Baixar para ler offline



































![36
xA2 = C/2
A Figura 3.2 retrata a situação onde as variáveis x1 a xn correspondem a ações
sendo executadas num mesmo processador P. A ação xn, recentemente criada,
possui a mesma quantidade de trabalho restante e de trabalho total. Por outro lado,
a ação x1 foi criada num tempo passado.
share_resources: Para calcular a próxima data de terminação de uma ação, esta
função calcula uma nova solução do sistema LMM, caso necessário. Então, ela itera
sobre a lista de todas as ações ativas para calcular quando cada ação irá terminar,
baseado no compartilhamento atual dos recursos e a quantidade de trabalho restante
das ações, assumindo é claro, que o sistema se mantenha inalterado.
Portanto, a complexidade dessa função é Θ(|actions|) mais a complexidade da fun-
ção lmm_solve que também é Θ(|actions|).
update_resource_state: Toda vez que o estado de um recurso é alterado, é ne-
cessário atualizar a restrição correspondente cuja complexidade é Θ(1) e invalidar
o sistema LMM para recalcular o compartilhamento dos recursos.
update_action_state: Esta função avança o tempo simulado. Para isso, deve atu-
alizar a quantidade restante de trabalho de cada ação. Logo, o custo para iterar
sobre todas as ações é Θ(|actions|).
3.2.2 Análise de um simples caso de Computação Voluntária
Nesta seção é considerada uma plataforma com N máquinas cujos poderes de pro-
cessamento foram retirados dos traços disponíveis do projeto SETI@home (The Failure
Trace Archive, 2011). Em cada máquina um processo sequencialmente computa P tare-
fas cujas quantidades de trabalho são uniformemente amostradas no intervalo [0, 8.1012
]
(i.e., até aproximadamente 1 dia de cálculo numa máquina padrão). Este exemplo foi en-
viado por Eric Heien após ter utilizado o SimGrid no seu trabalho (HEIEN; FUJIMOTO;
HAGIHARA, 2008). Nas próximas seções, é analisada detalhadamente a complexidade
do SimGrid para rodar esse simples caso.
3.2.2.1 Inicialização do SimGrid
Durante a inicialização, um arquivo de plataforma, descrevendo as N máquinas, é
lido e as configurações são carregadas nas estruturas de dados correspondentes do SURF
e do LMM. Em seguida, o arquivo de deployment é lido, indicando em que máquina cada
processo irá executar. Com isso, os processos podem ser inicializados pelo SIMIX. Neste
caso, os processos rodam até a primeira chamada à função MSG_task_execute (para
executar uma tarefa na CPU), ponto no qual eles são bloqueados. No exemplo, todos os
processos são bloqueados a primeira vez no tempo simulado zero. A Figura 3.3 apresenta
as principais estruturas de dados criadas.
A complexidade geral da inicialização da simulação é Θ(N). Uma vez que cada
máquina é gerenciada independentemente, não é possível reduzir essa complexidade.
3.2.2.2 Primeira chamada à função surf_solve
Conforme descrito na Seção 3.2.1, quando todos os processos estão bloqueados, o
módulo SIMIX chama a função surf_solve. Como cada máquina roda apenas 1 tarefa
por vez, essa função aloca todo o poder computacional disponível para a ação que está](https://image.slidesharecdn.com/computacaodistribuidaeboinc2-221017141448-42ed72dd/85/ANALISE-DE-COMPORTAMENTO-NAO-COOPERATIVO-EM-COMPUTACAO-VOLUNTARIA-36-320.jpg)



![40
podemos evitá-lo.
Considere uma CPU qualquer cujo poder computacional no instante t seja denotado
por p(t). Defini-se a quantidade de trabalho realizado num período de tempo como:
P(x) =
Z x
0
p(t).dt.
