade de envio (aumento da janela); quanto menor o throughput actual, menor será a velocidade de
envio (diminuição da janela); a fase ideal é um intermédio das duas anteriores, não sendo alterada a
velocidade de transmissão.
Figura 3.43 – Relação throughput/velocidade transmissão [Fonte: [15]].
O algoritmo anterior explicado não é directamente aplicado na fase de Slow Start, tendo esse algoritmo
sido alvo de uma modificação.
Modificação no Slow Start
O Slow Start é um algoritmo bastante “caro36
” a nível de perdas, se o buffer do emissor não for limitado.
Quando o Slow Start começa a sobrecarregar a rede já podem existir perdas na ordem de metade da janela
de congestão. O TCP Vegas podia começar a usar de início o seu algoritmo de prevenção, mas a falta de
aproveitamento de largura de banda seria enorme. A solução encontrada foi um intermédio entre a
abordagem Reno e a abordagem Vegas. O Reno aumenta exponencialmente a janela de congestão por
cada RTT, o Vegas aumenta exponencialmente uma vez por RTT e no próximo previne com o seu
algoritmo. Também neste caso é definido um thresholdγ com objectivos idênticos aos outros dois
thresholds, mas para definir especificamente a “agressividade” do algoritmo Slow Start.
36
Caro em relação a que para ter elevado débito implica outras desvantagens.
76](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-98-320.jpg)
![3. Enquadramento ao Protocolo
A Figura 3.44 representa um gráfico característico da versão TCP Vegas. Ao contrário da versão Reno
não se verificam grandes oscilações; o gráfico é caracterizado por um uma janela de congestão que lhe
garante uma transmissão bastante constante ao longo do tempo; os thresholds β e α definem todo o
controlo de transmissão; verifica-se também que só existe Slow Start e Congestion Avoidance ao longo do
tempo.
Figura 3.44 – Gráfico característico do TCP Vegas.
Apesar deste ser um gráfico aproximado do que costumam ser as transmissões com TCP Vegas, todos os
algoritmos do Reno estão presentes. A principal vantagem do Vegas é que como tem uma taxa de 2 a 5
vezes menos perdas que o Reno, raramente os invoca.
A seguir à sua inicial especificação foram efectuados alguns melhoramentos [16][17]. Os principais
foram uma redução para ¼ da janela (no Reno era ½) aquando da verificação de congestão, e um valor
inicial da janela de 2 MSS (no Reno era 1 MSS).
Após toda a fase de especificação variados testes foram feitos. Provavelmente TCP Reno e TCP Vegas
foram as versões a que mais testes tiveram sujeitas, principalmente testes de comparação entre os dois. A
inicial especificação definia o TCP Vegas como garantia de mais 40% a 70% throughput que o Reno, mas
essa garantia não é assim tão simples e directa. Praticamente todos os estudos deram melhor perfomance
para o Vegas em situações com diferentes RTT, baixos atrasos e poucas retransmissões [16][17][18].
Apesar desta situação, ligações com altos atrasos têm melhor perfomance usando Reno [18]. Existe
também um problema a que o TCP Vegas está inerente: o facto de poderem existir mudanças de rotas ao
longo do percurso, alterando bruscamente o RTT; estando o TCP Vegas tão depende do RTT para as suas
decisões, o resultado são baixas perfomances. Outros problemas prendem-se principalmente com
fairness37
; a principal razão prende-se outra vez com o RTT: o primeiro fluxo que usar a rede terá sempre
um menor RTT mínimo do que o segundo fluxo, dessa forma terá sempre a sua janela maior, transferindo
posteriormente mais dados.
37
O inglês “fairness” significa justiça, neste caso justiça na atribuição de recursos.
77](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-99-320.jpg)
![TCP em Redes de Elevado Débito
Os testes verificam principalmente uma nova situação: a existência de duas versões, cada uma
funcionando melhor com certas condições de rede. Era dado aqui o primeiro passo para uma série de
versões cada vez mais específicas.
3.5.5. Outros meios, outras versões
Foi evidenciado no Cap. 3.1.1 que o desenvolvimento a partir de determinados pressupostos. Apesar desta
situação, as versões anteriormente referenciadas são eficientes para a maioria dos meios, não implicando
claro que sejam altamente eficientes em cada meio específico. As novas versões que surgiram abordam
esta situação, tentando atingir níveis de alta eficiência em meios específicos. A maior quantidade de
versões existentes tem como meio específico o alto débito (ver Cap. 3.6). Apesar disso, existem outros
meios igualmente importantes, com abordagens diferentes aos normais algoritmos de congestão.
3.5.5.1. Comunicações Satélite
As comunicações de Satélite são caracterizadas principalmente por: altos atrasos, erros nas transmissões,
perda de conectividade e altas larguras de banda assimétricas. Apesar de todos estes parâmetros afectarem
directamente a aquisição de eficiência por parte do TCP, o mais crítico são os altos atrasos, na ordem dos
480ms a 560ms.
A preocupação evidenciada pelas comunidades de investigação na obtenção da máxima eficiência deste
tipo de meios, deu origem a uma RFC [44] que fornece recomendações acerca dos algoritmos de
congestão a usar, aumento do tamanho da janela de recepção e outros melhoramentos.
Mais tarde iria surgir uma nova versão TCP, especificamente, direccionada para este tipo de meios: o
TCP Hybla.
TCP Hybla
O TCP Hybla, especificado em 2004 [20] tem como principal objectivo quebrar a relação entre RTT e
janela de congestão. Devido aos altos atrasos inerentes às comunicações satélites, os valores do RTT irão
ser de índice bastante superior a qualquer outro meio.
A forma como os normais algoritmos do Reno e Vegas decidem sobre a transmissão, ou não, de mais
segmentos por parte do emissor é feita a cada RTT. Desta forma, é fácil perceber que a forma instantânea
com que os antigos protocolos transmitiam para a rede, não se revela assim tão instantânea considerando
altos RTT.
78](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-100-320.jpg)
![3. Enquadramento ao Protocolo
O Hybla tenta devolver a instantaneidade em falta no que diz respeito à transmissão de segmentos. A
solução encontrada foi tornar as regras de aumento de congestão independentes do RTT, através de uma
mudança de escala temporal no envio de segmentos.
3.5.5.2. Comunicações Wireless
As redes wireless, apesar da tecnologia não ser recente, tornaram-se bastante comuns actualmente.
Quando esta tecnologia surgiu, exigiu novos requerimentos que resultaram em diversos protocolos e
mecanismos de rede específicos. O TCP na altura do surgimento desta tecnologia não foi sujeito a
qualquer modificação ou melhoramento. Essa situação, ocorreu muito por culpa da eficiência e
compatibilidade proporcionada pelos normais mecanismos e algoritmos de congestão deste protocolo. Só
mais tarde, após o surgimento das diversas versões TCP adaptadas a meios específicos, o TCP iria ser
melhorado para este tipo de meio tão peculiar.
Os meios wireless são caracterizados por: baixas larguras de banda e muitos erros de transmissão. A
característica mais crítica são os erros de transmissão que por vezes podem ultrapassar a barreira do 1%
(considerando bits/s). Estes erros geralmente quando ocorrem, ocorrem em burst.
Foi referido, anteriormente nos algoritmos de congestão (ver Cap. 3.5), que existem dois tipos de perdas e
que um desses tipos era desprezado (os erros do meio de transmissão). Neste tipo de meios essa situação
não pode acontecer, sob pena de ser perdida toda a eficiência na ocupação de largura de banda disponível.
Distinguir entre perdas devido a congestão e perdas devido ao meio de transmissão, assim como
providenciar formas de medição para a sua diferenciação é um problema fundamental para o TCP em
meios wireless e a sua solução não se revela fácil de adquirir.
Existem duas versões principais, especialmente, concebidas para este tipo de meio: o TCP Westwood e o
TCP Veno.
TCP Westwood
O TCP Westwood [29] foi a primeira versão a surgir. É um protocolo bastante estável utilizado por
omissão em diversas distribuições Linux. Apesar de ser concebido especificamente para redes wireless,
adapta-se bastante bem a todos os outros meios. Em todos os meios revela um aproveitamento de largura
de banda bastante superior ao TCP Reno e Vegas. As redes de alto débito não são excepção, apesar de os
meios sem fios não serem meios caracterizados por altas larguras de banda.
O conceito mais inovador do TCP Westwood é uma contínua estimação do débito da rede, monitorizando
toda a chegada dos respectivos acks. Todo este débito estimado é depois usado para alterações na forma
como é alterada a janela de congestão e o ssthresh. O objectivo será então uma maior dinâmica às perdas,
79](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-101-320.jpg)
![TCP em Redes de Elevado Débito
não exagerando nas descidas da janela de congestão. O algoritmo dinâmico de recuperação é referenciado
como “Faster Recovery38
”, o algoritmo de medição é referenciado como BWE (Bandwidth Estimate).
Estes dois algoritmos são as principais novidades desta versão, apesar disso, o RTT também é utilizado
para definir a taxa de transmissão. Assim, o RTT mínimo servirá para verificar o estado da rede, enquanto
o BWE servirá para saber o débito fluxo-a-fluxo, eliminando situações de monopolização da largura de
banda conhecidas dos algoritmos DCA (Delay Congestion Avoidance, ver Cap. 3.5.6).
Imaginando uma situação prática com perda por erro de transmissão, o TCP Westwood não o detecta;
mas, ao efectuar a recuperação, verificará o BWE que provavelmente estará com um bom débito para que
não ocorra congestão; então, vai verificar o RTT vendo que ele era o mínimo da transmissão (indicação
que a rede estava de “boa saúde” no que diz respeito a congestão); finalmente, perante estas situações a
janela de congestão não vai descer e o débito será mantido, sendo a perda praticamente ignorada.
Existe também um melhoramento a este algoritmo que permite uma melhor perfomance mesmo com ack
compression [12]. Essa versão é referenciada como Westwood+ [29].
TCP Veno
O TCP Veno [21] surgiu um pouco mais tarde do que o TCP Westwood trazendo uma menor componente
de inovação. O próprio nome “Veno” é uma analogia à junção dos mecanismos do Reno e Vegas. O TCP
Veno efectua a decisão que não é directamente tomada pelo TCP Westwood. Para efectuar essa decisão
utiliza todo o algoritmo de estimação RTT do TCP Vegas. O conceito é simples: se o RTT estimado for
muito elevado em relação ao mínimo, então poderá estar a ocorrer congestão e, posteriormente, se ocorrer
perda foi devido a congestão, invocando assim os normais algoritmos do Reno; caso contrário, a perda é
devido a erros de transmissão e a janela deve descer apenas 1/5, utilizando também os normais algoritmos
do Reno.
Para além destas versões, existem mais de 200. Apesar desse facto, 90% das versões são ainda
experimentais, estando em constante desenvolvimento e em constantes testes comparativos. As versões
anteriores referenciadas encontram-se já com um desenvolvimento bastante estável.
38
O nome tem uma razão comparativa com o anterior algoritmo do Reno “Fast Recovery”, significando maior rapidez (Faster).
80](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-102-320.jpg)
![3. Enquadramento ao Protocolo
3.5.5.3. TCP de baixa prioridade
Se até aqui se tem falado de eficiência e máxima ocupação da largura de banda disponível, o que dizer de
uma versão que apenas aproveita os “restos39
” da largura de banda de uma ligação? A resposta é simples:
se existirem ficheiros em que a o tempo da sua transferência não seja importante, não se revela necessário
requisitar largura de banda de outros fluxos.
Para redes com débitos bastante reduzidos este tipo de versões providencia o algoritmo para que os outros
fluxos consigam ter elevados tempos de resposta em aplicações interactivas, sendo simultaneamente
transferidos ficheiros, para os quais o tempo de resposta não é importante.
A versão mais conhecida que aborda este conceito é o TCP Low Priority40
[22], sendo o seu objectivo
usar a largura de banda não utilizada pelos outros fluxos de uma forma não intrusiva, i.e., transparente aos
outros fluxos.
3.5.6. DCA VS LCA
Durante o desenvolvimento de novas versões, mais se reparou nas vantagens e desvantagens entre as
implementações usando a base do TCP Reno e a base do TCP Vegas. Estas abordagens são referenciadas
como Loss-Based Congestion Avoidance (LCA), caso do TCP Reno e Delay Congestion Avoidance
(DCA), caso do TCP Vegas.
O primeiro passo na especificação de uma nova versão é ter a correcta noção do que induz cada uma
destas abordagens. As duas adequam-se mais a certos meios, as duas incorrem em alguma falta de
eficiência em certas situações, e as duas são absolutamente necessárias para a existência de versões
adaptadas, específicas a meios de transmissão.
Muitas das vantagens foram sendo explicadas anteriormente, será dado agora maior ênfase às diversas
desvantagens. As desvantagens da abordagem LCA são:
• Throughtput será sempre obrigatoriamente menor do que a largura de banda disponibilizada;
Sendo uma abordagem que testa a rede até ao limite, fácil será perceber que a rede acabaria por ceder,
descartando segmentos.
• Muitas perdas;
Testar a rede até ao limite traz também esta desvantagem. O primeiro teste será onde ocorrerá maiores
perdas (Slow Start). O objectivo é estudar a rede para perder menos;
39
Referindo a disponibilidade de largura de banda que não é ocupada.
40
Também referenciado como TCP-LP
81](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-103-320.jpg)
![TCP em Redes de Elevado Débito
• Altas variações nos atrasos;
Geralmente neste caso, ou os atrasos são pequenos, ou os atrasos são muito grande estando já a ocorrer
congestão.
• Alto requerimento de buffers por parte dos routers;
Sendo esta uma forma um pouco agressiva de tratar a rede (testando até existir perdas), os routers têm de
estar melhor preparados.
• Risco de diminuição da janela de congestão de forma exagerada;
Tendo apenas um nível de congestão (ou existe ou não existe), é complicado tomar uma decisão eficiente
no que diz respeito ao decréscimo da janela.
• Mais problemático quando existe perdas devido ao meio de transmissão;
Devido ao facto de existirem mais oscilações, quando existe perdas que não são devido a congestão é
perdida mais eficiência.
A comunidade de investigação geralmente atribui a abordagem DCA como menos arriscada, traduzindo
esse facto menos desvantagens. Apesar dessa situação existem também algumas:
• Pequenas variações no RTT não são valorizadas;
Em casos de bottleneck41
muito pequenos existirá variações RTT que o estimador RTT não irá notar
devido a amostragem do tempo, desvalorizando assim a possível ocorrência de congestão.
• Problema de fluxos serem monopolizados por outros;
Se existir um fluxo na ligação que esteja a manipular todo o bottleneck, os RTT indicarão congestão
baixando assim a taxa de transmissão, porém esses RTT são controlados pelo outro fluxo.
• Falta de justiça na atribuição de recursos aquando uma situação de congestão.
Numa situação de congestão, os algoritmos DCA não descem como os LCA. Desta forma toda a justiça
na atribuição de recursos (fairness) é perdida.
• Problemas entre a relação RTT e a congestão;
Existem variados estudos [23] que estabelecem uma fraca relação entre o aumento da janela de congestão
e o RTT.
41
O ingês “bottleneck” significa pescoço de garrafa, numa analogia a estreitamento do caminho, ou neste caso, a ligação mais
lenta.
82](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-104-320.jpg)

