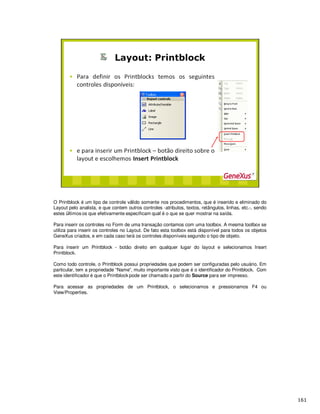
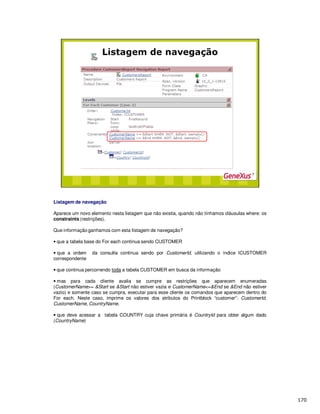
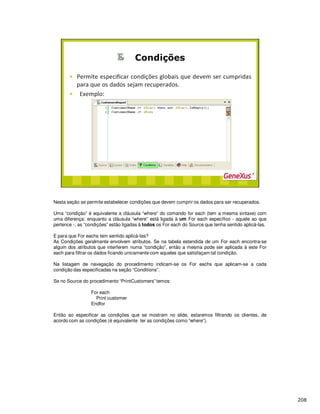
Baixado 44 vezes






















![O Printblock menssage (poderá ter um texto advertindo ao usuário que não existam clientes que
cumpram os filtros) executa somente quando não entrar no For each, isto é, quando não tem nenhum
registro correspondente na tabela base do For each para que se cumpram as Condições de filtro
Também aplica-se o For each [selected] line, XFor Each y XFor First, comandos que veremos mais
adiante.
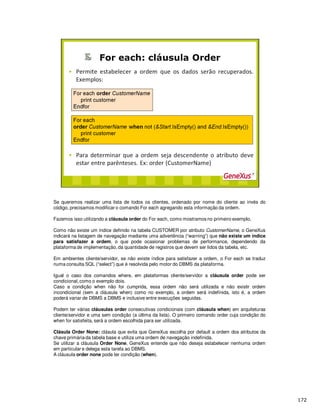
A cláusula when none deve ser a última dentro do For each. As ações a serem realizadas quando
não existe nenhum registro que cumpra as condições, ficam determinadas pelo bloque de código que
tem dentro cláusula when none do For each e do endfor.
Quando um For each não tem condições de filtro, os comandos do When none serão executados
somente no caso em que a tabela base do For each esteja vazia, porque somente nesse caso não
haverá nenhum registro que cumpra as condições de filtro.
Importante:
•Se aparecer atributos no bloque de código correspondente ao When none, estes não são levados
em consideração para determinar a tabela base do For each.
• Se incluir For eachs dentro do When none não se inferem Joins nem filtros de nenhum tipo com
respeito ao For each que contêm o When none, já que são considerados dos For eachs paralelos.](https://image.slidesharecdn.com/07-procedures-cursogxxbr-130915124930-phpapp01/85/07-procedures-curso-gxxbr-25-320.jpg)































1) Os procedimentos permitem definir processos não interativos de consulta e atualização da base de dados para gerar relatórios em PDF. 2) As definições dos procedimentos são feitas com base nos atributos e não diretamente nas tabelas, permitindo independência da estrutura da base de dados. 3) O código dos procedimentos é definido na seção Source usando uma linguagem procedural simples com comandos de controle e acesso a dados.






![[Certificacao ] normalizacao de dados e as formas normais](https://cdn.slidesharecdn.com/ss_thumbnails/certificacao-normalizacaodedadoseasformasnormais-141126111503-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)




























































