





![+
Simulação
nGerando 1 milhão de famílias:
n newGalton <- data.frame(parent=rep(NA,1e6),child=rep(NA,1e6))
n newGalton$parent <- rnorm(1e6,mean=mean(galton
$parent),sd=sd(galton$parent))
n newGalton$child <- lm1$coeff[1] + lm1$coeff[2]*newGalton$parent +
rnorm(1e6,sd=sd(lm1$residuals))
n smoothScatter(newGalton$parent,newGalton$child)
n abline(lm1,col="red",lwd=3)
nSubamostra:
n set.seed(134325)
n sampleGalton1 <- newGalton[sample(1:1e6,size=50,replace=F),]
n sampleLm1 <- lm(sampleGalton1$child ~ sampleGalton1$parent)
n plot(sampleGalton1$parent,sampleGalton1$child,pch=19,col="blue")
n lines(sampleGalton1$parent,sampleLm1$fitted,lwd=3,lty=2)
n abline(lm1,col="red",lwd=3)
7](https://image.slidesharecdn.com/gabrielestatisticapos3-130605234119-phpapp01/85/Estatistica-Aula-3-7-320.jpg)
![+
Muitas subamostras
nGerando:
n sampleLm <- vector(100,mode="list")
n for(i in 1:100){
sampleGalton <- newGalton[sample(1:1e6,size=50,replace=F),]
sampleLm[[i]] <- lm(sampleGalton$child ~ sampleGalton$parent)
}
nO que posso inferir sobre meu modelo (linha vermelha), se o
que eu tenho quando faço subamostras é isso:
n smoothScatter(newGalton$parent,newGalton$child)
n for(i in 1:100){abline(sampleLm[[i]],lwd=3,lty=2)}
n abline(lm1,col="red",lwd=3)
8](https://image.slidesharecdn.com/gabrielestatisticapos3-130605234119-phpapp01/85/Estatistica-Aula-3-8-320.jpg)
![+
Histogramas das estimativas (a e b)
nHistograma de a:
n hist(sapply(sampleLm,function(x){coef(x)
[1]}),col="blue",xlab="Intercept",main="")
nHistograma de b:
n hist(sapply(sampleLm,function(x){coef(x)
[2]}),col="blue",xlab="Slope",main="")
nb0 ∼ N(b0,Var(b0))
9](https://image.slidesharecdn.com/gabrielestatisticapos3-130605234119-phpapp01/85/Estatistica-Aula-3-9-320.jpg)
![+
Estimando os valores em R
nEntendendo um modelo linear:
n sampleGalton4 <- newGalton[sample(1:1e6,size=50,replace=F),]
n sampleLm4 <- lm(sampleGalton4$child ~ sampleGalton4$parent)
n summary(sampleLm4)
nObservando as diferenças entra a população e a amostra:
n hist(sapply(sampleLm,function(x){coef(x)
[2]}),col="blue",xlab="Slope",main="",freq=F)
n lines(seq(0,5,length=100),dnorm(seq(0,5,length=100),mean=coef(sam
pleLm4)[2], sd=summary(sampleLm4)$coeff[2,2]),lwd=3,col="red")
10](https://image.slidesharecdn.com/gabrielestatisticapos3-130605234119-phpapp01/85/Estatistica-Aula-3-10-320.jpg)
![+
Intervalos de confiança
n Se temos uma estimativa b, e queremos saber quão bom esta
estimativa é.
n Um jeito é criar um nivel de confiança.
n Fazendo:
n summary(sampleLm4)$coeff
n confint(sampleLm4,level=0.95)
n Vendo:
n par(mar=c(4,4,0,2));plot(1:10,type="n",xlim=c(0,1.5),ylim=c(0,100),
xlab="Coefficient Values",ylab="Replication")
n for(i in 1:100){
n ci <- confint(sampleLm[[i]]); color="red";
n if((ci[2,1] < lm1$coeff[2]) & (lm1$coeff[2] < ci[2,2])){color = "grey"}
n segments(ci[2,1],i,ci[2,2],i,col=color,lwd=3)}
n lines(rep(lm1$coeff[2],100),seq(0,100,length=100),lwd=3)
11](https://image.slidesharecdn.com/gabrielestatisticapos3-130605234119-phpapp01/85/Estatistica-Aula-3-11-320.jpg)

