Baixado 11 vezes



















![Explorando métricas de
similaridade
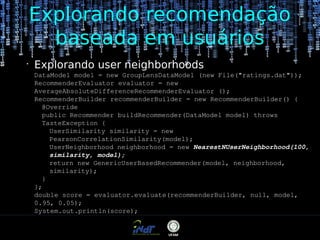
●
Correlação de Tanimoto
●
TanimotoCoefficientSimilarity
●
Ignora preferência de valores
●
Retorna valores entre 0 e 1
●
É possível transformar esse resultado para [-1, 1].
●
similarity = 2 * similarity - 1](https://image.slidesharecdn.com/mahoutcourse-daytwo-131105155901-phpapp01/85/Sistemas-de-Recomendacao-Usando-Mahout-Dia-2-21-320.jpg)
















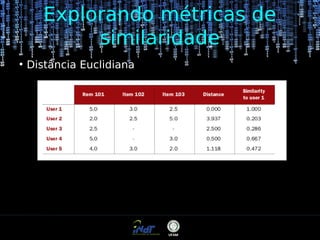
O documento aborda sistemas de recomendação utilizando Mahout, discutindo algoritmos baseados em usuários e itens, assim como métricas de similaridade como correlação de Pearson e distância euclidiana. São exploradas práticas de recomendação e exemplos práticos, incluindo o método Slope-One, além de considerações sobre análise de dados e contextos de recomendação. O texto também menciona a importância de pré-processamento e armazenamento eficiente de dados para melhorar a performance dos sistemas de recomendação.






















![[Jose Ahirton Lopes] Algoritmos de Recomendacao](https://cdn.slidesharecdn.com/ss_thumbnails/joseahirtonlopesalgoritmosderecomendacao-180906210256-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Jose Ahirton Lopes] Algoritmos de Recomendacao II](https://cdn.slidesharecdn.com/ss_thumbnails/joseahirtonlopesalgoritmosderecomendacao-1809062102561-181102020815-thumbnail.jpg?width=640&height=640&fit=bounds)












![[Jose Ahirton Lopes] Apresentacao Sessao Tecnica I](https://cdn.slidesharecdn.com/ss_thumbnails/apresentacao-sessaotecnicaijoseahirtonlopes-181118143847-thumbnail.jpg?width=640&height=640&fit=bounds)