Considere n ações, A1, . . . , An, rodando nesta CPU, cada uma com a quantidade restante
de trabalho (em MFlop) Ri no instante t0. Em qualquer instante t > t0, cada ação recebe
uma fatia do poder computacional da CPU igual a p(t)/n. Portanto, durante o intervalo
de tempo [a, b], a ação Ai irá avançar em
R b
a
p(t)/n.dt = 1/n
R b
a
p(t).dt.
O valor retornado pela função share_resources é o maior t1 tal que 1/n
R t1
t0
p(t).dt 6
Ri, i.e., t1 é tal que: Z t1
t0
p(t).dt = n min Ri.
Dessa forma, obtém-se o tempo t1 no qual a menor das tarefas terá acabado.
Através da pré-integração do traço, t1 pode ser calculado usando uma simples busca
binária. O tempo necessário para realizar a pré-integração do traço é igual ao tempo de
leitura do mesmo (ao invés de armazenar o traço p, é gravada a integral P como somas
cumulativas dos valores). O custo de encontrar t1 é, portanto, logarítmica no tamanho do
traço.
No exemplo simples de Computação Voluntária analisado, o compartilhamento pre-
cisa ser recalculado apenas para uma máquina a cada chamada à surf_solve e o custo
da função share_resources é, logo, somente Θ(log(T) + log(N)), quando combi-
nado com a melhoria do gerenciamento preguiçoso das ações. Por isso, a complexidade
geral da simulação é Θ(NP(log(N)+log(T))), em vez de Θ(N2
(P +T)) sem nenhuma
melhoria ou Θ(N(P + T) log(N)) com a invalidação parcial do sistema LMM e o geren-
ciamento preguiçoso das ações.
Nota-se que ao contrário das melhorias descritas nas seções anteriores, esta apenas
funciona para os recursos de CPU. Entretanto, ela é fundamental para as simulações de
CV, uma vez que a disponibilidade das máquinas é frequentemente descrita através de
grandes arquivos de traços.
3.2.4 Avaliação de desempenho
Nesta seção são apresentados os resultados de dois diferentes experimentos com o
objetivo de verificar a efetividade das melhorias feitas no núcleo do SimGrid. Na Se-
ção 3.2.4.1 é medido o tempo necessário para uma simulação do exemplo ilustrado na
Seção 3.2.2. Na Seção 3.2.4.2, é apresentado o resultado da comparação de um simula-
dor BOINC implementado com o SimGrid com dois simuladores do BOINC existentes,
o BOINC Client Simulator e o SimBA.
3.2.4.1 Estudo do simples exemplo de aplicação de CV
Para esse estudo foi considerada uma plataforma simples com N máquinas cujos po-
deres de processamento foram retirados de máquinas reais do projeto SETI@home (The
Failure Trace Archive, 2011). No primeiro experimento, as máquinas estão disponíveis
durante todo o tempo de simulação, enquanto no segundo, são usados os arquivos de
disponibilidade do SETI@home. Em cada máquina, um processo worker processa, se-
quencialmente, tarefas cujo tamanho é uniformemente amostrado no intervalo [0, 8.1012
]
(i.e., até um dia de processamento numa máquina padrão).](https://image.slidesharecdn.com/computacaodistribuidaeboinc2-221017141448-42ed72dd/85/ANALISE-DE-COMPORTAMENTO-NAO-COOPERATIVO-EM-COMPUTACAO-VOLUNTARIA-40-320.jpg)



![44
extremamente eficaz e consequentemente mais veloz que o SimGrid.
Comparação com o SimBA
Para os resultados desta seção, configurou-se o SimGrid para que a pilha usada para
simular os processos fosse reduzida do padrão 128KB para 16KB. Essa medida foi ne-
cessária para que a simulação pudesse rodar sem problemas numa máquina com 1GB de
RAM. Os tempos de execução medidos com o SimGrid e aqueles reportados por Estrada
et al. no trabalho (TAUFER et al., 2007) são comparados da seguinte forma:
• O SimBA simulou 15 dias de cálculo com 7810 máquinas trabalhando para o pro-
jeto Predictor@home em 107 minutos. O SimGrid simulou a mesma configuração
em menos de 4 minutos (cada teste foi executado 10 vezes e o intervalo de confiança
de 95% ficou entre [208.13, 223.71] segundos);
• 8 dias de cálculo com 5093 clientes trabalhando para o projeto CHARMM foram
simulados em 44 minutos no simulador SimBA. Já no SimGrid, o teste demorou
menos de 1.5 minutos (cada teste com 10 execuções e intervalo de confiança de 95%
entre [80.38, 80.87] segundos). Nota-se que, em ambos os experimentos, foram
utilizados os traços de disponibilidade do projeto SETI@home e aproximadamente
um terço do tempo de simulação foi gasto para ler esses arquivos.
