

Recomendados
Mais conteúdo relacionado
Mais procurados
Mais procurados (20)
Destaque
Destaque (20)
Semelhante a Adaptive filtersfinal
Semelhante a Adaptive filtersfinal (20)
Último
Último (20)
Adaptive filtersfinal
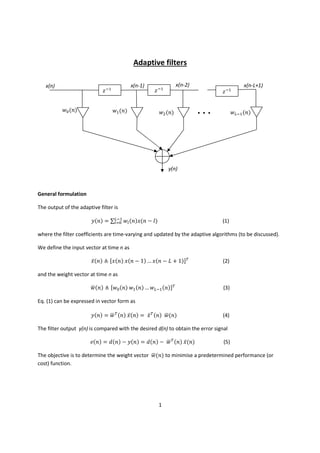
- 1. Adaptive filters x(n) ݓ ሺ݊ሻ ି ݖଵ x(n-1) ݓଵ ሺ݊ሻ ି ݖଵ ି ݖଵ x(n-2) ݓଶ ሺ݊ሻ x(n-L+1) ݓିଵ ሺ݊ሻ ... y(n) General formulation The output of the adaptive filter is ݕሺ݊ሻ = ∑ିଵ ݓ ሺ݊ሻݔሺ݊ − ݈ሻ ୀ (1) where the filter coefficients are time-varying and updated by the adaptive algorithms (to be discussed). We define the input vector at time n as ̅ݔሺ݊ሻ ≜ ሾݔሺ݊ሻ ݔሺ݊ − 1ሻ … ݔሺ݊ − 1 + ܮሻሿ் (2) ݓሺ݊ሻ ≜ ሾݓ ሺ݊ሻ ݓଵ ሺ݊ሻ … ݓିଵ ሺ݊ሻሿ் ഥ (3) ഥሺ݊ሻ ݕሺ݊ሻ = ் ݓሺ݊ሻ ̅ݔሺ݊ሻ = ் ̅ݔሺ݊ሻ ݓ ഥ (4) ݁ሺ݊ሻ = ݀ሺ݊ሻ − ݕሺ݊ሻ = ݀ሺ݊ሻ − ் ݓሺ݊ሻ ̅ݔሺ݊ሻ ഥ (5) and the weight vector at time n as Eq. (1) can be expressed in vector form as The filter output y(n) is compared with the desired d(n) to obtain the error signal The objective is to determine the weight vector ݓ ഥሺ݊ሻ to minimise a predetermined performance (or cost) function. 1
- 2. Optimization The most commonly used performance function is based on the mean squared error (MSE) defined as ߦሺ݊ሻ ≜ ܧሾ݁ ଶ ሺ݊ሻሿ (6) ത ഥሺ݊ሻ ߦሺ݊ሻ = ܧሾ݀ଶ ሺ݊ሻሿ − 2 ݓ ் ̅ሺ݊ሻ + ் ݓሺ݊ሻ ܴ ݓ ഥ ഥ (7) The MSE function determined by substituting eq. (5) in eq. (6) can be expressed as where ̅is the autocorrelation vector defined as ܧ ≜ ̅ሾ݀ሺ݊ሻ ̅ݔሺ݊ሻሿ = ሾݎௗ௫ ሺ0ሻ ݎௗ௫ ሺ1ሻ … ݎௗ௫ ሺ1 − ܮሻሿ் and ݎௗ௫ ሺ݇ሻ ≜ ܧሾ݀ሺ݊ + ݇ሻݔሺ݊ሻሿ is the autocorrelation function between ݀ሺ݊ሻ and ݔሺ݊ሻ. ത ܴ is the input autocorrelation matrix defined as ݎ௫௫ ሺ1ሻ … ݎ௫௫ ሺ1 − ܮሻ ݎ௫௫ ሺ0ሻ ݎ௫௫ ሺ1ሻ ݎ௫௫ ሺ0ሻ … ݎ௫௫ ሺ2 − ܮሻ ܴ ≜ ܧሾ ̅ݔሺ݊ሻ ் ̅ݔሺ݊ሻሿ = ൦ ൪ ⋮ ⋮ ⋱ ⋮ ݎ௫௫ ሺ1 − ܮሻ ݎ௫௫ ሺ2 − ܮሻ ⋯ ݎ௫௫ ሺ0ሻ where ݎ௫௫ is the autocorrelation function of ݔሺ݊ሻ. Steepest descent The MSE in eq. (7) is a quadratic function of the weights. We can use a steepest descent method in order to reach the minimum by following the negative gradient direction, in which the performance surface has the greatest rate of decrease. where ߤ is a step size. 1 + ݓሻ = ݓሺ݊ሻ − ∇ߦሺ݊ሻ ഥሺ݊ ഥ ఓ ଶ 2 (8)
- 3. The LMS algorithm In many practical applications, the statistics of d(n) and x(n) are unknown. Therefore, the steepest descent method cannot be used directly since it assumes exact knowledge of the gradient vector. The LMS algorithm uses the instantaneous error ݁ ଶ ሺ݊ሻ to estimate the Mean Squared Error (MSE). ߦሺ݊ሻ ≜ ݁ ଶ ሺ݊ሻ Therefore, the gradient used by the LMS algorithm can be written as ∇ߦሺ݊ሻ = ∇݁ ଶ ሺ݊ሻ = 2 ∙ ∇݁ሺ݊ሻ ∙ ݁ሺ݊ሻ (9) Since ݁ሺ݊ሻ = ݀ሺ݊ሻ − ் ݓሺ݊ሻ ̅ݔሺ݊ሻ ഥ ∇eሺnሻ = ∇൫݀ሺ݊ሻ − ் ݓሺ݊ሻ ̅ݔሺ݊ሻ൯ = −xሺnሻ ഥ ത Therefore, the gradient estimate of eq. (9) becomes ∇ߦሺ݊ሻ = −2 ∙ ݁ሺ݊ሻ ∙ ̅ݔሺ݊ሻ By substituting this gradient estimate into the steepest descent algorithm of eq. (8), we have ݓሺ݊ + 1ሻ = ݓ ഥ ഥሺ݊ሻ + ߤ ∙ ̅ݔሺ݊ሻ ∙ ݁ሺ݊ሻ This is the well-known LMS algorithm. It is simple and does not require squaring, averaging, and differentiating. The LMS structure is graphically depicted in the figure below. d(n) x(n) ݓ ഥሺ݊ሻ + y(n) - + e(n) LMS Steps for the application of the LMS algorithm: 1. Determine ߤ ,ܮand ݓ ഥሺ0ሻ , where L is the length of the filter, ߤ is the LMS step size, and ݓሺ0ሻ is ഥ the initial filter vector. 2. Compute the output of the adaptive filter as: ݕሺ݊ሻ = ∑ିଵ ݓ ሺ݊ሻݔሺ݊ − ݈ሻ ୀ 3. Compute the error signal ݁ሺ݊ሻ = ݀ሺ݊ሻ − ݕሺ݊ሻ 4. Update the adaptive filter vector using the LMS algorithm ݓ ሺ݊ + 1ሻ = ݓ ሺ݊ሻ + ߤ ∙ ݔሺ݊ − ݈ሻ ∙ ݁ሺ݊ሻ 3