![TCP em Redes de Elevado Débito
Figura 3.45 – Comportamento do TCP Reno numa LFN de 10Gbit/s (Fonte: [9]).
A forma de cálculo deste tempo de recuperação por parte do algoritmo Congestion Avoidance (na versão
Reno) é fornecida pela seguinte fórmula, permitindo calcular o tempo de resposta (responsivness):
MSS
RTTC
2
)( 2
=∂
respostadetempo=∂
rededaCapacidadeC =
Alguns valores fornecidos por esta fórmula estão expressos na Tabela 3.3. Verifica-se uma subida
acentuada do tempo de resposta em relação ao aumento da capacidade da rede, ou em relação ao seu
atraso (RTT). É de realçar também que ao aumentar o tamanho do segmento, este tempo diminui bastante
(última ligação WAN Futura), para isso serão necessários buffers enormes por parte dos routers.
Ligação Capacidade RTT (ms) MSS (Byte) Valores de tempo
de resposta
LAN típica em 1988 10 Mb/s [ 2 ; 20 ] 1460 [ 1.7 ms ; 171 ms ]
Típica LAN actualmente 1 Gb/s 2
(pior caso)
1460 96 ms
Futura LAN 10 Gb/s 2
(pior caso)
1460 1.7s
WAN 1 Gb/s 120 1460 10 min
WAN 1 Gb/s 180 1460 23 min
84](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-106-320.jpg)
![3. Enquadramento ao Protocolo
WAN 1 Gb/s 300 1460 1 h 04 min
WAN 2.5 Gb/s 180 1460 58 min
WAN Futura 10 Gb/s 120 1460 1 h 32 min
WAN Futura 10 Gb/s 120 8960
(Jumbo Frame)
15 min
Tabela 3.3 – Tabela com valores de tempo de resposta conforme tipo de ligação (Fonte: [62]).
O objectivo das novas versões para alto débito é principalmente baixar este tempo de resposta, com o
intuito de aumentar o débito médio da rede.
As versões abaixo referenciadas são aquelas em que o desenvolvimento se encontra mais estável,
assumindo um elevado grau de importância devido aos novos conceitos adicionados.
3.6.2. HighSpeed TCP
“Uma forma de olhar a proposta HighSpeed TCP é que ela opera da mesma forma que um turbo de um
motor; quanto mais rápido o motor está, mais rápido o turbo opera até que o motor funcione na sua
normal velocidade”. [9]
O HighSpeed TCP é de todas as versões de alto débito aqui referenciadas a versão que se encontra mais
avançada em termos de desenvolvimento e adopção. É a única versão TCP para alto débito especificada
em RFC [51], tendo sido desenvolvida por Sally Floyd (ver Cap. 3.2.1.3).
O HighSpeed TCP surgiu com base num conceito de uma versão TCP para alto débito bastante simples: o
MulTCP [24].
MulTCP
Tal como foi referido anteriormente, o principal problema está no Congestion Avoidance (ver), devendo
as mudanças essenciais serem efectuadas nesse algoritmo (responsável pela reacção às perdas). O
MulTCP quando invoca o Congestion Avoidance incrementa a sua janela de congestão em N segmentos
por RTT, em vez do normal incremento 1/cwnd; após uma perda reduz a sua janela de congestão em
cwnd/(2N), em vez do normal cwnd/2. É também utilizada uma versão alterada do SlowStart, onde a
janela de congestão aumenta 3 segmentos em vez dos normais 2.
85](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-107-320.jpg)

![3. Enquadramento ao Protocolo
Figura 3.46 – Representação do padrão gráfico do normal TCP (TCP Reno), MulTCP(N=10) e HighSpeed TCP, numa LFN de
10Gbit/s (Fonte: [9]).
O aumento de perfomance é imenso, sendo traduzidos os cerca de 8 segundos de recuperação, em pelo
menos, velocidades médias de ligação de 9Gbit/s.
3.6.3. Scalable TCP
O Scalable TCP [Scalable] foi desenvolvido ainda antes do HighSpeed TCP, tendo como principal
objectivo quebrar o relacionamento entre as modificações na janela de congestão e o RTT. Os
desenvolvimentos efectuados no TCP Scalable são a substituição da normal função aditiva do Congestion
Avoidance, pela adição de um valor constante a , e a redução da janela por uma fracção de b. A
característica principal é o uso de um aumento multiplicativo à janela de congestão em vez do normal
aumento linear, aumentando assim a frequência de oscilação. Esta versão é bastante oscilante,
contrastando por exemplo com o TCP Vegas (o menos oscilante).
Na Figura 3.47 estão representadas as modificações efectuadas à janela de congestão, aquando da
situação de congestão; a fórmula para cálculo do intervalo de oscilação está também presente, bem como
todo o padrão de oscilação.
87](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-109-320.jpg)
![TCP em Redes de Elevado Débito
Figura 3.47 – Representação das modificações na janela de congestão efectuadas pelo TCP Scalable (Fonte: [25]).
O Scalable TCP possui semelhanças com o MulTCP na medida em que é escalável43
, apesar disso, ao
contrário do MulTCP, os valores aconselhados e quase sempre usados para qualquer largura de banda são
. A125.0,01.0 == ba Figura 3.48 demonstra o comportamento destas duas variações TCP (Scalable
TCP e MulTCP) e o normal TCP, na mesma ligação de 10Gbit/s da Figura. Verifica-se novamente o
carácter oscilante do Scalable TCP.
Figura 3.48 - Representação do padrão gráfico do normal TCP (TCP Reno), MulTCP(N=10) e Scalable TCP (a=0.01, b=0.125)
numa LFN 10Gbit/s (Fonte: [9]).
3.6.4. BIC e CUBIC
O BIC (Binary Increase Congestion Avoidance) [26] e o CUBIC [27] são duas versões que abordam
todas estas formas de incrementos na janela de congestão de uma forma totalmente inovadora. O conceito
43
O inglês “Scalable” significa escalável.
88](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-110-320.jpg)

![TCP em Redes de Elevado Débito
bastante mais “arredondado”, sendo sempre usado o algoritmo Binary Search Increase, mas sempre
recorrendo a uma função polinomial atenuando todas as alterações bruscas.
Figura 3.50 – Funções de crescimento BIC e CUBIC (Fonte: [27]).
É de referir que o BIC se encontra como a versão TCP por omissão na maioria das distribuições Linux.
3.6.5. H-TCP
O H-TCP (Hamilton TCP) [55] não traz propriamente qualquer inovação, funcionando como uma junção
evolucionária do HighSpeed TCP, TCP Scalable e TCP Westwood. Do Highspeed TCP foi adoptado a sua
aumento adaptativo na janela de congestão através das perdas; do TCP Westwood foi adoptado sua
moderação, aquando do decréscimo da janela de congestão; em relação ao Scalable TCP foi retirada toda
a sua oscilação, que o torna independente do RTT.
Esta versão do protocolo veio adoptar todos os algoritmos mais interessantes das versões anteriores. Essa
adopção permitiu diversos melhoramentos. Por exemplo: um dos problemas do TCP Westwood é que
apesar de ter um grande controlo nas descidas das suas janelas de congestão, não tem qualquer algoritmo
específico para incrementação; com a adição do algoritmo do TCP HighSpeed esta situação é eliminada.
O Scalable TCP não tem qualquer tipo de controlo adaptativo da sua janela; o algoritmo TCP Westwood
permite agora esse tipo de controlo.
3.6.6. FAST TCP
O FAST TCP é o único descendente do TCP Vegas (ver Cap. 3.5.4), considerando todas as versões de
alto débito analisadas. Quando especificado [30], foi especialmente tido em conta a vantagem do TCP
Vegas em relação ao TCP Reno nos meios de alto débito. A vantagem do TCP Vegas utilizando pouca
largura de banda revela-se mínima, porém, quando se trata de alto débito verifica-se decisiva. O objectivo
foi criar uma versão melhorada do TCP Vegas, especifica ao esse meio de transmissão de alto débito.
90](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-112-320.jpg)
![3. Enquadramento ao Protocolo
Foi referido anteriormente (ver Capítulo) que a incrementação e diminuição da janela de congestão do
TCP Vegas é sempre correspondente a 1/cwnd. Esta forma de decrescimento e crescimento leva a que o
TCP Vegas demore bastante a atingir a sua fase de equilíbrio. A principal modificação do FAST TCP diz
respeito a uma alteração nesta forma de incremento/decremento.
No FAST TCP a forma como são efectuadas modificações à janela por RTT depende de dois factores:
• A variação do RTT;
• O valor da janela de congestão corrente.
Com base nestes dois parâmetros, a fórmula de crescimento/decrescimento será igual a:
α+×= )/( RTTRTTbaseWW
O valor baseRTT continua a representar o RTT mínimo da ligação, representado o RTT o seu valor
corrente. Oα foi já referenciado anteriormente no TCP Vegas (ver).
Através deste tipo de incremento a janela será ajustada rapidamente até ao seu estado de equilíbrio; à
medida que a janela cresce, maior será o incremento; aumentando o RTT, o crescimento será bastante
atenuado.
O FAST TCP considera assim quatro componentes de controlo de congestão:
• Controlo de Dados;
Escolhe que tipo de segmentos transmitir (apenas utilizado para a estimação);
• Controlo de Janela;
Escolhe a quantidade de dados a transmitir;
• Controlo de Burst.
Escolhe o tempo que os irá transmitir, ligado aos tempos RTT que verificam o estado dos buffers.
A Figura 3.51 representa toda a arquitectura FAST TCP. Os campos a vermelho representam os campos
directamente relacionados; o controlo de janela afecta a estimação, a estimação afecta o controlo de
janela; o mesmo acontece com o controlo de burst; em relação ao controlo de dados, irá afectar a
estimação, mas a estimação não tem qualquer controlo sobre ele.
Figura 3.51 – Arquitectura FAST TCP (adaptado de [30] ).
91](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-113-320.jpg)
![TCP em Redes de Elevado Débito
3.6.7. Compound TCP
O Compound TCP [31] é especialmente importante por ser a versão usada pelo Windows Vista®, tendo
sido desenvolvida pela Microsoft®. As principais preocupações do Compound TCP são três:
• Eficiência em redes de alto débito;
• RTT fairness;
Tem obrigatoriamente de existir uma justiça na atribuição de recursos entre protocolos, especialmente
quando diferentes fluxos têm diferentes RTT.
• TCP fairness;
Não deve ser reduzida a perfomance de outros fluxos regulares a competir na mesma ligação, i.e., os
protocolos para alto débito devem usar a largura de banda disponível e não roubá-la de outros fluxos.
A ênfase dada nesta versão à forma como os fluxos TCP interagem é muito maior do que em todas as
versões anteriores.
Uma forma de ver esta versão é considerá-la uma junção entre a versão TCP Reno e TCP Vegas, este tipo
de versão já tinha sido verificado anteriormente com o TCP Veno (ver Cap. 3.5.5.1). Porém, o TCP
Compound é bem mais que uma simples junção, existindo algoritmos específicos para que as melhores
características de cada abordagem sejam realçadas.
A principal inovação nesta versão é a adição de uma 3ºjanela de congestão (após janela de receptor e
janela de congestão), a janela de atraso. A janela será responsável por cuidar de todas as alterações delay
based
44
. Algumas alterações efectuadas no normal incremento TCP foram:
),min( rwndlwndcwndwin +=
Com a adição da janela lwnd, o máximo de segmentos que é permitido ao emissor enviar será o mínimo
entre a janela de recepção, e a soma da janela de congestão com a janela de atraso
)(1 dwndcwndlcwndcwnd ++=
O incremento será também feito recorrendo à janela de atraso.
Não é efectuado nenhuma alteração à forma como é incrementada a normal janela de congestão. No que
diz respeito à janela de atraso, existe uma correspondência com a forma que o TCP Vegas decidia acerca
da mudança da janela de congestão; apesar dessa situação, a forma de diminuir e aumentar a dwnd já não
44
Variações no RTT ao longo do tempo de ligação.
92](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-114-320.jpg)
![3. Enquadramento ao Protocolo
é o normal incremento TCP, sendo utilizadas funções polinomiais que lhe permitem uma maior dinâmica
no crescimento.
A Figura 3.52 demonstra toda a dinâmica do uso destas duas janelas, sendo os pontos D, E, F, G os
pontos mais críticos de mudança. O TCP representa todo o normal crescimento da janela de congestão; o
DWND representa a janela de atraso; o CTCP referencia o funcionamento Compound TCP usando ambas
as janelas. As janelas são incrementadas até ao ponto E, a partir daí a janela de congestão (Janela Reno)
indica a continuação do aumento de envio de segmentos; por outro lado, a janela de atraso (janela Vegas)
indica que a rede está próxima da congestão, sendo necessário baixar o ritmo; a soma das duas janelas
revela a decisão tomada para o correcto funcionamento da rede.
Figura 3.52 – Representação do funcionamento das janelas de congestão e atraso Compound TCP.
3.6.8. Outros
As versões específicas para alto débito dividem-se, essencialmente, entre abordagens LCA ou DCA, ou
ambas; com maior justiça na atribuição de recursos, ou mais “agressivas”.
Para além das versões anteriores, existem variadas versões: TCP Africa, TCP Libra, TCP Paris, TCP
Rome, etc. Algumas destas versões utilizam também uma divisão em fluxos paralelos de dados para
alcançar maior eficiência na rede.
Outra forma de abordar a requisição de eficiência por parte da rede é utilizar a assistência dos próprios
routers utilizando mecanismos de congestão explícita (ver Cap. 2.1.5.2). Um importante protocolo para
essa operação é o XCP [32]. Esta forma de controlo de congestão foi primeiro explorada no conceito
ECN, sendo mais tarde generalizada no XCP.
93](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-115-320.jpg)
![TCP em Redes de Elevado Débito
No XCP o feedback45
acerca da carga existente na rede é baseado em sinal explícitos, providenciando aos
routers notificarem individualmente o seu estado de congestão.
As desvantagens desta abordagem são principalmente o facto de não ser respeitado o conceito extremo-a-
extremo da camada de transporte e ser necessário a alteração dos dispositivos de redes intermédios.
Apesar disso, também ainda não foi provado que este tipo de protocolo atinge maior perfomance que os
normais algoritmos de congestão implícita para alto débito [9].
3.7. Ponto de Situação
No que diz respeito a qual é a melhor versão para alto débito, a questão não se revela nada simples de
responder. Cada versão aborda o alto débito de diferente forma, existindo sempre condições da própria
rede, utilizadas para maximizar a eficiência dos seus testes. Porém, recorrendo à IETF como entidade
reguladora de todo o desenvolvimento de redes, o HighSpeed TCP será a versão que mais eficiência traz
ao alto débito, estando proposto para standard; seguidamente surge o Scalable TCP ainda em estado de
draft46
.
Apesar das normas recomendadas pela IETF, a situação em relação à adopção do Highspeed TCP não é
elevada, muito por culpa de não ser a versão por omissão de nenhum sistema operativo.
De uma forma simples poderemos definir a percentagem de utilização de uma versão pela percentagem de
utilização de um sistema operativo. Por exemplo: o TCP newReno sendo a única versão permitida ao
utilizador Windows® será utilizado em cerca de 90%, pois 90% é a percentagem aproximada de utilização
deste sistema operativo. O BIC e o Westwood são as versões por omissão do Linux (conforme a
distribuição), sendo então utilizadas cerca de 8%; apesar dessa situação é bastante simples alterar a versão
TCP no sistema operativo Linux.
Apesar desta simples relação são necessários estudos de maior grau de detalhe e complexidade. Esses
estudos para além das versões TCP devem também verificar a utilização de todos os diversos
mecanismos. O último desses estudos foi efectuado em Fevereiro de 2004 [33].
O estudo revelou-se bastante importante, na medida em que revelou todo o estado do TCP na Internet.
Baseou-se em testes a servidores Web induzindo diversas situações de perdas, re-ordenações, erros, etc.
com o objectivo principal de verificar os algoritmos de controlo de congestão dos servidores e seus
diversos mecanismos TCP. De igual forma, foram também testados os dispositivos intermédios
(Firewalls, NAT, proxies, etc) que prejudicam por vezes as comunicações extremo-a-extremo.
45
Notificação ao emissor.
46
Referência IETF a uma especificação ainda em estado de desenvolvimento.
94](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-116-320.jpg)
![3. Enquadramento ao Protocolo
O estudo revelou situações bastante surpreendentes: em relação às firewalls foi verificado que algumas
identificam a negociação de ECN como uma aplicação port-scanner47
, quebrando de imediato a ligação;
em relação aos servidores foram verificadas versões sem Fast Retransmit (sendo a única explicação
implementações defeituosas de um qualquer sistema operativo), e versões que não respeitavam as normas
dos números de sequência através de um mecanismo intitulado TCP/IP fingerprint scrubbers [34] para
protecção a ataques de hacking.
Neste teste não foram verificadas as versões para alto débito, tendo sido apenas efectuadas formas de
induzir mecanismos das versões newReno, Reno, ou Tahoe, principalmente a forma como reagiam a uma
simples perdas e a múltiplas perdas (diferença entre newReno e Reno). Os testes efectuados em 84394
servidores revelaram-se esclarecedores, estando representados na Tabela 3.4. A adopção do newReno
verifica-se bastante elevada, seguida do Reno (15%), existindo ainda a versão Tahoe (4%) em alguns
servidores.
Versão Percentagem de uso
newReno 76%
Reno 15%
Tahoe 4%
Outro 1%
Tabela 3.4 – Valores de percentagem de utilização do TCP Tahoe, Reno e newReno.
Como apenas foram testados alguns mecanismos, dentro da abrangência newReno poderão existir
algumas versões alto débito (baseados em LCA). É de referir também que 68% dos servidores efectua
correctamente a negociação para Sack, e 93% não permite negociação ECN. São agora necessários novos
estudos, de forma a ser verificado, detalhadamente, todo o processo de adopção das versões TCP para alto
débito.
47
O inglês “port scanner” significa escutador de portos, sendo uma aplicação muito utilizada para efeitos maliciosos.
95](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-117-320.jpg)
![TCP em Redes de Elevado Débito
4.Testes Práticos
Não é pretendido nos testes deste capítulo uma verificação exaustiva das várias implementações
existentes. Cada implementação foi já sujeita a diversos testes de perfomance, tendo como cenário
ambientes completamente reais48
[35]. O objectivo principal dos testes é verificar quais as versões TCP
disponíveis para o normal utilizador poder adquirir um maior grau de eficiência, principalmente,
considerando as redes de alto débito e grandes atrasos.
Ao longo deste capítulo existem considerações a ter em conta que não pertencem ao âmbito do TCP,
sendo igualmente importantes nos testes, algumas delas são:
• A velocidade da rede não pode ser mais rápida do que a velocidade da sua ligação mais lenta;
• A rede não pode ser mais rápida que a capacidade de memória da máquina mais lenta;
• A rede não pode ser mais rápida que o tamanho de janela oferecido pelo receptor sobre o RTT.
Esta fórmula é feita substituindo o tamanho da janela pelo BDP (ver Cap. 3.3.2.2), na fórmula
utilizada para calcular a capacidade da rede. A fórmula ficará a seguinte:
RTT
Janela
Throughput =
• Ter a certeza de que a amostra de tempo retirada permite verificar todas as condições, eliminando
qualquer incerteza na medição;
• Conhecimento de todas as interfaces utilizadas durante os testes: aplicações, buffers das
aplicações, placas de rede, buffers da rede, rede, etc.
• As componentes de simulação por vezes não têm resultados tão próximos da realidade;
• É bastante simples adquirir mais largura de banda (apenas com a desvantagem dos custos), sendo
bastante mais complicado adquirir menos atraso (implica modificações nos protocolos, sistema
operativo, interfaces de rede, etc.).
Os testes TCP de diversas publicações por vezes não se revelam também muito coerentes, tornando a sua
análise bastante difícil. Este facto prende-se, principalmente, com a dispersão de parâmetros que existem,
48
Sem recorrer a qualquer componente de simulação.
96](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-118-320.jpg)
![4. Testes Práticos
aquando a configuração dos cenários. Quase todos os testes efectuados às diversas versões são efectuados
com diferentes parâmetros, tornando bastante difícil uma correcta comparação entre eles. Provavelmente,
esse facto prende-se com razões de maximização de eficiência por parte de cada versão, funcionando
então os testes como uma prova de às comunidades de investigação, de todas as máximas potencialidades
da respectiva versão.
Cada vez mais se exigem correctas comparações, pelo que existem tentativas de tornar os cenários cada
vez mais genéricos entre as versões [36].
4.1. Testes Linux
O surgimento deste projecto teve como base os resultados apresentados no documento “Experimental
Evaluation of TCP Protocolos for High-Speed Networks” [5]. Neste artigo é mencionado o facto da
versão normal do TCP, newReno, não aproveitar convenientemente os recursos que as ligações
proporcionam em ambientes LFN. Como tal, antes de iniciar o desenvolvimento de uma nova versão,
realizaram-se testes num cenário bastante simples, tentando simular ao máximo as condições descritas no
documento, de modo a averiguar a validade das conclusões.
No capítulo seguinte são referenciadas todas as configurações, necessárias para a simulação do ambiente
de testes do artigo.
4.1.1. Planeamento dos testes
No artigo é relatado que o teste foi realizado numa ligação transatlântica entre Dublin e Chicago a 1Gbit/s
e atraso de propagação de 100ms. Para simular este cenário utilizaram-se 3 PCs, dois extremos para
enviar e receber os dados e um PC (Personal Computer) a ligar os outros dois; este último PC introduz
atraso aos segmentos. O esquema de configuração do cenário inicial encontra-se na Figura 4.1.
Figura 4.1 – Cenário Simulado Inicial.
97](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-119-320.jpg)
![TCP em Redes de Elevado Débito
A Tabela 4.1 representa as especificações dos PC utilizados, verificando-se uma máquina bastante
actualizada em termos de hardware e duas já com um hardware um pouco antigo.
PC CPU RAM Placa de Rede SO
Emissor 3GHz 512Mbytes Intel PRO/1000 CT Kubuntu 06.10
Receptor 1.1GHz 354Mbytes SMC Networks SMC9452TX-1 EZ
Card 1000
Kubuntu 06.10
Intermédia 1.1GHz 512Mbytes 2 x SMC Networks SMC9452TX EZ
Card 1000
FreeBSD 6.1
Tabela 4.1 – Especificações de Hardware e SO usado por PC.
As máquinas emissora e receptora utilizam o sistema operativo Linux, por ser o sistema operativo em que
primeiro se implementam todas as novas versão TCP, verificando-se também uma maior gama na escolha
das versões.
A distribuição escolhida foi o Kubuntu por ser actualmente dos mais utilizados e ter um grande apoio
técnico por parte das suas comunidade. A aplicação utilizada para gerar tráfego foi o Iperf [91]; a escolha
deste programa, deve-se ao facto desta aplicação ter sido usada para bater o recorde actual [95] do
máximo de largura de banda utilizada por um único fluxo TCP. Para a captura de segmentos utilizou-se o
Tcpdump [90] por ser a aplicação mais poderosa, superando o Wireshark [97]. Na descodificação dos
ficheiros gerados pelo Tcpdump utilizou-se o TRPR [94]. No PC intermédio que interliga o emissor e o
receptor foi utilizado o sistema operativo FreeBSD [96], com a aplicação Dummynet [92] para introduzir
atraso na ligação. Desta forma é simulada uma ligação transatlântica.
Devido a vários problemas encontrados, na tentativa de simular as características da rede mencionadas no
artigo, foi impossível verificar de forma coerente as conclusões do documento. O cenário que, devido a
todas as restrições encontradas, foi possível testar e que pretende simular um ambiente LFN, encontra-se
na Figura 4.2.
Figura 4.2 – Cenário Final.
98](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-120-320.jpg)


