Baixar para ler offline














![Numba - utilização
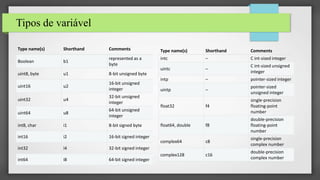
Algumas regras de utilização:
• Evite dict, list, tuplas. Existem recomendações para esses tipos:
• Typed Dict
• key_type
• value_type
from numba.typed import Dict
from numba.core import types
from numpy as np
# The Dict.empty() constructs a typed dictionary.
# The key and value typed must be explicitly declared.
d = Dict.empty(
key_type=types.unicode_type,
value_type=types.float64[:],
)
d['posx'] = np.asarray([1, 0.5, 2], dtype='f8')
String
Lista de float64
ndarray](https://image.slidesharecdn.com/apresentacaonumbamscopy-201104181742/85/Ganhando-performance-no-Python-com-Numba-em-projetos-nao-cientificos-15-320.jpg)
![Numba - utilização
Algumas regras de utilização:
• Manupulação de String dentro do numba é limitado
• Não há fstring, string format ou “%s %d” %(‘a’, 1)
• É possível concatenar somando strings
• É possível usar selectors “bom dia”[4:]
• Evite acesso a variáveis globais, a não ser que sejam do numba,
prefira passar por parâmetro (cuidado com o gil).
• Existem classes, mas não funcionam como nopython=true](https://image.slidesharecdn.com/apresentacaonumbamscopy-201104181742/85/Ganhando-performance-no-Python-com-Numba-em-projetos-nao-cientificos-17-320.jpg)
![Numba - utilização
Algumas regras de utilização:
• O tipo de cada atributo é
especificado (obrigatório)
• Funciona como uma classe mas,
tem peso extra para compilar
dinamicamente (não tem cache=True)
• Prático para trocar variáveis com
funções numba
spec = [
('value', int32), # a simple scalar field
('array', float32[:]), # an array field
]
@jitclass(spec)
class Bag(object):
def __init__(self, value):
self.value = value
self.array = np.zeros(value, dtype=np.float32)
@property
def size(self):
return self.array.size
n = 21
mybag = Bag(n)](https://image.slidesharecdn.com/apresentacaonumbamscopy-201104181742/85/Ganhando-performance-no-Python-com-Numba-em-projetos-nao-cientificos-18-320.jpg)
![Numba - utilização
Algumas regras de utilização:
• Conflito com tipos numpy no @jitclass:
No spec = [ ] apenas tipos
do Numba.
Alternativas
para extrair tipos numpy:](https://image.slidesharecdn.com/apresentacaonumbamscopy-201104181742/85/Ganhando-performance-no-Python-com-Numba-em-projetos-nao-cientificos-19-320.jpg)

![Calculando distribuição 50:50 de 2 colunas randomicas
def calculate3(x):
a = b = c = d = 0
for i in prange(x.shape[0]):
row = x[i]
if row[0] > 50:
a += 1
else:
b += 1
if row[1] < 50:
c += 1
else:
d += 1
return [a, b, c, d]
@njit(cache=True)
def calculate2(x):
a = b = c = d = 0
for i in prange(x.shape[0]):
row = x[i]
if row[0] > 50:
a += 1
else:
b += 1
if row[1] < 50:
c += 1
else:
d += 1
return [a, b, c, d]
@njit(parallel=True, nogil=True,
cache=True,
locals={'a': uint64, 'b': uint64,
'c': uint64,'d': uint64})
def calculate1(x):
a = b = c = d = 0
for i in prange(x.shape[0]):
row = x[i]
if row[0] > 50:
a += 1
else:
b += 1
if row[1] < 50:
c += 1
else:
d += 1
return [a, b, c, d]
Python puro Njit Simples Njit paranelizado](https://image.slidesharecdn.com/apresentacaonumbamscopy-201104181742/85/Ganhando-performance-no-Python-com-Numba-em-projetos-nao-cientificos-21-320.jpg)
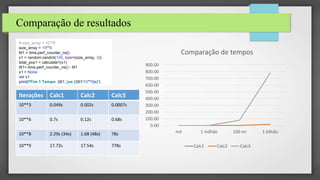
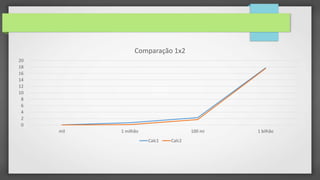

O documento resume três pontos principais sobre o Numba: (1) Ele fornece um compilador JIT para Python que equilibra produtividade e desempenho; (2) Permite compilar funções para execução em CPU ou GPU de forma paralela; (3) Testes mostraram que o Numba pode acelerar código em até 200 vezes em relação a Python puro.



