Normalmente, o esperado seria que o simulador do BOINC implementado sobre o
SimGrid não fosse "muito lento" quando comparado com o SimBA, mas ao contrário
ele foi mais rápido. Isto porque o SimBA opta por diversas soluções simplísticas para
alcançar uma boa escalabilidade, tais como o uso de máquina de estado finito e distribui-
ções estatísticas para simular a disponibilidade das máquinas. Ao contrário, o SimGrid
opta por usar opções mais sofisticadas porém custosas, tais como a execução de código
arbitrário para os processos e o uso de traços reais de disponibilidade. Como resultado,
temos que a construção de um simulador de CV com o SimGrid proporciona a princi-
pal vantagem que é poder ser facilmente programável e estendido. Por exemplo, novas
políticas de escalonamento podem ser implementadas de maneira simples usando a API
MSG. Outra opção é o estudo da comunicação através da ativação de algum modelo de
rede mais complexo. Além disso, seria possível simular diferentes conjuntos de traços de
disponibilidade e verificar o desempenho do sistema. Por fim, o estudo de políticas de
escalonamento do servidor, frente a um cenário com múltiplos projetos e clientes, poderia
ser implementado e realizado.
3.3 Simulador do BOINC proposto
Esta seção descreve as principais decisões tomadas para a criação do simulador do
BOINC proposto, de forma a obter um aplicativo que fosse capaz de simular o comporta-
mento do ambiente de maneira confiável. O código foi desenvolvido em C, utilizando a
API MSG do SimGrid. Composto de aproximadamente 2500 linhas de código, é dividido
em 2 elementos principais: o cliente que é o responsável por representar o funcionamento
dos usuários do BOINC e foi baseado no comportamento descrito em (ANDERSON;
MCLEOD VII, 2007); e o servidor, responsável por distribuir as tarefas ao conjunto de
clientes.
Cliente: As principais funcionalidades do cliente foram implementadas, tais como:](https://image.slidesharecdn.com/computacaodistribuidaeboinc2-221017141448-42ed72dd/85/ANALISE-DE-COMPORTAMENTO-NAO-COOPERATIVO-EM-COMPUTACAO-VOLUNTARIA-44-320.jpg)




![49
4 NOTAÇÃO TEÓRICA DO JOGO
Este capítulo apresenta a notação teórica adotada para modelar os elementos com-
ponentes das plataformas de CV. São modelados os dois principais atores do ambiente,
os servidores dos projetos e os clientes. Além disso, são vistas as estratégias possíveis
aos jogadores e as métricas que são utilizadas para analisar e comparar o desempenho do
sistema.
Um sistema de Computação Voluntária, tal qual o BOINC, consiste de voluntários
que oferecem seus recursos para serem compartilhados entre um conjunto de projetos. Os
mecanismos de escalonamento por trás do sistema devem garantir uma divisão eficiente e
justa dos recursos. Entretanto, diversos parâmetros de configuração do ambiente podem
afetar esse compartilhamento. A seguir, é explicado como esta situação (diversos projetos
compartilhando recursos de clientes) pode ser modelada através do uso de noções de teoria
dos jogos. Primeiramente, são definidos os principais atores do sistema: voluntários e
projetos.
