Transferir como PPS, PPTX













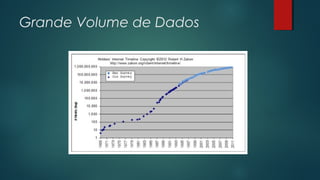





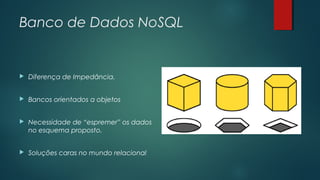

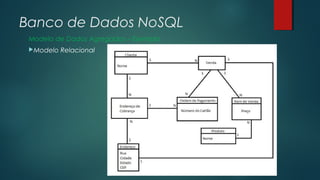
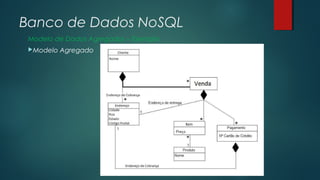



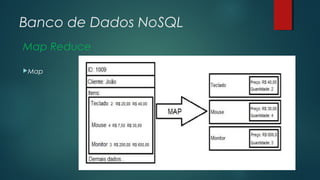
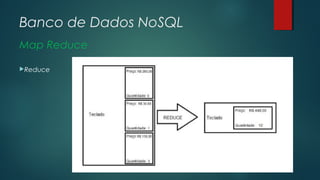
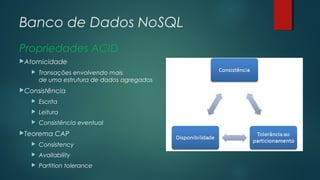
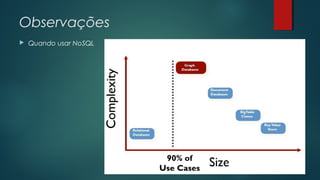



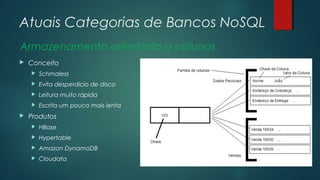














O documento apresenta uma introdução sobre bancos de dados NoSQL como uma alternativa ao modelo relacional tradicional. Aborda os principais motivos para o surgimento dos bancos NoSQL, como o grande volume de dados gerados na internet, e apresenta as principais categorias de bancos NoSQL, incluindo armazenamento em colunas, chave-valor, orientado a documentos e orientado a grafos.



