![4. Testes Práticos
sem ter a simulação do atraso configurada. Mesmo com a introdução de atraso esperam-se os mesmos os
resultados, diferindo apenas no facto de demorar mais tempo a verificar-se o congestionamento, pois a
aceleração do troughput depende inversamente do atraso. O eixo dos xx representa os segundos, o eixo
dos yy o débito alcançado, esta definição é valida para todos os testes deste capítulo.
Figura 4.4 – Largura de banda ocupada com velocidade de 1Gbit/s, sem qualquer tipo de atraso.
A resolução deste problema passaria pela utilização de hardware com maior capacidade de
processamento [98]. A Tecnologia TOE (TCP Offload Engine) [99] também poderá ser utilizada,
retirando assim bastante carga de processamento ao CPU nas operações de rede.
Configuração 100Mbit/s e atraso de 1000ms
Perante esta situação problemática, alterou-se a velocidade para 100Mbit/s e aumentou-se o atraso, de
modo a que o produto troughput/atraso se mantenha. A fórmula seguinte foi já anteriormente referenciada
(ver Cap. 3.3.2.2). Para a relação entre a velocidade e o atraso se manter o BDP será igual, logo, sabendo
a velocidade que é 100Mbit/s pode-se determinar que o atraso é de 1000ms.
atrasoMbitBDP
mssMbitBDP
×=
×=
100
100/1000
msatraso
ms
sMbit
sMbit
atraso
mssMbitsMbitatraso
1000
100
/100
/1000
100/1000/100
=
×=
×=×
Iniciou-se então a reconfiguração de todo o cenário.
Mesmo ao diminuir a largura de banda e aumentar o atraso proporcionalmente, não foi possível realizar o
teste proposto, pois com esta configuração o troughput ainda não atinge o valor desejado, atingindo cerca
de 35Mbit/s como se pode verificar pela Figura 4.5.
101](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-123-320.jpg)
![TCP em Redes de Elevado Débito
Figura 4.5 – Simulação com atraso de 1000ms e 100Mbit/s (dummynet)
Para tentar resolver este novo problema decidiu-se alterar os valores dos buffers do TCP para verificar se
o problema seria desta configuração. Inicialmente os buffers encontravam-se configurados da seguinte
forma:
net.ipv4.tcp_rmem=4096 87380 174760
net.ipv4.tcp_wmem=4096 16384 131072
net.ipv4.tcp_mem=4096 65536 98304
net.core.rmem_max=105472
net.core.wmem_max=105472
O valor máximo dos buffers foram alterados com o comando sysctl no valor de aproximadamente 16KB e
67MB, usando os valores recomendandos por um manual para gigabit em Linux [100] (sendo o máximo
um múltiplo de 2).
O primeiro passo, usando os buffers de 16KB:
sysctl –w net.ipv4.tcp_rmem=4096 87380 16777216
sysctl –w net.ipv4.tcp_wmem=4096 16384 16777216
sysctl –w net.ipv4.tcp_mem=4096 65536 16777216
sysctl –w net.core.rmem_max=16777216
sysctl –w net.core.wmem_max=16777216
O segundo passo, usando os buffers de 67MB:
sysctl –w net.ipv4.tcp_rmem=4096 87380 67108864
sysctl –w net.ipv4.tcp_wmem=4096 16384 67108864
sysctl –w net.ipv4.tcp_mem=4096 65536 67108864
102](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-124-320.jpg)
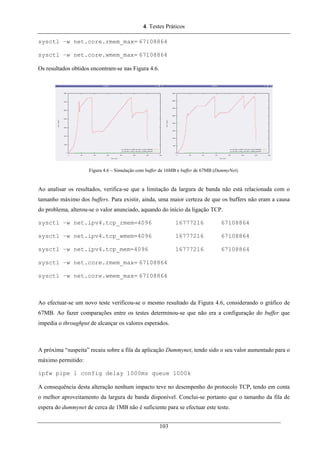
![TCP em Redes de Elevado Débito
A próxima tentativa foi utilizar outro programa que substituisse o gerador de atraso do dummynet. A
aplicação escolhida foi o Netem [93], que já vem integrado no kernel Linux. Para se efectuar a sua
configuração é apenas necessário introduzir o comando seguinte:
tc qdisc add dev eth0 root netem delay 500ms
Esta aplicação teve um desempenho, claramente, mais fraco que o Dummynet, como se pode verificar na
Figura 4.7. O máximo throughput atingido foi apenas de 11Mbit/s.
Figura 4.7 – Simulação com buffer máximo de 67MB e atraso de 1000ms (Netem)
Ao verificar-se que nenhuma das aplicações funcionava com os valores pretendido, decidiu-se diminuir o
atraso para metade (500ms). Desta forma, os requisitos para simulação dos testes efectuados no estudo
não conseguem ser correctamente cumpridos.
As configurações para implementar o novo atraso no Netem são:
tc qdisc add dev eth0 root netem delay 250ms
Os resultados, considerando, o Netem mantêm-se muito fracos.
Voltou-se a usar novamente o Dummynet por, claramente, apresentar resultados mais coerentes,
repetindo-se todos os testes realizados no Netem com o atraso configurado a 500ms:
ipfw pipe 1 config delay 500ms
Foram consideradas as duas situaçãoes de buffers referidas anteriormente, estando o resultado expresso na
Figura 4.8.
104](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-126-320.jpg)
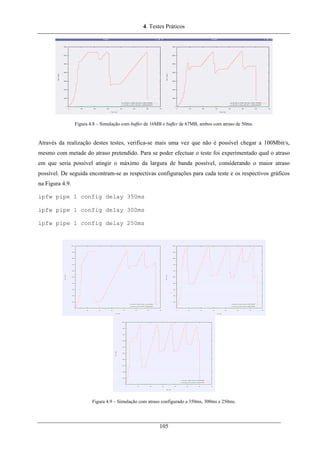
![TCP em Redes de Elevado Débito
Ao analisar os resultados verifica-se que o atraso máximo para manter a largura de banda a 100Mbit/s é
de 300ms.
TRPR
Outro problema que surgiu foi o facto do TRPR, aplicação para descodificar o ficheiro gerado pelo
Tcpdump, não permitir descodificar ficheiros maiores que 2GB. Este facto gerou alguns problemas, pois
limita o tamanho de captura do Tcpdump. Como tal, os protocolos que aproveitavam melhor a largura de
banda só podem ser testados durante um menor período de tempo, pois os ficheiros gerados pelo
Tcpdump ultrapassam o limite imposto pelo TRPR. Em relação aos protocolos mais lentos, como
transferem menor quantidade de informação durante o mesmo período de tempo, os ficheiros do Tcpdump
não ultrapassam os limites do TRPR, logo, poderão ser testados num maior período de tempo.
Kernel Linux
Outra dificuldade que surgiu, foi o facto do kernel Linux, que vem por omissão com a distribuição
Kubuntu utilizada, não ser compilado com todas as versões do protocolo TCP que o Linux suporta. Como
tal, foi necessário compilar um novo kernel [101] para se poder utilizar todas as versões. Para adicionar
todas as versões, é necessário garantir que algumas opções que se encontram no ficheiro .config se
encontram selecionadas. Na primeira coluna encontram-se as opções por omissão, na segunda coluna
encontram-se todas as opções para as versões TCP que devem ser seleccionadas:
CONFIG_TCP_CONG_ADVANCED=n CONFIG_TCP_CONG_ADVANCED=y
CONFIG_TCP_CONG_BIC=y CONFIG_TCP_CONG_BIC=y
CONFIG_TCP_CONG_CUBIC=n CONFIG_TCP_CONG_CUBIC=y
CONFIG_TCP_CONG_WESTWOOD=n CONFIG_TCP_CONG_WESTWOOD=y
CONFIG_TCP_CONG_HTCP=n CONFIG_TCP_CONG_HTCP=y
CONFIG_TCP_CONG_HSTCP=n CONFIG_TCP_CONG_HSTCP=y
CONFIG_TCP_CONG_HYBLA=n CONFIG_TCP_CONG_HYBLA=y
CONFIG_TCP_CONG_VEGAS=n CONFIG_TCP_CONG_VEGAS=y
CONFIG_TCP_CONG_SCALABLE=n CONFIG_TCP_CONG_SCALABLE=y
CONFIG_TCP_CONG_LP=n CONFIG_TCP_CONG_LP=y
CONFIG_TCP_CONG_VENO=n CONFIG_TCP_CONG_VENO=y
106](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-128-320.jpg)