Definição 1 (Voluntário Vj). Um voluntário BOINC é caracterizado pelos seguintes pa-
râmetros:
• Um desempenho máximo (em MFLOP.s−1
) indicando a quantidade de MFLOP
que ele pode processar por segundo quando está disponível;
• Um traço de disponibilidade, i.e., uma sequência ordenada de tempos disjuntos
que indicam quando a máquina de um voluntário está disponível. Esse traço é des-
conhecido pelo escalonador do cliente voluntário, o qual também não usa nenhuma
informação histórica sobre o mesmo para obter um melhor escalonamento;
• A fatia de compartilhamento dos projetos, i.e., a lista de projetos para qual o
voluntário está pronto para trabalhar e qual prioridade foi configurada para cada
projeto.
Uma coleção de voluntários é denotada por V.
Nesta modelagem, os voluntários foram considerados como passivos e apenas prove-
dores de recursos. Mais tarde, será visto como examinar a satisfação dos usuários, porém
neste estudo, eles são considerados completamente passivos.
Define-se, agora, as principais características dos projetos do BOINC.
Definição 2 (Projeto Pi). Um projeto BOINC é caracterizado pelos seguintes parâmetros:
• wi [MFLOP.tarefa−1
] denota o tamanho de uma tarefa, i.e., a quantidade de
MFLOP necessária para realizar uma tarefa. Assume-se que o tamanho da tarefa](https://image.slidesharecdn.com/computacaodistribuidaeboinc2-221017141448-42ed72dd/85/ANALISE-DE-COMPORTAMENTO-NAO-COOPERATIVO-EM-COMPUTACAO-VOLUNTARIA-49-320.jpg)
![50
do Pi é uniforme. Claramente, isto é uma aproximação, porém ela geralmente se
mantém verdadeira para muitos projetos numa escala de tempo de algumas sema-
nas 1
;
• bi [tarefa.lote−1
] denota o número de tarefas de cada lote. Novamente, assume-
se que todos os lotes possuem o mesmo tamanho. Essa aproximação pode não ser
realística para projetos do tipo GridBOT (SILBERSTEIN et al., 2009). Contudo,
consideramos que essa abordagem é razoável neste primeiro estudo. Ainda, como
não estamos interessados em como um determinado projeto pode priorizar suas
rajadas, ela não deve afetar nossas conclusões;
• ri [lote.dia−1
] denota a taxa de entrada, i.e., o número de lotes de tarefas por dia.
Mais um vez, assume-se este valor como fixo e não são considerados os potenci-
ais períodos sem tarefas que podem acontecer na escala de semanas ou meses de
simulação.
Ainda, considera-se que ri, bi e wi são tais que não saturam completamente o sis-
tema, isto é, tais que um lote sempre termine antes da submissão de um novo. De
fato, como foi explicado anteriormente, não estamos interessados como um de-
terminado projeto pode priorizar seus lotes, mas sim, como os diferentes projetos
podem interferir uns aos outros. Logo, os pressupostos acima não devem ser preju-
diciais nesse contexto;
• Obji é a função objetiva do projeto. Dependendo da natureza de cada projeto, ela
pode ser o throughput %i, i.e., o número médio de tarefas processadas por dia, ou
o tempo médio de término de um lote αi;
• qi é o quorum, i.e., o número de resultados processados com sucesso que precisam
ser retornados ao servidor antes que a tarefa possa ser considerada válida. Nos
nossos experimentos, foi assumido que o qi é sempre igual a 1 tarefa.
Um projeto Pi é portanto uma tupla (wi, bi, ri, Obji) e uma instância do sistema é, logo,
uma coleção de projetos P = (P1, . . . , PK). O conjunto de todas essas possibilidades de
instâncias de projetos é denotado por P.
Usando a terminologia da teoria dos jogos, os projetos serão referidos como jogado-
res. Na mesma linha, o termo estratégia é usado para se referir ao conjunto de opções
de "jogadas" que os jogadores possuem e que podem influenciar o compartilhamento dos
recursos disponíveis.