![nSeus dados obedecem a uma distribuição:
nH0: Não há relação entre a altura do pai e do filho (b1=0).
nSob essa hipótese, temos:
nSimulando uma distribuição nula:
n x <- seq(-20,20,length=100)
n plot(x,dt(x,df=(928-2)),col="blue",lwd=3,type="l")
nEstatística observada:
n arrows(summary(lm1)$coeff[2,3],0.25,summary(lm1)$coeff[2,3],
0,col="red",lwd=4)
+
Hipoteses
13](https://image.slidesharecdn.com/gabrielestatisticapos3-130605234119-phpapp01/85/Estatistica-Aula-3-13-320.jpg)
![+
Exemplo simulado
n Regressão linear:
n set.seed(9898324)
n yValues <- rnorm(10); xValues <- rnorm(10)
n lm2 <- lm(yValues ~ xValues)
n summary(lm2)
n Comparando:
n x <- seq(-5,5,length=100)
n plot(x,dt(x,df=(10-2)),col="blue",lwd=3,type="l")
n arrows(summary(lm2)$coeff[2,3],0.25,summary(lm2)$coeff[2,3],0,col="red",lwd=4)
n Marcando:
n xSequence <- c(seq(summary(lm2)$coeff[2,3],
5,length=10),summary(lm2)$coeff[2,3])
n ySequence <- c(dt(seq(summary(lm2)$coeff[2,3],5,length=10),df=8),0)
n polygon(xSequence,ySequence,col="red"); polygon(-
xSequence,ySequence,col="red")
14](https://image.slidesharecdn.com/gabrielestatisticapos3-130605234119-phpapp01/85/Estatistica-Aula-3-14-320.jpg)
![+
Tamanho da amostra e P-value
n Amostra simulada:
n set.seed(8323); pValues <- rep(NA,100)
n for(i in 1:100){xValues <- rnorm(20);yValues <- rnorm(20); pValues[i] <-
summary(lm(yValues ~ xValues))$coeff[2,4] }
n hist(pValues,col="blue",main="",freq=F)
n abline(h=1,col="red",lwd=3)
n Adicionando um vies:
n set.seed(8323); pValues <- rep(NA,100)
n for(i in 1:100){xValues <- rnorm(20); yValues <- 0.2 * xValues + rnorm(20); pValues[i] <-
summary(lm(yValues ~ xValues))$coeff[2,4] }
n hist(pValues,col="blue",main="",freq=F)
n abline(h=1,col="red",lwd=3)
n Adicionando amostras:
n set.seed(8323); pValues <- rep(NA,100)
n for(i in 1:100){xValues <- rnorm(100); yValues <- 0.2 * xValues + rnorm(100); pValues[i] <-
summary(lm(yValues ~ xValues))$coeff[2,4] }
n hist(pValues,col="blue",main="",freq=F)
n abline(h=1,col="red",lwd=3)
15](https://image.slidesharecdn.com/gabrielestatisticapos3-130605234119-phpapp01/85/Estatistica-Aula-3-15-320.jpg)

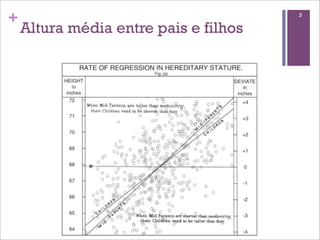
O documento discute modelagem estatística linear e p-values. Ele apresenta um modelo de regressão linear entre a altura dos pais e filhos, simula amostras deste modelo, e discute como p-values podem ser usados para testar hipóteses sobre os coeficientes do modelo à medida que o tamanho da amostra aumenta.

