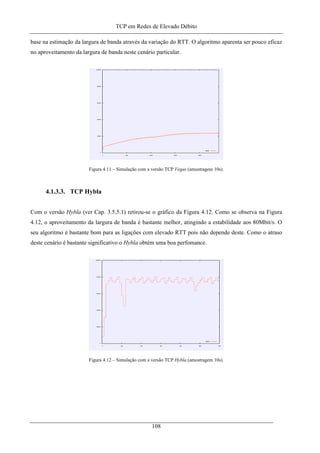
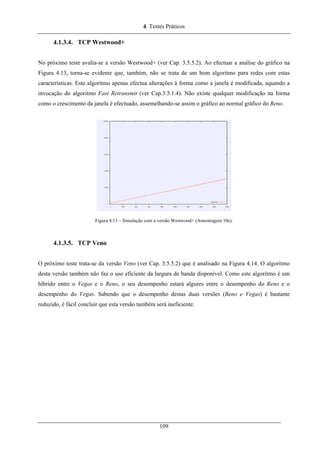
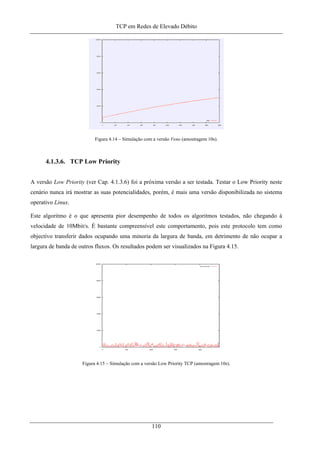

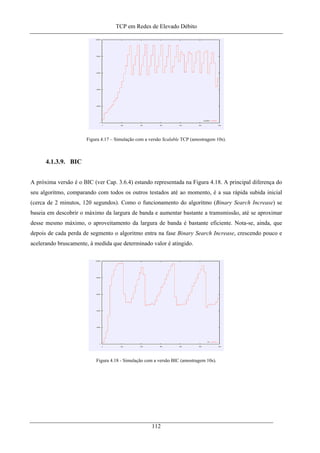
![TCP em Redes de Elevado Débito
Figura 4.20 – Simulação com a versão H-TCP (amostragem a 10s).
Figura 4.21 – Simulação com a versão H-TCP (amostragem a 5s).
4.1.4. Conclusões
Com a análise aos resultados obtidos através dos testes efectuados, constata-se facilmente que alguns
algoritmos não são próprios para alto débito, principalmente considerando redes LFN. O caso do
newReno foi demonstrado pelo artigo “Experimental Evaluation of TCP Protocolos for High-Speed
Network” [5], o qual se comprovou, também, através destes testes. No estudo, o protocolo é testado com
atraso real, sem qualquer componente simulado; os testes efectuados recorrem sempre a uma componente
simulada, que levantou diversos problemas (ver Cap. 4.1.2).
A falta de eficiência no aproveitamento da largura de banda não é só uma dificuldade do algoritmo Reno
pois o Westwood+, o Veno, o Vegas, também não são propícios para redes de alto débito e grande atraso.
No caso dos outros algoritmos, excepto o LP, existe um melhor aproveitamento da largura de banda por
terem sido desenvolvidos para o meio específico das redes LFN; é o caso do HighSpeed, Scalable, BIC,
114](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-136-320.jpg)
![4. Testes Práticos
CUBIC e H-TCP. Na Figura 4.22 estão todos os resultados dos testes de forma comparativa. A distinção
entre preparação para alto débito e a não preparação é bastante distingível.
Figura 4.22 – Simulação com todas as versões testadas.
De todas as principais versões do TCP as únicas que não foram testadas foram o FAST TCP (ver Cap.
3.6.6) e o Compound TCP (ver Cap. 3.6.7). A versão estável do TCP Compound apenas está disponível
no Microsof Windows Vista®, o FAST TCP ainda não se encontra estável o suficiente para ser inserido
no kernel Linux. Ainda em relação ao TCP Compound, este já se encontra em kernel de desenvolvimento.
Conclui-se também que para efectuar simulações deste tipo, caso não existam recursos suficientes para
efectuar os testes, recorreendo a componentes simuladas (geradores de atraso), deve-se optar por
plataformas de simulação. As plataformas de simulação, actualmente, estão bastante desenvolvidas e
conseguem resultados mais fiáveis do que usar cenários reais com componentes de simulação.
4.2. NS2
A principal vantagem de um simulador de redes de dados é, sem dúvida, a pouco necessidade de recursos.
Apesar desta situação, as plataformas de simulação são hoje bem mais do que só essa vantagem,
permitindo aos programadores diversas facilidades na implementação dos seus novos conceitos e
algoritmos. Existem dois principais simuladores: NS2 [103] e OPNET [104], e um simulador importante
por factos históricos: X-SIM [105]. Em relação ao X-SIM, utilizar a plataforma não se revela a melhor
opção, principalmente, devido ao facto da plataforma já ser bastante antiga e o seu desenvolvimento se
encontrar parado. O NS2 é uma plataforma Open-Source que não necessita de qualquer tipo de
licenciamento, ao contrário do OPNET [102] . Esse facto contribui decisivamente para a opção NS2 que
se encontra em grande desenvolvimento, sendo as únicas contrariedades o facto de existir menos
documentação e alguma falta de estabilidade no desenvolvimento de certos algoritmos.
115](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-137-320.jpg)
![TCP em Redes de Elevado Débito
O NS2 tem como base uma programação orientada aos objectos em C++, interligada com a linguagem de
script OTCL, também ela orientada aos objectos. A razão do NS2 usar estas duas linguagens é devido a
duas funções distintas que necessita de disponibilizar. A primeira função é fornecer detalhadas formas de
manipulações de bytes, cabeçalhos, implementações de diversos algoritmos, etc.; para este tipo de tarefas
é necessária maior preocupação no tempo de compilação. A segunda função tem como base a
configuração e reconfiguração rápida de cenários de rede, sendo mais prioritário o tempo que se demora a
alterar o código, do que propriamente compilá-lo (a configuração corre apenas uma vez, sem qualquer
ciclo).
A arquitectura NS é, então, composta por um cenário de rede que, conforme os dispositivos, estará ligado
a diversos algoritmos. Após toda a simulação efectuada poderão ser gerados ficheiros de trace49
, que
poderão ser posteriormente analisados por diversas aplicações. Toda esta arquitectura NS está
representada na Figura 4.23.
Figura 4.23 – Arquitectura NS (Fonte: [106]).
4.2.1. Classes TCP
As classes consideradas neste capítulo são as classes existentes na versão 2.30 do NS2, a mesma versão é
utilizada durante toda fase de implementação e testes.
As principais entidades de rede do NS2 são os nós, a aplicação e o agente. Estas entidades traduzem-se
em três classes: Node, Application, Agent. A classe Node não tem qualquer tipo associado. No que diz
respeito à classe Application existem diversos tipos associados [107], mas o único que permite a
49
Ficheiros para posterior análise de tráfego
116](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-138-320.jpg)
![4. Testes Práticos
utilização conjunta com um Agent TCP é o FTP (File Trasfer Protocol). Em relação à classe Agent
existem também alguns, sendo referenciados agora os TCP.
Existem dois tipos principais de TCP Agents: one-way Agents e two-way Agent. One-way Agents são
ainda sub-divididos numa gama de emissores TCP e receptores TCP (“sinks”).
O two-way Agent é considerado simétrico, devido ao facto de representar tanto um emissor como um
receptor. Este tipo está ainda em desenvolvimento pelo que não será utilizado.
Os emissores TCP one-way suportados por omissão estão representados na Tabela 4.2.
Agente Emissor Definição
Agent/TCP Um emissor TCP que utiliza a versão TCP Tahoe
(ver Cap. 3.5.1)
Agent/TCP/Reno Um emissor TCP que utiliza a versão TCP Reno
(ver Cap. 3.5.2)
Agent/TCP/Newreno Um emissor TCP que utiliza a versão TCP
newReno (ver Cap. 3.5.3).
Agent/TCP/Sack1 Um emissor TCP que utiliza Sack (ver Cap.
3.3.2.5) (é necessária a existência de um receptor,
também deste tipo, para que este protocolo
funcione).
Agent/TCP/Vegas Um emissor TCP que utiliza TCP Vegas (ver Cap.
3.5.4).
Agent/TCP/Fack Um emissor TCP Reno com FACK. Um algoritmo
que utiliza os blocos SACK para maior detalhe
sobre situações de congestão [37].
Tabela 4.2 – Definição dos Agentes Emissores TCP.
Considerado o outro extremo, os receptores TCP one-way, suportados por omissão, estão representados
na Tabela 4.3.
Agente Receptor Definição
Agent/TCPSink O normalmente utilizado, considera
117](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-139-320.jpg)

![4. Testes Práticos
patch [113], o utilizador NS2 tem, automaticamente, acesso a todas as versões TCP implementadas no
kernel mais recente do Linux. Para além disso, o código disponibilizado é exactamente o mesmo da stack
do sistema operativo, suportado por uma nova classe auxiliar criada para o efeito. A adição de qualquer
versão TCP deste sistema operativo pode também ser adicionada facilmente. As versões do TCP
disponibilizadas por esta implementação são neste momento: BIC, CUBIC, HighSpeed TCP, H-TCP,
Hybla, newReno, Scalable, Vegas, Westwood, Veno e Compound.
A nova classe Agent adicionada é a Agent/Linux. Nessa classe basta apenas efectuar a inicialização de
uma variável com a versão TCP pretendida, para que sejam invocados os algoritmos correspondentes. Um
simples cenário em que é utilizada esta implementação encontra-se no Anexo A.3.1.
É de referir também que esta versão, para além de todas as versões testadas, adiciona a versão Compound
TCP. Esta versão apenas se encontra implementada nos kernel mais instáveis, sendo essa a razão de não
existir no kernel usado anteriormente (ver Cap. 4.1).
4.2.3. Cenários
A definição de cenários em NS2 foi a primeira fase de todo o planeamento de testes depois da nova
versão implementada (ver Cap. 5.3). A principal preocupação dos cenários é conseguir que todos os
parâmetros que se pretende analisar sejam correctamente identificados. Foram definidos então dois
cenários:
• Cenário Lumbbell;
Este cenário é bastante conhecido de todas as comunidades de investigação do protocolo TCP. Baseia-se
essencialmente em 2 emissores, 2 routers e 2 receptores. As principais vantagens na utilização deste
cenário passam principalmente pela comparação de dois fluxos de duas versões diferentes, analisando
parâmetros como fairness e ocupação total de largura de banda. A configuração deste cenário encontra-se
representada na Figura 4.24, o respectivo script OTCL encontra-se no Anexo A.3.2.
119](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-141-320.jpg)

![5. EIC TCP
5.EIC TCP
Este capítulo corresponde à nova versão do protocolo TCP implementado.
Após toda a fase de estudo e testes práticos, o objectivo passou a ser a definição de novos parâmetros, que
fornecessem ao TCP novas formas de tratar todo o processo de congestão. Diversos conceitos surgiram,
baseados principalmente em algumas falhas das versões já implementadas. Obviamente os testes a essas
versões encontram-se já numa fase bastante avançada, verificando em maior detalhe algumas falhas. Este
facto veio facilitar imenso toda a análise efectuada.
5.1. Motivação
“Quando o emissor TCP aumenta a sua transmissão, o RTT pode não aumentar se não existir qualquer
tipo de congestionamento nas filas dos dispositivos. Este argumento é potencialmente válido para uma
ligação em que a ligação bottleneck tenha uma largura de banda bastante elevada”.[23]
O projecto foi iniciado através da verificação de um estudo [5]. A motivação para a nova versão iria
surgir, também, com base em outra publicação [23].
Existem duas motivações principais para todo o processo de especificação e posterior implementação:
• A cada vez mais fraca relação que existe entre o RTT e a taxa de transmissão da rede, à medida
que a largura de banda da rede aumenta;
• O Ack Compression [12] proporcionado pela filas de espera dos dispositivos, gerando alterações
bruscas no RTT de cada fluxo, sem necessariamente existir congestão.
A Relação Taxa de Transmissão e RTT
A relação existente entre a taxa de transmissão e o RTT não é muito fácil de analisar. As redes não têm a
mesma capacidade ao longo de todas as ligações, sendo aqui que surge o principal problema relacional.
Imaginando ligações conjuntas de baixo débito e alto débito, variados buffers das aplicações (sockets),
variados atrasos; existem uma série de condições que podem tornar a relação RTT e taxa de transmissão
muito reduzida.
121](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-143-320.jpg)
![TCP em Redes de Elevado Débito
A situação ideal para a maximização desta relação é ligações de baixo débito onde os buffers se
encontram sempre bastante sobrecarregados. A situação onde esta relação se encontra bastante
minimizada são ligações de alto débito, com tamanhos bastante curtos dos buffers aplicacionais e onde o
atraso seja reduzido; desta forma os buffers são muito menos testados, podendo existir atrasos que nada
têm a ver com congestão (opção por outros caminhos de rede, atraso variável do próprio meio etc.).
O conceito desta versão é tentar garantir que os buffers da rede se encontrem sempre em constantes testes,
retirando, após esses testes, as devidas decisões para as posteriores modificações na janela de congestão.
Ack Compression
Este problema já foi referido anteriormente, usando o TCP Vegas a técnica Spike Compression (ver Cap.
3.5.4) para atenuar esta situação. O problema desta técnica é que apenas limita a forma como o
espaçamento é efectuado, não definindo qualquer tipo específico de espaçamento. Esta nova versão tenta
contornar este problema, através de uma nova técnica de espaçamento entre os segmentos.
Estas duas situações, com a correcta solução implementada, poderão melhorar imenso toda a perfomance
TCP. A perfomance será adquirida, principalmente, porque as decisões a tomar ganham uma maior
garantia de que as filas estão mesmo congestionadas.
5.2. Especificação
“Supondo que um carro tem um controlo especial no pedal: o carro acelera com uma probabilidade ρ e
desacelera com uma probabilidade ρ-1, cada vez que o controlo é activado. A questão agora é: qual a
gama de valores para o qual ρ permite a arquitectura de um sistema fiável?”[23]
O principal problema de toda a especificação é não exagerar nos testes aos buffers, sob pena de em vez de
prevenir a congestão, aumentá-la.
Sendo o objectivo testar os buffers, nada melhor do que considerar a situação mais problemática para os
mesmos. Essa situação são segmentos enviados em burst.
Conforme o grau de congestionamento das filas, conforme a reacção ao burst; se as filas de encontrarem
bastante pouco sobrecarregadas, então o burst, provavelmente, passará pela rede como outro qualquer
conjunto de segmentos; se as filas se encontrarem com algum grau de congestionamento, então poderá
existir um aumento no RTT dos segmentos; se as filas estiverem já bastante congestionadas (situação
122](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-144-320.jpg)