Definição 3 (Estratégia Si). O servidor de cada projeto pode ser configurado com valo-
res específicos que influenciam diretamente seu desempenho. Neste estudo, foca-se nos
seguintes parâmetros:
• πi é a política de envio de tarefas (KONDO; ANDERSON; MCLEOD, 2007)
usada pelo servidor quando da recepção de uma requisição de trabalho. Quando
um cliente conecta-se ao servidor, ele demanda por tarefas suficientes para mantê-
lo ocupado por um período de tempo determinado (e.g., um dia). Então, o servidor
é responsável por determinar quantas e quais tarefas serão enviadas.
1
http://www.boinc-wiki.info/Catalog_of_BOINC_Powered_Projects](https://image.slidesharecdn.com/computacaodistribuidaeboinc2-221017141448-42ed72dd/85/ANALISE-DE-COMPORTAMENTO-NAO-COOPERATIVO-EM-COMPUTACAO-VOLUNTARIA-50-320.jpg)















![66
1
1.5
2
2.5
3
3.5
1 1.5 2 2.5 3 3.5
Deadline − Base
Deadline
−
Tendência
da melhor resposta
Trajetória
convergente
da melhor resposta
Trajetória
cíclica
Equilíbrio de Nash
Pontos de começo arbitrários
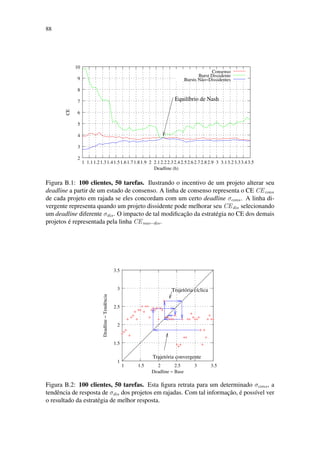
Figura 5.15: Esta figura retrata para um determinado σcons, a tendência de resposta de σdis
dos projetos em rajadas. Com tal informação, é possível ver o resultado da estratégia de
melhor resposta.
Consequentemente, os outros projetos tendem a abandonar seu σcons = 1.15 e mudar
para uma melhor posição também. Interessantemente, as 3 curvas se encontram no ponto
σi = 2.45, o qual é, portanto, o equilíbrio de Nash desse ambiente.
A Figura 5.15 retrata para um dado σcons, o correspondente σdis que leva para um me-
lhor CEdis. Logo, se todos os projetos usam uma estratégia simples de melhor resposta,
podemos seguir a dinâmica do sistema e verificar para onde ele converge. No caso da
posição inicial ser σinit ∈ [1.8, 2.45], vemos que ele converge para o equilíbrio de Nash
σNE = 2.45, o qual causa um CENE = 60.7 para todos os projetos em rajadas. Ainda,
podemos ler na Figura 5.16 que uma escolha comum de σcons = 1.15 (veja o ponto de
referência indicado na figura) levaria a um CEcons = 71.3 CENE.
Ainda, poderia acontecer que essa perda de eficiência para os projetos em rajadas
beneficiasse os projetos contínuos. Infelizmente, não é o que acontece já que podemos,
facilmente, verificar que os resultados dos projetos contínuos são piores. Para isto, basta
analisar o outcome de tais situações no espaço de utilidade ilustrado na Figura 5.16.
Com tal representação, podemos confirmar que o equilíbrio de Nash é Pareto-ineficiente
e que o CE pode ser melhorado em mais de 10% para os projetos se todos, colaborativa-
mente, escolhessem σcons = 1.15.
Tais ineficiências, como as vistas anteriormente, podem ser observadas em diversas
configurações e o conjunto de utilidade sempre possui, mais ou menos, a mesma estru-
tura. Por exemplo, quando usamos uma configuração um pouco diferente, composta de
8 projetos, dos quais 7 são projetos em rajadas recebendo lotes de 600 tarefas de 1 hora
por dia, obtém-se um equilíbrio de Nash ineficiente (veja a Figura 5.19). Note que nesse
exemplo, o projeto contínuo possui tarefas de 30 horas com prazo de término de 300
horas, como já dito, é uma configuração típica do projeto SETI@home. Mais algumas
configurações, variando-se o número de clientes utilizados são apresentadas no Apêndice
B.
