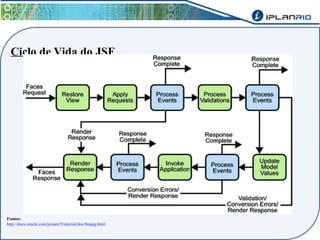
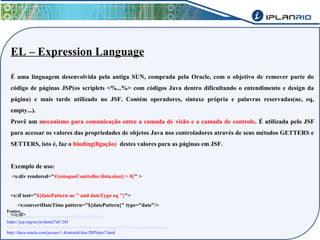
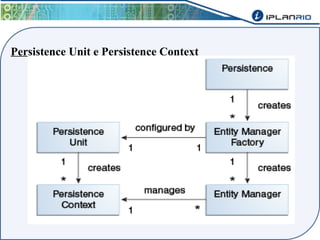
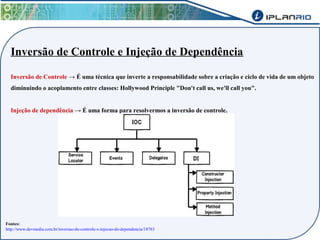
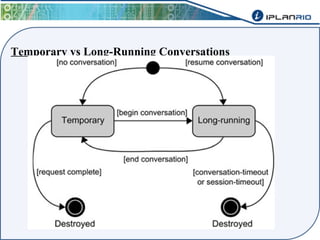
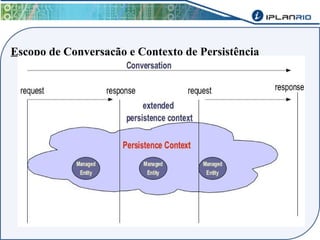
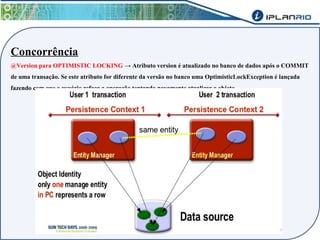
O documento discute o framework Maverick para aplicações JavaEE, incluindo seu uso do JBoss Seam para abstrair funcionalidades como autenticação, injeção de dependência e envio de e-mail. Também descreve a ferramenta Maverick-Gen para gerar projetos Maverick de acordo com padrões da empresa, assim como a estrutura de pastas típica de um projeto Maverick.