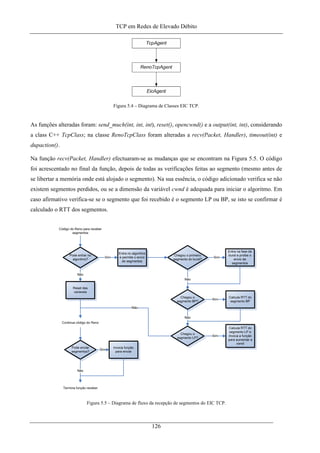
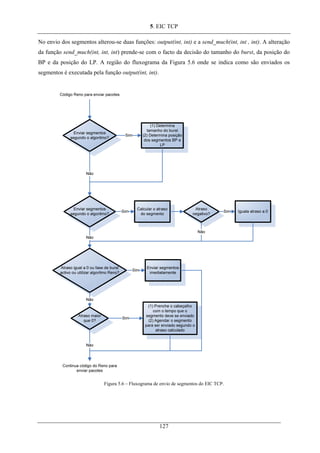


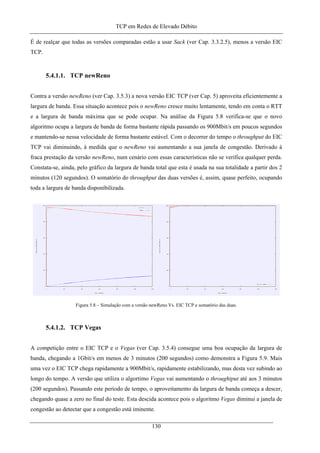
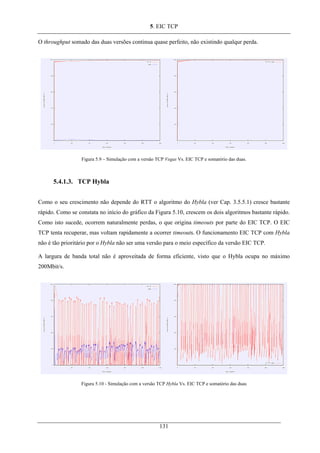


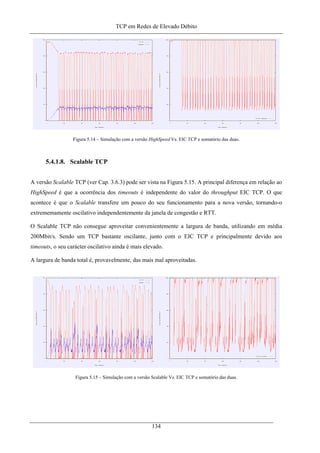
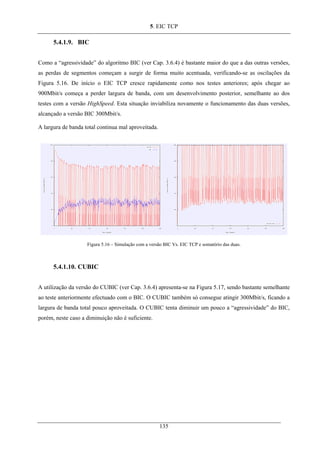
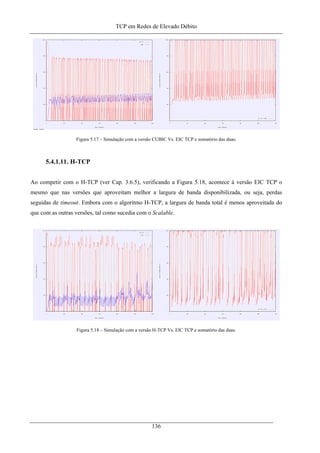

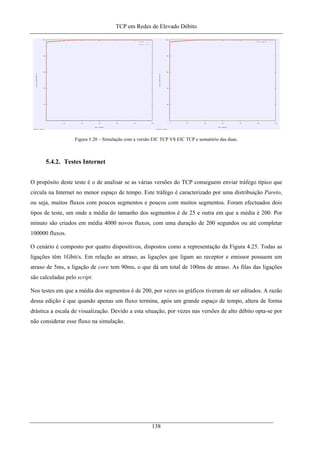
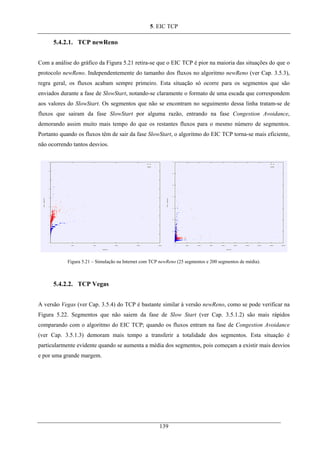
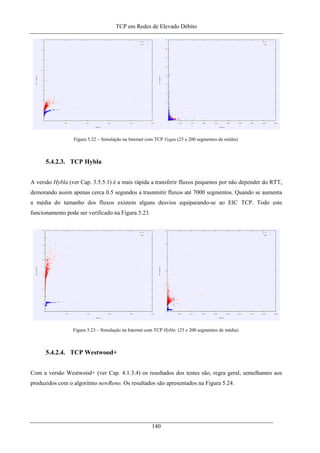
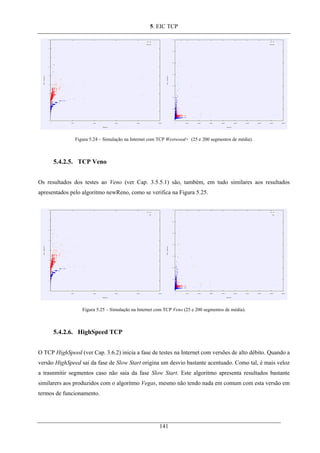
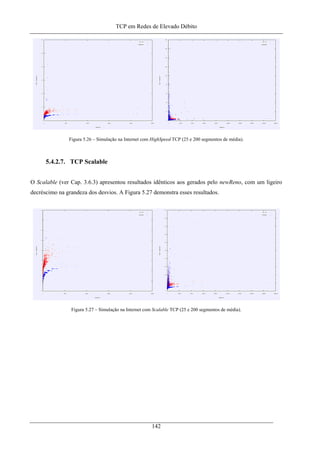

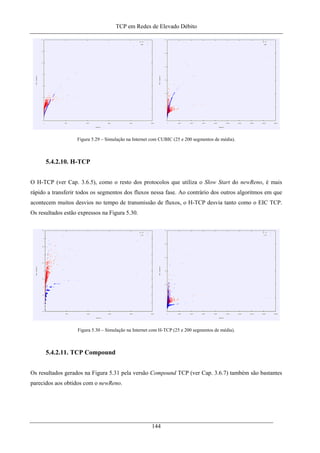
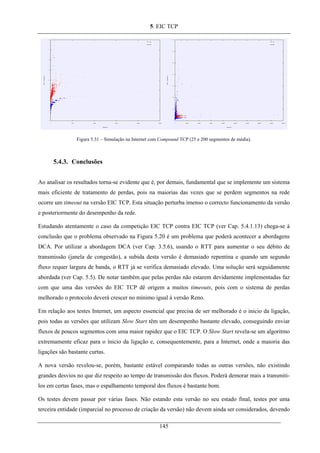



![7. Bibliografia
7.Bibliografia
Livros
[1] STEVENS. R. – TCP/IP Illustrated, Volume 1; Addison-Wesley Professional, ISBN
0201633469, 1993.
[2] COMER. D. – Internetworking with TCP/IP, Fourth Edition; Prentice Hall, ISBN 0130183806,
2000.
[3] TANENBAUM. A. – Computer Networks, Fourth Edition; Prentice Hall, ISBN 0130661023,
2002.
[4] KOZIEROK. C. – The TCP/IP Guide, ISBN 159327047X, 2005, http://www.tcpipguide.com/
Artigos e Papers
[5] YEE-TING, L.; LEITH, D.; SHORTEN L. – Experimental Evaluation of TCP Protocols for
High-Speed Networks, Hamilton Institute, 2005.
[6] NOUREDDINE, W.; TOBAGI, F. – Transmission Control Protocol, ICIR, 2002.
[7] HOUSTON, G. – TCP Performance, The Internet Protocol Journal, Volume 3, Número 2, 2000.
[8] HOUSTON, G. – The Future for TCP, The Internet Protocol Journal, Volume 3, Número 3,
2000.
[9] HOUSTON, G. – Gigabit TCP, The Internet Protocol Journal, Volume 9, No. 2, Junho 2006.
[10] KARN, P.; PARTRIDGE, C.; Estimating Round-Trip Times in Reliable Transport Protocols,
Proceedings SIGCOMM’87, 1987.
[11] JAIN, RAJ. – A Timeout-Based Congestion Control Scheme for Window Flow-Controlled
Networks, IEEE Journal, 1987.
[12] MOGUL. J. – Observing TCP Dynamics in Real World, Western Research Laboratory,
Research Report 92/2, 1992.
[13] JABOBSON, V.; KARELS, M. – Congestion Avoidance and Control, Proceedings of
SIGCOMM’88, 1988.
149](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-171-320.jpg)
![TCP em Redes de Elevado Débito
[14] JACOBSON, V. – Modified TCP congestion avoidance algorithm, Mailing List end2end-
interest@ISI.EDU, 1990.
[15] BRAKMO, L.; O'MALLEY, S.; PETERSON L. – TCP Vegas: New techniques for congestion
detection and avoidance, Proceedings of SIGCOMM’94, 1994.
[16] AHN, J.; DANZIG, P.; LIE, Z.; YAM, L. – Evaluation of TCP Vegas: Emulation and
Experiment, Proceedings of SIGCOMM’95, 1995.
[17] BRAKMO, L., PETERSON. L. – TCP Vegas: End to End Congestion Avoidance on a Global
Internet, IEEE Journal on Selected Areas in Communication, Volume 13, Número 8, 1995.
[18] HENGARTNER U.; BOLLIGER J.; Gross, T. – TCP Vegas Revisited, INFOCOM00, 2000.
[19] HOE, J. – Improving Startup-Behavior of a Congestion Control Scheme for TCP, Proceedings
of SIGCOMM’96, 1996.
[20] CAINI, C.; FIRRINCIELLI, R. – TCP Hybla: a TCP enhancement for heterogeneous networks,
Internacional Journal of Sattelite Communications and Networking, 547–566, 2004.
[21] FU, C.; LIEW, S. – TCP Veno: TCP Enhancement for Transmission Over Wireless Access
Networks, IEEE Journal, Volume 91, Número 2, 2003.
[22] KUZMANOVIC, A.; KNIGHTLY, E. – TCP-LP: A Distributed Algorithm for Low Priority
Data Transfer, Rice University, 2003.
[23] BIAZ, S.; VAYDIA, N. – Is the Roundtrip Time Correlated with the Number of Packets in
Flight ?, Internet Measurement Conference 2003, 2003.
[24] CROWROFT, J.; OECHCSLIN, P. – Differentiated End-to-End Internet Services Using a
Weighted Proportional Fair Sharing TCP, ACM SIGCOMM Computer Communication
Review, Volume 28, Número 3, 1998.
[25] KELLY, T. – Scalable TCP: Improving Performance in High-Speed Wide Area Networks,
ACM SIGCOMM Computer Communication Review, Volume 33, Número 2, 2003.
[26] XU. L.; HARFOUSH, K.; RHEE. I. – Binary Increase Congestion Control (BIC) for Fast Long-
Distance Networks, Proceedings of IEEE INFOCOMM 2004, 2004.
[27] XU, L.; RHEE, I. – CUBIC: A New TCP-Friendly High-Speed TCP Variant, PFLDnet 2005,
2005.
[28] GERLA, M.; SANADIDI, Y.; WANG, R.; ZANELLA, A.; CASSETI, C.; MASCOLO, S. –
TCP Westwood: Congestion Window Control Using Bandwidth Estimation, Proceedings of
IEEE Globecom 2001, Volume 3, 2001.
150](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-172-320.jpg)
![7. Bibliografia
[29] DELL’AERA, A.; GRECO, L. – Linux 2.4 Implementation of Westwood+ TCP with Rate-
Halving: A Performance Evaluation over the Internet, Tech. Rep. Número 08/03/S, Politecnico
di Bari.
[30] JIN, C.; WEI, X.; LOW, S. – FAST TCP: Motivation, Architecture, Algorithms, Performance,
Proceedings of IEEE INFOCOM 2004, 2004.
[31] TAN, K.; JINGMIN, S.; ZHANG, Q.; SRIDHARAN, M. – A Compound TCP Approach for
High-speed and Long Distance Networks, Microsoft Research Publications, 2005.
[32] KATABI, D.; HANDLEY, M.; ROHRS, C. – Congestion Control for High Bandwidth-Delay
Product Networks, ACM SIGCOMM Computer Communication Review, Volume 32, Número
4, 2002.
[33] MEDINA, A.; FLOYD, S. – Measuring The Evolution of Protocol of Transport Protocols in the
Internet, ICIR, 2004.
[34] SMART, M; MALAN, G.; JAHANIAN F. – Defeating TCP/IP Stack Fingerprinting, 9th
USENIX Security Symposium, 2000.
[35] BULLOT, H.; COTTRELL, L; JONES, R. – Evaluation of Advanced TCP Stacks on Fast Long-
Distance production Networks, PFLDnet 2004, 2004.
[36] TIERNEY, B.; LEE, J. – Techniques for Testing Experimental Network Protocols, PFLDnet
2004, 2004.
[37] MATTIS, M.; MAHDAVI, J. – Forward Acknowledgement: Refining TCP Congestion Control,
Pittsburgh Supercomputer Center, 1996.
RFC e drafts
[38] POSTEL. J. – Transmission Control Protocol (RFC793), 1981, ftp://ftp.rfc-editor.org/in-
notes/rfc793.txt
[39] CLARK. D. – Window and Acknowledgment Strategy in TCP (RFC813), 1982, ftp://ftp.rfc-
editor.org/in-notes/rfc813.txt
[40] NAGLE. G. – Congestion control in IP/TCP internetworks (RFC896), 1984, ftp://ftp.rfc-
editor.org/in-notes/rfc896.txt
[41] BRADEN. R. – Requirements for Internet Hosts – Communication Layers (RFC1122), 1989,
ftp://ftp.rfc-editor.org/in-notes/rfc1122.txt
[42] JACOBSON, V.; BRADEN, R.; BORMAN, D. – TCP Extensions for High Perfomance
(RFC1323), 1992, ftp://ftp.rfc-editor.org/in-notes/rfc1323.txt
151](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-173-320.jpg)
![TCP em Redes de Elevado Débito
[43] MATHIS, M.; MAHDAVI, J.; FLOYD, S.; ROMANOW, A. – TCP Selective Acknowledgment
Options (RFC2018), 1996, ftp://ftp.rfc-editor.org/in-notes/rfc2018.txt
[44] ALLMAN, M.; GLOVER, D.; SANCHEZ, L. – Enhancing TCP Over Satellite Channels using
Standard Mechanisms (RFC2488), 1999, ftp://ftp.rfc-editor.org/in-notes/rfc2488.txt
[45] ALLMAN, M. – TCP Congestion Control (RFC2581), 1999, ftp://ftp.rfc-editor.org/in-
notes/rfc2581.txt
[46] FLOYD, S.; HENDERSON, T. – The NewReno Modification to TCP’s Fast Recovery
Algorithm (RFC2582), 1999, ftp://ftp.rfc-editor.org/in-notes/rfc2582.txt
[47] FLOYD, S.; MAHDAVI, J.; MATHIS, M.; PODOLSKY, M. – An Extension to the Selective
Acknowledgement (SACK) Option for TCP (RFC2883), 2000, ftp://ftp.rfc-editor.org/in-
notes/rfc2883.txt
[48] ALLMAN, M.; BALAKRISHNAN, H.; FLOYD S. – Enhancing TCP's Loss Recovery Using
Limited Transmit (RFC3042), 2001, ftp://ftp.rfc-editor.org/in-notes/rfc3042.txt
[49] RAMAKRISHNAN, K.; FLOYD, S.; BLACK, D. – The Addition of Explicit Congestion
Notification (ECN) to IP (RFC3168), 2001, ftp://ftp.rfc-editor.org/in-notes/rfc3168.txt
[50] ALLMAN, M.; FLOYD, S.; PARTRIDGE, C. – Increasing TCP's Initial Window (RFC3390),
2002, ftp://ftp.rfc-editor.org/in-notes/rfc3390.txt
[51] FLOYD, S. – HighSpeed TCP for Large Congestion Windows (RFC3649), 2003, ftp://ftp.rfc-
editor.org/in-notes/rfc3649.txt
[52] FLOYD, S.; HENDERSON, T.; GURTOV, A. – The NewReno Modification to TCP's Fast
Recovery Algorithm (RFC3782), 2004, ftp://ftp.rfc-editor.org/in-notes/rfc3782.txt
[53] KOHLER, E.; HANDLEY, M.; FLOYD S. – Datagram Congestion Control Protocol (DCCP)
(RFC3782), 2006, ftp://ftp.rfc-editor.org/in-notes/rfc3782.txt
[54] FLOYD, S.; ALLMAN, M. – QuickStart for TCP and IP (RFC4782), 2007, ftp://ftp.rfc-
editor.org/in-notes/rfc4782.txt
[55] LEITH, S.; SHORTEN. R. – H-TCP: TCP Congestion Control for High Bandwidth-Delay
Product Paths, http://www.ietf.org/internet-drafts/draft-leith-tcp-htcp-03.txt
Apresentações
[56] LOUREIRO, P. – Diapositivos das aulas de Gestão Inteligente de Redes e Serviços, ESTG-
Leiria, 2006.
[57] VEIGA, N. – Diapositivos das aulas de Sistemas Operativos 2, ESTG-Leiria, 2003.
152](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-174-320.jpg)
![7. Bibliografia
[58] Prevenção e controlo de congestão, Disciplina de Sistemas Telemáticos, Universidade do
Minho, 2005.
[59] LOW, S. – TCP Congestion Control: Algoritms & Models, IPAM, 2002.
[60] NAVEEN, M. – TCP Variations, University of Delawan, 2005.
[61] ANIRBAN, M. – Transmission Control Protocol, University of Calgary, 2004.
[62] RAVOT, S. – TCP Transfers over high latency/bandwidth networks & Grid DT, PFLDnet,
2003.
[63] PRASAD. R.; JAIN, M.; DOVROLIS, C. – On the Effect of Delay Based Congestion
Avoidance, PFLDnet, 2004.
[64] K. NAKAUCHI, K.; BOBAYASHI, K. – Studying Congestion Control with Explicit Router
Feedback Using Hardware-based Network Emulator, PFLDnet, 2005.
Websites
[65] Bell 10Gbit/s Record, http://www.sciencedaily.com/releases/1999/05/990512000130.htm
[66] NTT 14Tbit/s Record, http://arstechnica.com/news.ars/post/20061002-7878.html
[67] IEC Tutorial, http://www.iec.org/online/tutorials/opt_ethernet/index.html
[68] TCP Maintenance and Minor Extensions, http://tools.ietf.org/wg/tcpm/
[69] Transport Area Working Group, http://tools.ietf.org/wg/tsvwg/
[70] Lawrence Berkeley Laboratory, http://www.lbl.gov/
[71] Paco Alto Research Center, http://www.parc.xerox.com/about/pressroom/news/2006-11-20-
contentcentric.html/
[72] IEEE, http://www.ieee.org/
[73] Special Interest Group, http://www.acm.org/sigs/guide98.html/
[74] SIGCOMM96, http://www.sigcomm.org/sigcomm96/program.html/
[75] ICSI, http://www.icsi.berkeley.edu/
[76] RED, http://en.wikipedia.org/wiki/Random_early_detection
[77] PDLDnet 2003, http://datatag.web.cern.ch/datatag/pfldnet2003/
[78] PFLDnet 2004, http://www-didc.lbl.gov/PFLDnet2004/
[79] PFLDnet 2005, http://www.ens-lyon.fr/LIP/RESO/pfldnet2005/
[80] PFLDnet 2006, http://www.hpcc.jp/pfldnet2006/
[81] IANA Assignments TCP header flags, http://www.iana.org/assignments/tcp-header-flags/
[82] IANA Assignments TCP parameters, http://www.iana.org/assignments/tcp-parameters/
[83] Ethereal, http://www.ethereal.com/
153](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-175-320.jpg)
![TCP em Redes de Elevado Débito
[84] Ethernet and TCP Throughput Model, http://www.babinszki.com/Networking/Max-Ethernet-
and-TCP-Throughput.html/
[85] Description of Windows TCP features, http://support.microsoft.com/kb/224829/
[86] DEC, http://www.answers.com/topic/digital-equipment-corporation
[87] Kubuntu, http://www.kubuntu.org/
[88] Xgraph, http://www.xgraph.org/
[89] Gnuplot, http://www.gnuplot.info/
[90] Tcpdump, http://www.tcpdump.org/
[91] Iperf, http://dast.nlanr.net/Projects/Iperf/
[92] Dummynet, http://freshmeat.net/projects/dummynet/
[93] Netem, http://linux-net.osdl.org/index.php/Netem/
[94] Trpr, http://pf.itd.nrl.navy.mil/protools/trpr.html/
[95] Internet Land Speed Record, http://www.internet2.edu/lsr/
[96] FreeBSD, http://www.freebsd.org/
[97] Wireshark, http://www.wireshark.org/
[98] How to Achieve Gigabit Speeds in Linux, http://datatag.web.cern.ch/datatag/howto/tcp.html/
[99] TOE, http://www.networkworld.com/details/653.html/
[100] TCP Tuning Guide, http://www-didc.lbl.gov/TCP-tuning/linux.html/
[101] Kernel Compilation Ubuntu, http://www.howtoforge.com/kernel_compilation_ubuntu/
NS2
[102] LUCIO, G.; FARRERA, M.; JAMMEH, E., FLEURY, M.; REED, M. – OPNET Modeler and
Ns-2: Comparing the Accuracy of Network Simulators for Packet-Level Analysis using a
Network Testbed, University of Essex, 2003.
[103] NS2 Official Page, http://www.isi.edu/nsnam/ns/
[104] OPNET, http://www.opnet.com/
[105] X-SIM, http://nsr.bioeng.washington.edu/Software/XSIM/xsim_download.html/
[106] REIS, L.; VICENTE, M. –Tutorial Network Simulator, ESTG Leiria, 2006
[107] FALL, K.; VARADHAN, K. – The ns Manual, The VINT Project, 2006.
154](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-176-320.jpg)
![7. Bibliografia
[108] ALTMAN, E.; JIMENEZ, T. – NS Simulator for Begginers, University de Los Andes, 2003.
[109] ANTILA, J. – TCP Perfomance Simulations using NS2, Helsinki University of Tecnology, 1999
[110] NS Simulator Course for Beginners,
http://www.sop.inria.fr/mistral/personnel/Eitan.Altman/ns.htm/
[111] Pedro Vale Estrela – NS2, http://mega.ist.utl.pt/~pmsrve/ns2/
[112] Mark Greis’s Tutorial, http://www.isi.edu/nsnam/ns/tutorial/index.html/
[113] Linux TCP Implementation, http://www.cs.caltech.edu/~weixl/technical/ns2linux/index.html/
155](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-177-320.jpg)