Analisando a Figura 5.17, vemos que os projetos em rajadas têm um grande incentivo
de modificar seu slack quando o CE atinge o ponto de maior valor (1.25) (veja o CEdis
na figura). Ainda, analisando a Figura 5.18 que retrata a convergência das estratégias](https://image.slidesharecdn.com/computacaodistribuidaeboinc2-221017141448-42ed72dd/85/ANALISE-DE-COMPORTAMENTO-NAO-COOPERATIVO-EM-COMPUTACAO-VOLUNTARIA-66-320.jpg)








![75
REFERÊNCIAS
ANDERSON, D. P. BOINC: a system for public-resource computing and storage. In:
IEEE/ACM INTL. WORKSHOP ON GRID COMPUTING, 5., 2004. Proceedings...
[S.l.: s.n.], 2004.
ANDERSON, D. P.; COBB, J.; KORPELA, E.; LEBOFSKY, M.; WERTHIMER, D.
SETI@home: an experiment in public-resource computing. Commun. ACM, New York,
NY, USA, v.45, n.11, 2002.
ANDERSON, D. P.; MCLEOD VII, J. Local Scheduling for Volunteer Computing. In:
INTL. PARALLEL AND DISTRIBUTED PROCESSING SYMP. (IPDPS 2007), 2007.
Proceedings... IEEE Intl., 2007.
ANDERSON, D. P.; REED, K. Celebrating Diversity in Volunteer Computing. In: SYS-
TEM SCIENCES, 2009. HICSS ’09. 42ND HAWAII, 2009. Anais... [S.l.: s.n.], 2009.
BARISITS, M.; BOYD, W. MartinWilSim Grid Simulator. 2009. Summer Internship
— Vienna UT and Georgia Tech, CERN, Switzerland. Disponível em: http://www.
slideshare.net/wbinventor/slides-1884876. Acesso em: 10 ago. 2010.
BERTSEKAS, D.; GALLAGER, R. Data Networks. [S.l.]: Prentice-Hall, 1992.
BRAESS, D. Über ein Paradoxen aus der Verkehrsplanung. Unternehmensforschung,
[S.l.], v.12, p.258–268, 1968.
BUYYA, R.; MURSHED, M. GridSim: a toolkit for the modeling and simulation of
distributed resource management and scheduling for grid computing. Concurrency and
Computation: Practice and Experience, [S.l.], v.14, n.13-15, 2002.
CAPPELLO, F.; DJILALI, S.; FEDAK, G.; HERAULT, T.; MAGNIETTE, F.; NERI, V.;
LODYGENSKY, O. Computing on Large Scale Distributed Systems: xtremweb architec-
ture, programming models, security, tests and convergence with grid. Future Generation
Computer Systems, [S.l.], v.21, n.3, 2004.
CAPPELLO, F.; FEDAK, G.; KONDO, D.; MALéCOT, P.; REZMERITA, A. Handbook
of Research on Scalable Computing Technologies. [S.l.]: IGI Global, 2009.
CASANOVA, H. Simgrid: a toolkit for the simulation of application scheduling. In:
IEEE/ACM INTL. SYMP. ON CLUSTER COMPUTING AND THE GRID (CCGRID),
1., 2001. Proceedings... [S.l.: s.n.], 2001.](https://image.slidesharecdn.com/computacaodistribuidaeboinc2-221017141448-42ed72dd/85/ANALISE-DE-COMPORTAMENTO-NAO-COOPERATIVO-EM-COMPUTACAO-VOLUNTARIA-75-320.jpg)
![76
CASANOVA, H.; LEGRAND, A.; QUINSON, M. SimGrid: a generic framework for
large-scale distributed experiments. In: IEEE INTL. CONF. ON COMPUTER MODE-
LING AND SIMULATION, 10., 2008. Proceedings... [S.l.: s.n.], 2008.
CHIEN, A.; CALDER, B.; ELBERT, S.; BHATIA, K. Entropia: architecture and per-
formance of an enterprise desktop grid system. Journal of Parallel and Distributed
Computing, [S.l.], v.63, p.597–610, 2003.
