Baixado 55 vezes





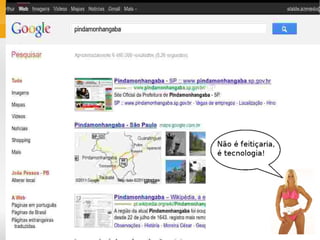










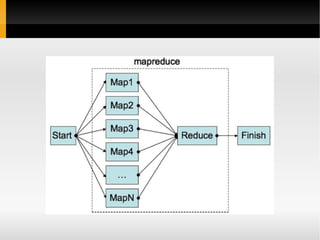

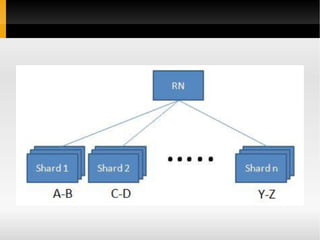
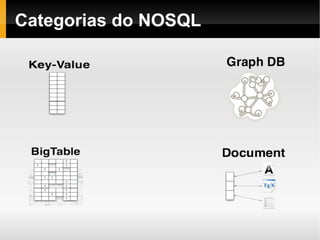






























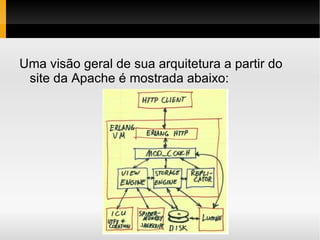

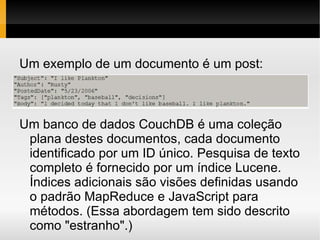





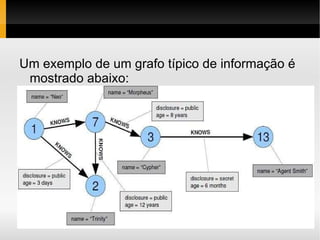







1) O documento apresenta conceitos sobre bancos de dados NoSQL, incluindo taxonomia, características como escalabilidade horizontal e replicação, e exemplos como Cassandra, HBase e Voldemort. 2) É discutido o teorema CAP e como diferentes bancos de dados NoSQL priorizam disponibilidade, consistência ou tolerância a partições. 3) São feitas comparações entre bancos de dados relacionais e NoSQL, cobrindo estrutura de dados, flexibilidade de esquema, normalização e acesso a dados.





























