![TAnexos
A análise do código das diversas versões implementadas é essencial para toda a compreensão da
implementação de uma nova versão. A localização no diverso código dos algoritmos e mecanismos
estudados na teórica é essencial nesta tarefa.
5. Nova Versão
A fase de implementação aborda todas as tarefas relacionadas com a nova versão do protocolo que se
pretende implementado.
5.1 Especificação 5.2 Implementação
A definição de tudo o que vai ser esta nova
versão.
Toda a parte de programação necessária ao
cumprimento da especificação é abordada nesta
tarefa.
5.3 Testes
Fase de controlo, e prova de tudo o que foi implementado.
A.2. Novo Protocolo
Neste anexo encontra-se o código inicial para a implementação de um novo protocolo TCP, baseado na
versão Reno. Para incluir o código na compilação NS são necessários alguns passos:
• No Makefile (directoria ns-2.30): Inserir Novo_Protocolo/Novo_Protocolo-end.o
• Colocar a pasta Novo_Protocolo em ns-2.30
• Compilar: make ns
• Pasta Novo_Protocolo: ns Novo_Protocolo-teste.tcl
• Confirmar o resultado: nam out.nam
A.2.1. Ficheiro novo_protocolo.cc
#ifndef lint
static const char rcsid[] =
"@(#) $Header: /nfs/jade/vint/CVSROOT/ns-2/xcp/xcp-end-sys.cc,v 1.7 2005/02/03
18:27:12 haldar Exp $";
#endif
163](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-185-320.jpg)




![TCP em Redes de Elevado Débito
//dynamically grow the timestamp array if it's getting full
if (bugfix_ts_ && window() > tss_size_* 0.9) {
double *ntss;
ntss = (double*) calloc(tss_size_*2, sizeof(double));
printf("resizing timestamp tablen");
if (ntss == NULL) exit(1);
for (int i=0; i<tss_size_; i++)
ntss[(highest_ack_ + i) % (tss_size_ * 2)] =
tss[(highest_ack_ + i) % tss_size_];
free(tss);
tss_size_ *= 2;
tss = ntss;
}
if (tss!=NULL)
tss[seqno % tss_size_] = tcph->ts();
tcph->ts_echo() = ts_peer_;
tcph->reason() = reason;
tcph->last_rtt() = int(int(t_rtt_)*tcp_tick_*1000);
if (ecn_) {
hf->ect() = 1; // ECN-capable transport
}
if (cong_action_ && (!is_retransmit || SetCWRonRetransmit_)) {
hf->cong_action() = TRUE; // Congestion action.
cong_action_ = FALSE;
}
/* Check if this is the initial SYN packet. */
if (seqno == 0) {
if (syn_) {
databytes = 0;
curseq_ += 1;
168](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-190-320.jpg)