CHOI, S.; KIM, H.; BYUN, E.; BAIK, M.; KIM, S.; PARK, C.; HWANG, C. Charac-
terizing and Classifying Desktop Grid. In: CLUSTER COMPUTING AND THE GRID,
2007. CCGRID 2007. SEVENTH IEEE INTERNATIONAL SYMPOSIUM ON, 2007.
Anais... [S.l.: s.n.], 2007. p.743 –748.
DEPOORTER, W.; MOOR, N.; VANMECHELEN, K.; BROECKHOVE, J. Scalability
of Grid Simulators: an evaluation. In: INTL. EURO-PAR CONF. ON PARALLEL PRO-
CESSING, 14., 2008. Proceedings... [S.l.: s.n.], 2008.
ESTRADA, T.; FLORES, D. A.; TAUFER, M.; TELLER, P. J.; KERSTENS, A.; AN-
DERSON, D. P. The Effectiveness of Threshold-Based Scheduling Policies in BOINC
Projects. In: SECOND IEEE INTL. CONF. ON E-SCIENCE AND GRID COMPUTING
(E-SCIENCE), 2006. Proceedings... [S.l.: s.n.], 2006.
ESTRADA, T.; TAUFER, M.; ANDERSON, D. Performance Prediction and Analysis of
BOINC Projects: an empirical study with emboinc. Journal of Grid Computing, [S.l.],
v.7, p.537–554, 2009.
ESTRADA, T.; TAUFER, M.; REED, K.; ANDERSON, D. P. EmBOINC: an emulator
for performance analysis of boinc projects. In: WORKSHOP ON DESKTOP GRIDS
AND VOLUNTEER COMPUTING SYSTEMS (PCGRID), 3., 2009. Proceedings...
[S.l.: s.n.], 2009.
FOSTER, I.; KESSELMAN, C.; TUECKE, S. The Anatomy of the Grid: enabling scala-
ble virtual organizations. Lecture Notes in Computer Science, [S.l.], v.2150, 2001.
HEIEN, E.; ANDERSON, D.; HAGIHARA, K. Computing Low Latency Batches with
Unreliable Workers in Volunteer Computing Environments. Journal of Grid Computing,
[S.l.], v.7, p.501–518, 2009.
HEIEN, E. M.; FUJIMOTO, N.; HAGIHARA, K. Computing low latency batches with
unreliable workers in volunteer computing environments. In: INTL. PARALLEL AND
DISTRIBUTED PROCESSING SYMP. (IPDPS), 2008. Proceedings... [S.l.: s.n.], 2008.
KONDO, D. SimBOINC: a simulator for desktop grids and volunteer computing sys-
tems. Acessado em Novembro 2010., http://simboinc.gforge.inria.fr/.
KONDO, D.; ANDERSON, D. P.; MCLEOD, J. V. Performance Evaluation of Sche-
duling Policies for Volunteer Computing. In: IEEE INTERNATIONAL CONFERENCE
ON E-SCIENCE AND GRID COMPUTING E-SCIENCE’07, 3., 2007, Bangalore, India.
Proceedings... [S.l.: s.n.], 2007.](https://image.slidesharecdn.com/computacaodistribuidaeboinc2-221017141448-42ed72dd/85/ANALISE-DE-COMPORTAMENTO-NAO-COOPERATIVO-EM-COMPUTACAO-VOLUNTARIA-76-320.jpg)
![77
KONDO, D.; ARAUJO, F.; MALECOT, P.; DOMINGUES, P.; SILVA, L.; FEDAK, G.;
CAPPELLO, F. Characterizing Result Errors in Internet Desktop Grids. In: KERMAR-
REC, A.-M.; BOUGé, L.; PRIOL, T. (Ed.). Euro-Par 2007 Parallel Processing. [S.l.]:
Springer Berlin / Heidelberg, 2007. p.361–371. (Lecture Notes in Computer Science,
v.4641).
KONDO, D.; CHIEN, A. A.; CASANOVA, H. Scheduling Task Parallel Applications for
Rapid Application Turnaround on Enterprise Desktop Grids. Journal of Grid Compu-
ting, [S.l.], v.5, n.4, 2007.