![TAnexos
class Novo_ProtocoloSink : public TcpSink {
public:
Novo_ProtocoloSink(Acker* acker);
void recv(Packet* pkt, Handler*);
int command(int argc, const char*const* argv);
virtual void ack(Packet* opkt);
protected:
};
#endif /* ns_Novo_Protocolo_end_h */
A.3. Scripts
Neste anexo encontram-se os scripts com os cenários dos testes para se realizar as simulações.
A.3.1. Cenário Simples Linux NS2 Implementation
set ns [new Simulator]
#ficheiros com a janelas de congestão
#ficheiros com a largura de banda
set lb [open "lb1 1000Gb 100ms 1-.tr" w]
175](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-197-320.jpg)
![TCP em Redes de Elevado Débito
set winfile1 [open "winFile1 1000Gb 100ms 1-" w]
# Especifica um procedimento 'finish' para término da simulação
proc finish {} {
close $lb
close $winfile1
exit 0
}
set n1 [$ns node]
set n2 [$ns node]
set n3 [$ns node]
set n4 [$ns node]
$ns duplex-link $n1 $n2 1000Mb 5ms DropTail
$ns duplex-link $n2 $n3 1000Mb 100ms DropTail
$ns duplex-link $n3 $n4 1000Mb 5ms DropTail
$ns queue-limit $n2 $n3 10000
set tcp1 [new Agent/TCP/Linux]
$tcp1 set timestamps_ true
$tcp1 set window_ 67108864
$ns at 0 "$tcp1 select_ca bic"
$tcp0 set packetSize_ 1460
$ns attach-agent $n1 $tcp1
set ftp1 [new Application/FTP]
$ftp1 attach-agent $tcp1
set sink1 [new Agent/TCPSink/Sack1]
$sink1 set ts_echo_rfc1323_ true
176](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-198-320.jpg)
![TAnexos
$ns attach-agent $n6 $sink1
$ns connect $tcp1 $sink1
proc record {} {
global sink1 lb
#Criar uma inst cia do simulador
set ns [Simulator instance]
#Define o tempo depois do qual o procedimento deve ser chamado novamente
set time 0.9
#Quantos bytes foram recebidos pelos sinks?
set bw1 [$sink1 set bytes_]
#Obter o tempo actual
set now [$ns now]
#Calcular a largura de banda(MBit/s) e escrever nos ficheiros
puts $lb "$now [expr $bw1/$time*8/1000000]"
#Faz o reset aos bytes das fontes de traego (sink)
$sink1 set bytes_ 0
$ns at [expr $now+$time] "record"
}
proc plotWindow {tcpSource file} {
global ns
set time 0.1
set now [$ns now]
set cwnd [$tcpSource set cwnd_]
puts $file "$now $cwnd"
$ns at [expr $now+$time] "plotWindow $tcpSource $file"
}
# Definir tempos dos geradores de trafego
$ns at 0.0 "plotWindow $tcp1 $winfile1"
177](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-199-320.jpg)
![TCP em Redes de Elevado Débito
$ns at 0.0 "record"
$ns at 0.1 "$ftp1 start"
$ns at 1199.9 "$ftp1 stop"
# Processa o procedimento finish apos 1200 segundos de tempo de simulacao
$ns at 1200 "finish"
# Executa a simulacao
$ns run
A.3.2. Cenário Lumbbell
set ns [new Simulator]
#ficheiros com a janelas de congestão
#ficheiros com a largura de banda
set lb [open "lb1 1000Gb 100ms 1-.tr" w]
set lbb [open "lb2 1000Gb 100ms 1-.tr" w]
set lbt [open "lbt 1000Gb 100ms 1-.tr" w]
set winfile1 [open "winFile1 1000Gb 100ms 1-" w]
set winfile2 [open "winFile2 1000Gb 100ms 1-" w]
# Especifica um procedimento 'finish' para término da simulação
proc finish {} {
close $lb
close $lbb
close $winfile1
close $winfile2
exit 0
}
set n1 [$ns node]
set n2 [$ns node]
178](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-200-320.jpg)
![TAnexos
set n3 [$ns node]
set n4 [$ns node]
set n5 [$ns node]
set n6 [$ns node]
$ns duplex-link $n1 $n3 1000Mb 5ms DropTail
$ns duplex-link $n2 $n3 1000Mb 5ms DropTail
$ns duplex-link $n3 $n4 1000Mb 100ms DropTail
$ns duplex-link $n5 $n4 1000Mb 5ms DropTail
$ns duplex-link $n6 $n4 1000Mb 5ms DropTail
$ns queue-limit $n3 $n4 10000
$ns queue-limit $n1 $n3 10000
set tcp0 [new Agent/TCP/Reno/EIC]
$tcp0 set window_ 67108864
$tcp0 set packetSize_ 1460
$ns attach-agent $n1 $tcp0
set tcp1 [new Agent/TCP/Linux]
$tcp1 set timestamps_ true
$tcp1 set window_ 67108864
$ns at 0 "$tcp1 select_ca bic"
$tcp0 set packetSize_ 1460
$ns attach-agent $n2 $tcp1
set ftp0 [new Application/FTP]
$ftp0 attach-agent $tcp0
set ftp1 [new Application/FTP]
$ftp1 attach-agent $tcp1
set sink0 [new Agent/TCPSink]
179](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-201-320.jpg)
![TCP em Redes de Elevado Débito
$ns attach-agent $n5 $sink0
set sink1 [new Agent/TCPSink/Sack1]
$sink1 set ts_echo_rfc1323_ true
$ns attach-agent $n6 $sink1
$ns connect $tcp0 $sink0
$ns connect $tcp1 $sink1
proc record {} {
global sink0 lb
global sink1 lbb
global all lbt
#Criar uma inst cia do simulador
set ns [Simulator instance]
#Define o tempo depois do qual o procedimento deve ser chamado novamente
set time 0.9
#Quantos bytes foram recebidos pelos sinks?
set bw1 [$sink0 set bytes_]
set bw2 [$sink1 set bytes_]
set bwt [expr $bw1+$bw2]
#Obter o tempo actual
set now [$ns now]
#Calcular a largura de banda(MBit/s) e escrever nos ficheiros
puts $lb "$now [expr $bw1/$time*8/1000000]"
puts $lbb "$now [expr $bw2/$time*8/1000000]"
puts $lbt "$now [expr $bwt/$time*8/1000000]"
#Faz o reset aos bytes das fontes de traego (sink)
$sink0 set bytes_ 0
$sink1 set bytes_ 0
$ns at [expr $now+$time] "record"
}
180](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-202-320.jpg)
![TAnexos
proc plotWindow {tcpSource file} {
global ns
set time 0.1
set now [$ns now]
set cwnd [$tcpSource set cwnd_]
puts $file "$now $cwnd"
$ns at [expr $now+$time] "plotWindow $tcpSource $file"
}
# Definir tempos dos geradores de trafego
$ns at 0.0 "plotWindow $tcp0 $winfile1"
$ns at 0.0 "plotWindow $tcp1 $winfile2"
$ns at 0.0 "record"
$ns at 0.1 "$ftp0 start"
$ns at 50 "$ftp1 start"
$ns at 1199.9 "$ftp0 stop"
$ns at 1199.9 "$ftp1 stop"
# Processa o procedimento finish apos 1200 segundos de tempo de simulacao
$ns at 1200 "finish"
# Executa a simulacao
$ns run
A.3.3. Cenário Internet
Este script tem como base outro script, anteriormente, efectuado em Stanford (ver
http://yuba.stanford.edu/rcp/).
Para se executar este script deve-se corer primeiro o ficheiro run.pl, depois o average.pl e por fim
executar a última linha de código deste capítulo para criar o gráfico.
Para correr a simulação deve-se correr o ficheiro run.pl. O conteúdo deste ficheiro encontra-se a seguir:
181](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-203-320.jpg)
![TCP em Redes de Elevado Débito
#!/usr/bin/perl -w
$numFlows = 100000;
$cap = 1;
$rtt = 0.1;
$load = 0.8;
$numbneck = 1;
$BWdelay = ($rtt*$cap*1000000000)/(1000*8);
$init_nr_flows = 100000;
#$meanFlowSize = $BWdelay/1000;
$meanFlowSize = 25;
@pareto_shape = (1.6); #, 1.8, 2.2);
for ($i = 0; $i < @pareto_shape; $i++) {
`nice -n +20 ns sim-tcp-pareto.tcl $numFlows $cap $rtt $load $numbneck $init_nr_flows
$meanFlowSize $pareto_shape[$i] > logFile`;
`mv logFile logFile-pareto-sh$pareto_shape[$i]`;
`mv flow.tr flow-pareto-sh$pareto_shape[$i].tr`;
`mv queue.tr queue-pareto-sh$pareto_shape[$i].tr`;
}
O ficheiro tcl que contem o cenário deve chamar-se sim-tcp-pareto.tcl e o seguinte código é o seu
conteúdo:
Class TCP_pair
TCP_pair instproc init {args} {
$self instvar pair_id group_id id debug_mode
$self instvar tcps tcpr;# Sender TCP, Receiver TCP
eval $self next $args
$self set tcps [new Agent/TCP/Linux] ;# Sender TCP
$tcps select_ca highspeed
182](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-204-320.jpg)
![TAnexos
$tcps set timestamps_ true
$tcps set window_ 67108864
$self set tcpr [new Agent/TCPSink/Sack1] ;# Receiver TCP
$tcpr set ts_echo_rfc1323_ true
$tcps set_callback $self
$tcpr set_callback $self
$self set pair_id 0
$self set group_id 0
$self set id 0
$self set debug_mode 1
#puts "init TCP_pair"
}
TCP_pair instproc set_debug_mode { mode } {
$self instvar debug_mode
$self set debug_mode $mode
}
TCP_pair instproc setup {snode dnode} {
#Directly connect agents to snode, dnode.
#For faster simulation.
global ns link_rate
$self instvar tcps tcpr;# Sender TCP, Receiver TCP
$self instvar san dan ;# memorize dumbell node (to attach)
$self set san $snode
$self set dan $dnode
$ns attach-agent $snode $tcps;
$ns attach-agent $dnode $tcpr;
183](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-205-320.jpg)
![TCP em Redes de Elevado Débito
$ns connect $tcps $tcpr
#puts "setup TCP_pair"
}
TCP_pair instproc create_agent {} {
$self instvar tcps tcpr;# Sender TCP, Receiver TCP
$self set tcps [new Agent/TCP/Reno] ;# Sender TCP
$self set tcpr [new Agent/TCPSink] ;# Receiver TCP
#puts "create_agent TCP_pair"
}
TCP_pair instproc setup_wnode {snode dnode link_dly} {
#New nodes are allocated for sender/receiver agents.
#They are connected to snode/dnode with link having delay of link_dly.
#Caution: If the number of pairs is large, simulation gets way too slow,
#and memory consumption gets very very large..
#Use "setup" if possible in such cases.
global ns link_rate
$self instvar sn dn ;# Source Node, Dest Node
$self instvar tcps tcpr;# Sender TCP, Receiver TCP
$self instvar san dan ;# memorize dumbell node (to attach)
$self instvar delay ;# local link delay
$self set delay link_dly
$self set sn [$ns node]
$self set dn [$ns node]
$self set san $snode
$self set dan $dnode
184](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-206-320.jpg)
![TAnexos
$ns duplex-link $snode $sn [set link_rate]Gb $delay DropTail
$ns duplex-link $dn $dnode [set link_rate]Gb $delay DropTail
$ns attach-agent $sn $tcps;
$ns attach-agent $dn $tcpr;
$ns connect $tcps $tcpr
#puts "setup_wnode TCP_pair"
}
TCP_pair instproc set_fincallback { controller func} {
$self instvar aggr_ctrl fin_cbfunc
$self set aggr_ctrl $controller
$self set fin_cbfunc $func
#puts "set_fincallback TCP_pair"
}
TCP_pair instproc set_startcallback { controller func} {
$self instvar aggr_ctrl start_cbfunc
$self set aggr_ctrl $controller
$self set start_cbfunc $func
#puts "set_startcallback TCP_pair"
}
TCP_pair instproc setgid { gid } {
$self instvar group_id
$self set group_id $gid
#puts "setgid TCP_pair"
}
TCP_pair instproc setpairid { pid } {
$self instvar pair_id
185](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-207-320.jpg)
![TCP em Redes de Elevado Débito
$self set pair_id $pid
#puts "setpairid TCP_pair"
}
TCP_pair instproc setfid { fid } {
$self instvar tcps tcpr
$self instvar id
$self set id $fid
$tcps set fid_ $fid;
$tcpr set fid_ $fid;
#puts "setfid TCP_pair"
}
TCP_pair instproc set_debug_mode { mode } {
$self instvar debug_mode
$self set debug_mode $mode
#puts "set_debug_mode TCP_pair"
}
TCP_pair instproc start { nr_pkts } {
global ns
$self instvar tcps id group_id
$self instvar start_time pkts
$self instvar aggr_ctrl start_cbfunc
$self instvar pair_id
$self instvar siz
$self instvar debug_mode
$self set start_time [$ns now] ;# memorize
$self set pkts $nr_pkts ;# memorize
set pktsize [$tcps set packetSize_]
186](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-208-320.jpg)
![TAnexos
if { $debug_mode == 1 } {
puts "stats: [$ns now] start grp $group_id fid $id $nr_pkts pkts
($pktsize +40)"
}
if { [info exists aggr_ctrl] } {
$aggr_ctrl $start_cbfunc
}
#set c [new Application/FTP]
#$c attach-agent $tcps
#$ns at $start_time "$c send [expr $pktsize * $nr_pkts]"
$self set siz [expr $pktsize * $nr_pkts]
$tcps send $siz
puts "start TCP_pair $start_time $siz"
}
TCP_pair instproc stop {} {
$self instvar tcps tcpr
$tcps reset
$tcpr reset
#puts "stop TCP_pair"
}
TCP_pair instproc fin_notify {} {
global ns
$self instvar sn dn san dan
$self instvar tcps tcpr
187](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-209-320.jpg)
![TCP em Redes de Elevado Débito
$self instvar aggr_ctrl fin_cbfunc
$self instvar pair_id
$self instvar pkts
$self instvar dt
$self instvar pps
$self flow_finished
$tcps reset
$tcpr reset
if { [info exists aggr_ctrl] } {
$aggr_ctrl $fin_cbfunc $pair_id $pkts $dt $pps
}
#puts "fin_notify TCP_pair"
}
TCP_pair instproc flow_finished {} {
global ns
$self instvar start_time pkts id group_id
$self instvar dt pps
$self instvar debug_mode
set ct [$ns now]
$self set dt [expr $ct - $start_time]
$self set pps [expr $pkts / $dt ]
if { $debug_mode == 1 } {
puts "stats: $ct fin grp $group_id fid $id fldur $dt sec $pps pps"
}
#puts "flow_finished TCP_pair"
}
188](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-210-320.jpg)
![TAnexos
Agent/TCP/Linux instproc set_callback {tcp_pair} {
$self instvar ctrl
$self set ctrl $tcp_pair
#puts "set_callback Reno"
}
Agent/TCPSink/Sack1 instproc set_callback {tcp_pair} {
$self instvar ctrl
$self set ctrl $tcp_pair
#puts "set_callback Reno"
}
Agent/TCP/Linux instproc done {} {
global ns sink
$self instvar ctrl
#puts "[$ns now] $self fin-ack received";
if { [info exists ctrl] } {
$ctrl fin_notify
}
#puts "done Reno "
}
Agent/TCPSink/Sack1 instproc done {} {
global ns sink
$self instvar ctrl
#puts "[$ns now] $self fin-ack received";
if { [info exists ctrl] } {
$ctrl fin_notify
}
#puts "done Reno "
}
189](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-211-320.jpg)
![TCP em Redes de Elevado Débito
Class Agent_Aggr_pair
Agent_Aggr_pair instproc init {args} {
eval $self next $args
#puts "init Agent_Aggr_pair"
}
Agent_Aggr_pair instproc attach-logfile { logf logf1} {
#Public
$self instvar logfile logfile1
$self set logfile $logf
$self set logfile1 $logf1
#puts "attach-logfile Agent_Aggr_pair"
}
Agent_Aggr_pair instproc setup {snode dnode gid nr agent_pair_type} {
$self instvar apair ;# array of Agent_pair
$self instvar group_id ;# group id of this group (given)
$self instvar nr_pairs ;# nr of pairs in this group (given)
$self set group_id $gid
$self set nr_pairs $nr
for {set i 0} {$i < $nr_pairs} {incr i} {
$self set apair($i) [new $agent_pair_type]
#$apair($i) setup_wnode $snode $dnode 0.01
$apair($i) setup $snode $dnode
$apair($i) setgid $group_id ;# let each pair know our group id
$apair($i) setpairid $i ;# let each pair know his pair id
}
$self resetvars ;# other initialization
#puts "setup Agent_Aggr_pair"
190](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-212-320.jpg)

![TCP em Redes de Elevado Débito
$self instvar rv_flow_intval rv_npkts
set pareto_shape $shape
set rng1 [new RNG]
$rng1 seed $rands1
$self set rv_flow_intval [new RandomVariable/Exponential]
$rv_flow_intval use-rng $rng1
$rv_flow_intval set avg_ [expr 1.0/$lambda]
set rng2 [new RNG]
$rng2 seed $rands2
$self set rv_npkts [new RandomVariable/Pareto]
$rv_npkts use-rng $rng2
$rv_npkts set avg_ $mean_npkts
$rv_npkts set shape_ $pareto_shape
#puts "set_PParrival_process Agent_Aggr_pair"
}
Agent_Aggr_pair instproc set_PEarrival_process {lambda mean_npkts rands1 rands2} {
#setup random variable rv_flow_intval and rv_npkts.
#To get the r.v. call "value" function.
#ex) $rv_flow_intval value
#- PEarrival
#flow arrival: poissson with rate lambda
#flow length : exp with mean mean_npkts pkts.
$self instvar rv_flow_intval rv_npkts
set rng1 [new RNG]
192](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-214-320.jpg)
![TAnexos
$rng1 seed $rands1
$self set rv_flow_intval [new RandomVariable/Exponential]
$rv_flow_intval use-rng $rng1
$rv_flow_intval set avg_ [expr 1.0/$lambda]
set rng2 [new RNG]
$rng2 seed $rands2
$self set rv_npkts [new RandomVariable/Exponential]
$rv_npkts use-rng $rng2
$rv_npkts set avg_ $mean_npkts
#puts "set_PEarrival_process Agent_Aggr_pair"
}
Agent_Aggr_pair instproc set_PBarrival_process {lambda mean_npkts S1 S2 rands1 rands2}
{
#Public
#setup random variable rv_flow_intval and rv_npkts.
#To get the r.v. call "value" function.
#ex) $rv_flow_intval value
#- PParrival:
#flow arrival: poissson with rate $lambda
#flow length : pareto with mean $mean_npkts pkts and shape parameter $shape.
$self instvar rv_flow_intval rv_npkts
set rng1 [new RNG]
$rng1 seed $rands1
$self set rv_flow_intval [new RandomVariable/Exponential]
$rv_flow_intval use-rng $rng1
193](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-215-320.jpg)
![TCP em Redes de Elevado Débito
$rv_flow_intval set avg_ [expr 1.0/$lambda]
set rng2 [new RNG]
$rng2 seed $rands2
$self set rv_npkts [new Binomial_RV]
$rv_npkts use-rng $rng2
$rv_npkts set p_ [expr (1.0*$mean_npkts - $S2)/($S1-$S2)]
$rv_npkts set S1_ $S1
$rv_npkts set S2_ $S2
if { $p < 0 } {
puts "In PBarrival, prob for bimodal p_ is negative %p_ exiting.. "
exit 0
} else {
puts "# PBarrival S1: $S1 S2: $S2 p_: $p_ mean $mean_npkts"
}
#puts "set_PBarrival_process Agent_Aggr_pair"
}
Agent_Aggr_pair instproc resetvars {} {
#Private
#Reset variables
$self instvar stat_nr_finflow ;# statistics nr of finished flows
$self instvar stat_sum_fldur ;# statistics sum of finished flow durations
$self instvar fid ;# current flow id of this group
$self instvar last_arrival_time ;# last flow arrival time
$self instvar actfl ;# nr of current active flow
$self instvar stat_nr_arrflow ;# statistics nr of arrived flows
$self instvar stat_nr_arrpkts ;# statistics nr of arrived packets
$self set last_arrival_time 0.0
194](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-216-320.jpg)
![TAnexos
$self set fid 0 ;# flow id starts from 0
$self set stat_nr_finflow 0
$self set stat_sum_fldur 0.0
$self set stat_sum_pps 0.0
$self set actfl 0
$self set stat_nr_arrflow 0
$self set stat_nr_arrpkts 0
#puts "resetvars Agent_Aggr_pair"
}
Agent_Aggr_pair instproc schedule { pid } {
#Private
#Note:
#Schedule pair (having pid) next flow time
#according to the flow arrival process.
global ns
$self instvar apair
$self instvar fid
$self instvar last_arrival_time
$self instvar rv_flow_intval rv_npkts
$self instvar stat_nr_arrflow
$self instvar stat_nr_arrpkts
set dt [$rv_flow_intval value]
set tnext [expr $last_arrival_time + $dt]
set t [$ns now]
if { $t > $tnext } {
puts "Error, Not enough flows ! Aborting! pair id $pid"
flush stdout
195](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-217-320.jpg)
![TCP em Redes de Elevado Débito
exit
}
$self set last_arrival_time $tnext
$apair($pid) setfid $fid
incr fid
set tmp_ [expr ceil ([$rv_npkts value])]
incr stat_nr_arrflow
$self set stat_nr_arrpkts [expr $stat_nr_arrpkts + $tmp_]
$ns at $tnext "$apair($pid) start $tmp_"
#puts "schedule at $tnext $pid $tmp_"
}
Agent_Aggr_pair instproc fin_notify { pid pkts fldur pps } {
global ns
$self instvar logfile
$self instvar stat_sum_fldur stat_nr_finflow stat_sum_pps
$self instvar group_id
$self instvar actfl
$self instvar apair
#Here, we re-schedule $apair($pid).
#according to the arrival process.
$self set actfl [expr $actfl - 1]
incr stat_nr_finflow
$self set stat_sum_fldur [expr $stat_sum_fldur + $fldur]
196](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-218-320.jpg)
![TAnexos
$self set stat_sum_pps [expr $stat_sum_pps + $pps]
set fin_fid [$apair($pid) set id]
###### OUPUT STATISTICS #################
if { [info exists logfile] } {
puts $logfile "flow_stats: [$ns now] gid $group_id fid $fin_fid pkts $pkts
fldur $fldur avgfldur [expr $stat_sum_fldur/$stat_nr_finflow] actfl $actfl avgpps
[expr $stat_sum_pps/$stat_nr_finflow] finfl $stat_nr_finflow"
}
$self schedule $pid ;# re-schedule a pair having pair_id $pid.
#puts "fin_notify Agent_Aggr_pair"
}
Agent_Aggr_pair instproc start_notify {} {
#Callback Function
#Note:
#If we registor $self as "setcallback" of
#$apair($id), $apair($i) will callback this
#function with argument id when the flow between the pair finishes.
#i.e.
#If we set: "$apair(13) setcallback $self" somewhere,
#"start_notyf 13" is called when the $apair(13)'s flow is started.
global ns
$self instvar logfile1
$self instvar group_id
$self instvar actfl
incr actfl;
if { [info exists logfile1] } {
197](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-219-320.jpg)
![TCP em Redes de Elevado Débito
puts $logfile1 "flow_stats: [$ns now] gid $group_id actfl $actfl"
}
#puts "start_notify Agent_Aggr_pair"
}
Agent_Aggr_pair instproc statistics {} {
$self instvar stat_nr_finflow ;# statistics nr of finished flows
$self instvar stat_sum_fldur ;# statistics sum of finished flow durations
$self instvar fid ;# current flow id of this group
$self instvar last_arrival_time ;# last flow arrival time
$self instvar actfl ;# nr of current active flow
$self instvar stat_nr_arrflow ;# statistics nr of arrived flows
$self instvar stat_nr_arrpkts ;# statistics nr of arrived packets
puts "Aggr_pair statistics1: $self arrflows $stat_nr_arrflow finflow
$stat_nr_finflow remain [expr $stat_nr_arrflow - $stat_nr_finflow]"
puts "Aggr_pair statistics2: $self arrpkts $stat_nr_arrpkts avg_flowsize [expr
$stat_nr_arrpkts/$stat_nr_arrflow]"
#puts "statistics Agent_Aggr_pair"
}
#add/remove packet headers as required
#this must be done before create simulator, i.e., [new Simulator]
remove-all-packet-headers ;# removes all except common
add-packet-header Flags IP TCP ;# hdrs reqd for TCP (Do not remove "Flags")
set ns [new Simulator]
puts "Date: [clock format [clock seconds]]"
set sim_start [clock seconds]
puts "Host: [exec uname -a]"
198](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-220-320.jpg)
![TAnexos
#set tf [open traceall.tr w]
#$ns trace-all $tf
#set nf [open out.nam w]
#t$ns namtrace-all $nf
if {$argc != 8} {
puts "usage: ns xxx.tcl numflows link_rate(Gbps) RTT(per hop,sec) load numbneck
init_nr_flows meanFlowSize pareto_shape"
exit 0
}
set numflows [lindex $argv 0]
set link_rate [lindex $argv 1]
set mean_link_delay [expr [lindex $argv 2] / 2.0]
set load [lindex $argv 3]
set numbneck 1
set init_nr_flow [lindex $argv 5]
set mean_npkts [lindex $argv 6]
set pareto_shape [lindex $argv 7]
puts "Simulation input:"
puts "TCP Single bottleneck"
puts "numflows $numflows"
puts "link_rate $link_rate Gbps"
puts "RTT [expr $mean_link_delay * 2.0] sec"
puts "load $load"
puts "numbneck $numbneck"
puts "init_nr_flow $init_nr_flow"
puts "mean flow size $mean_npkts pkts"
puts "pareto shape $pareto_shape"
puts " "
#packet size is in bytes.
199](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-221-320.jpg)
![TCP em Redes de Elevado Débito
set pktSize 1460
puts "pktSize(payload) $pktSize Bytes"
puts "pktSize(include header) [expr $pktSize + 40] Bytes"
#Random Seed
set arrseed 4
set pktseed 7
puts "arrseed $arrseed pktseed $pktseed"
set lambda [expr ($link_rate*$load*1000000000)/($mean_npkts*($pktSize+40)*8.0)]
puts "Arrival: Poisson with lambda $lambda, FlowSize: Pareto with avg $mean_npkts pkts
shape $pareto_shape"
set sim_end 200
puts "sim_end $sim_end sec (may not be reached)"
#Only for TCP
Agent/TCP/Reno set packetSize_ $pktSize
#Agent/TCP set packetSize_ $pktSize
set tcpwin_ [expr 4 * int (ceil (($mean_link_delay * 2.0 * $link_rate *
1000000000.0/8.0) / ($pktSize+40.0)))]
Agent/TCP/Reno set window_ $tcpwin_
#Agent/TCP set window_ $tcpwin_
puts "Agent/TCP/Reno/CTN set window_ $tcpwin_"
############ Buffer SIZE ######################
#In case TCP , BWxRTT
set queueSize [expr int (ceil (($mean_link_delay * 2.0 * $link_rate *
1000000000.0/8.0) / ($pktSize+40.0)))]
Queue set limit_ $queueSize
puts "queueSize $queueSize packets"
200](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-222-320.jpg)
![TAnexos
############# Topoplgy #########################
set n0 [$ns node]
set n1 [$ns node]
set n2 [$ns node]
set n3 [$ns node]
$ns duplex-link $n0 $n1 [set link_rate]Gb 90ms DropTail
$ns duplex-link $n2 $n0 [expr $link_rate*2]Gb 5ms DropTail
$ns duplex-link $n1 $n3 [expr $link_rate*2]Gb 5ms DropTail
$ns queue-limit $n1 $n0 $queueSize
$ns queue-limit $n0 $n1 $queueSize
set bnecklink [$ns link $n0 $n1]
############# Agents #########################
set agtagr0 [new Agent_Aggr_pair]
puts "Creating initial $init_nr_flow agents ..."; flush stdout
$agtagr0 setup $n2 $n3 0 $init_nr_flow "TCP_pair"
#$agtagr0 setup $n0 $n1 0 $init_nr_flow "TCP_pair"
set flowlog [open flow.tr w]
set flowlog1 [open start.tr w]
$agtagr0 attach-logfile $flowlog $flowlog1
puts "Initial agent creation done";flush stdout
#For Poisson/Pareto
$agtagr0 set_PParrival_process $lambda $mean_npkts $pareto_shape $arrseed $pktseed
$agtagr0 init_schedule
201](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-223-320.jpg)
![TCP em Redes de Elevado Débito
$agtagr0 statistics
puts "Simulation started!"
$ns at 0.0 "check_fin"
proc check_fin {} {
global ns agtagr0 numflows
set nrf [$agtagr0 set stat_nr_finflow]
if { $nrf > $numflows } {
$agtagr0 statistics
finish
}
#puts "nr_finflow $nrf"
$ns after 1 "check_fin"
}
############# Queue Monitor #########################
set qf [open queue.tr w]
set qm [$ns monitor-queue $n0 $n1 $qf 0.1]
$bnecklink queue-sample-timeout
#$bnecklink start-tracing
$ns at $sim_end "finish"
proc finish {} {
global ns qf flowlog
global sim_start
$ns flush-trace
close $qf
close $flowlog
202](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-224-320.jpg)
![TAnexos
set t [clock seconds]
puts "Simulation Finished!"
puts "Time [expr $t - $sim_start] sec"
puts "Date [clock format [clock seconds]]"
exit 0
}
$ns run
Para analisar os ficheiros criados pelo script run.pl deve usar-se o ficheiro average.pl para este retirar os
resultados. O ficheiro encontra-se a seguir:
#!/usr/bin/perl -w
@fNameIn = ("flow-pareto-sh1.6.tr");
@fNameOut = ("flowSizeVsDelay-sh1.6");
$maximum = 0;
for ($i=0; $i<=$#fNameIn; $i++) {
for ($j=0; $j< 10000000; $j++) {
$sumDur[$j] = 0;
$avgDur[$j] = 0;
$maxDur[$j] = 0;
$numFlows[$j] = 0;
}
open(fileOut, ">$fNameOut[$i]") or die("Can't open $fNameOut[$i] for writing:
$!");
open(fileIn, "$fNameIn[$i]") or die ("Can't open $fNameIn[$i]: $!");
$maximum = 0;
$simTime = 0;
203](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-225-320.jpg)
![TCP em Redes de Elevado Débito
while (<fileIn>) {
chomp;
@items = split;
if ($items[7] > $maximum) {
$maximum = $items[7];
}
$sumDur[$items[7]] += $items[9];
if ($items[9] > $maxDur[$items[7]]) {
$maxDur[$items[7]] = $items[9];
}
$numFlows[$items[7]] += 1;
$avgDur[$items[7]] = $sumDur[$items[7]] / $numFlows[$items[7]];
}
for ($j=1; $j<= $maximum; $j++) {
if ($avgDur[$j] != 0) {
printf fileOut "$j sum_ $sumDur[$j] numFlows_ $numFlows[$j] avg_ $avgDur[$j]
max_ $maxDur[$j] n";
}
}
close(fileIn);
close(fileOut);
}
Para fazer o gráfico através dos ficheiros gerados pelo average.pl deve usar-se a seguinte linha:
cut -f1,7 -d" " flowSizeVsDelay-sh1.6 > grafico
A.4. Código EIC TCP
Nesta secção encontra-se o código alterado do protocolo.
204](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-226-320.jpg)
![TAnexos
A.4.1. Ficheiro eic-end.cc
#ifndef lint
static const char rcsid[] =
"@(#) $Header: /nfs/jade/vint/CVSROOT/ns-2/xcp/xcp-end-sys.cc,v 1.7 2005/02/03
18:27:12 haldar Exp $";
#endif
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include "ip.h"
#include "tcp.h"
#include "flags.h"
#include "agent.h"
#include "packet.h"
#include "flags.h"
#include "tcp-sink.h"
#include "eic-end.h"
#include "random.h"
#include "hdr_qs.h"
#define TRACE 0 // when 0, we don't print any debugging info.
static class EicRenoTcpClass : public TclClass {
public:
EicRenoTcpClass() : TclClass("Agent/TCP/Reno/EIC") {}
TclObject* create(int, const char*const*) {
return (new EicAgent());
205](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-227-320.jpg)














![TCP em Redes de Elevado Débito
void EicAgent::output(int seqno, int reason)
{
int force_set_rtx_timer = 0;
Packet* p = allocpkt();
hdr_tcp *tcph = hdr_tcp::access(p);
hdr_flags* hf = hdr_flags::access(p);
hdr_ip *iph = hdr_ip::access(p);
int databytes = hdr_cmn::access(p)->size();
tcph->seqno() = seqno;
tcph->ts() = Scheduler::instance().clock();
int is_retransmit = (seqno < maxseq_);
// Mark packet for diagnosis purposes if we are in Quick-Start Phase
if (qs_approved_) {
hf->qs() = 1;
}
// store timestamps, with bugfix_ts_. From Andrei Gurtov.
// (A real TCP would use scoreboard for this.)
if (bugfix_ts_ && tss==NULL) {
tss = (double*) calloc(tss_size_, sizeof(double));
if (tss==NULL) exit(1);
}
//dynamically grow the timestamp array if it's getting full
if (bugfix_ts_ && window() > tss_size_* 0.9) {
double *ntss;
ntss = (double*) calloc(tss_size_*2, sizeof(double));
printf("resizing timestamp tablen");
if (ntss == NULL) exit(1);
for (int i=0; i<tss_size_; i++)
ntss[(highest_ack_ + i) % (tss_size_ * 2)] =
220](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-242-320.jpg)
![TAnexos
tss[(highest_ack_ + i) % tss_size_];
free(tss);
tss_size_ *= 2;
tss = ntss;
}
if (tss!=NULL)
tss[seqno % tss_size_] = tcph->ts();
tcph->ts_echo() = ts_peer_;
tcph->reason() = reason;
tcph->last_rtt() = int(int(t_rtt_)*tcp_tick_*1000);
if (ecn_) {
hf->ect() = 1; // ECN-capable transport
}
if (cong_action_ && (!is_retransmit || SetCWRonRetransmit_)) {
hf->cong_action() = TRUE; // Congestion action.
cong_action_ = FALSE;
}
/* Check if this is the initial SYN packet. */
if (seqno == 0) {
if (syn_) {
databytes = 0;
curseq_ += 1;
hdr_cmn::access(p)->size() =
tcpip_base_hdr_size_;
}
if (ecn_) {
hf->ecnecho() = 1;
// hf->cong_action() = 1;
hf->ect() = 0;
}
221](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-243-320.jpg)




![TCP em Redes de Elevado Débito
* 0 0 0 reno_action
* 0 0 1 reno_action [impossible]
* 0 1 0 reno_action
* 0 1 1 retransmit, return
* 1 0 0 nothing
* 1 0 1 nothing [impossible]
* 1 1 0 nothing
* 1 1 1 retransmit, return
*/
void EicAgent::dupack_action()
{
/* Executa se a janela tiver aumentado, estipulando o máximo que a
janela de congetão
pode crescer para não aumentar demasiado rápido transmitindo mais
que a capacidade
da rede */
if(max_cwnd_decreased_ == 0)
{
max_cwnd_ = cwnd_*2/3;
temp_max_cwnd_ = 0;
max_cwnd_decreased_ = 1;
}
int recovered = (highest_ack_ > recover_);
int allowFastRetransmit = allow_fast_retransmit(last_cwnd_action_);
if (recovered || (!bug_fix_ && !ecn_) || allowFastRetransmit
|| (bugfix_ss_ && highest_ack_ == 0)) {
// (highest_ack_ == 0) added to allow Fast Retransmit
// when the first data packet is dropped.
// From bugreport from Mark Allman.
goto reno_action;
}
226](https://image.slidesharecdn.com/project-190623000053/85/New-TCP-version-for-large-bandwidth-networks-248-320.jpg)
