KONDO, D.; FEDAK, G.; CAPPELLO, F.; CHIEN, A. A.; CASANOVA, H. Characteri-
zing Resource Availability in Enterprise Desktop Grids. Journal of Future Generation
Computer Systems, [S.l.], v.23, n.7, 2007.
KONDO, D.; JAVADI, B.; IOSUP, A.; EPEMA, D. The Failure Trace Archive: ena-
bling comparative analysis of failures in diverse distributed systems. In: IEEE INT.
SYMP. ON CLUSTER COMPUTING AND THE GRID (CCGRID), 2010. Procee-
dings... [S.l.: s.n.], 2010.
KONDO, D.; TAUFER, M.; BROOKS, C.; CASANOVA, H.; CHIEN, A. A. Characte-
rizing and Evaluating Desktop Grids: an empirical study. In: INTL. PARALLEL AND
DISTRIBUTED PROCESSING SYMP. (IPDPS), 2004. Proceedings... [S.l.: s.n.], 2004.
LEGRAND, A.; TOUATI, C. How to measure efficiency? In: INTERNATIONAL
WORKSHOP ON GAME THEORY FOR COMMUNICATION NETWORKS (GAME-
COMM’07), 1., 2007. Proceedings... [S.l.: s.n.], 2007.
LEGRAND, A.; TOUATI, C. Non-Cooperative Scheduling of Multiple Bag-of-Task
Appplications. In: CONFERENCE ON COMPUTER COMMUNICATIONS (INFO-
COM’07), 25., 2007, Alaska, USA. Proceedings... [S.l.: s.n.], 2007.
LOW, S. H. A Duality Model of TCP and Queue Management Algorithms. IEEE/ACM
Transactions on Networking, [S.l.], v.11, n.4, 2003.
LUCE, R. D.; RAIFFA, H. Games and decisions : introduction and critical survey. [S.l.]:
Wiley, New York :, 1957. 509 p. :p.
MOWBRAY, M.; BRASILEIRO, F.; ANDRADE, N.; SANTANA, J.; CIRNE, W. A
Reciprocation-Based Economy for Multiple Services in Peer-to-Peer Grids. In: SIXTH
IEEE INTL. CONF. ON PEER-TO-PEER COMPUTING (P2P), 2006, Washington, DC,
USA. Proceedings... IEEE Computer Society, 2006.
MYERSON, R. B. Game theory: analysis of conflict. [S.l.]: Harvard University Press,
1997.
NAICKEN, S.; BASU, A.; LIVINGSTON, B.; RODHETBHAI, S. Towards Yet Another
Peer-to-Peer Simulator. In: HET-NETS, 2006. Proceedings... [S.l.: s.n.], 2006.
NASH, J. Equilibrium Points in N-Person Games. Proceedings of the National Aca-
demy of Sciences, [S.l.], v.36, n.1, p.48–49, 1950.
NASH, J. Non-Cooperative Games. The Annals of Mathematics, [S.l.], v.54, n.2, p.286–
295, 1951.](https://image.slidesharecdn.com/computacaodistribuidaeboinc2-221017141448-42ed72dd/85/ANALISE-DE-COMPORTAMENTO-NAO-COOPERATIVO-EM-COMPUTACAO-VOLUNTARIA-77-320.jpg)
![78
NISAN, N.; ROUGHGARDEN, T.; TARDOS, E.; VAZIRANI, V. V. Algorithmic Game
Theory. New York, NY, USA: Cambridge University Press, 2007.
NURMI, D.; BREVIK, J.; WOLSKI, R. Modeling Machine Availability in Enterprise
and Wide-area Distributed Computing Environments. In: INTL. EURO-PAR CONF. ON
PARALLEL PROCESSING, 2005. Proceedings... [S.l.: s.n.], 2005.
RILEY, G. F. The Georgia Tech Network Simulator. In: ACM SIGCOMM WORKSHOP
ON MODELS, METHODS AND TOOLS FOR REPRODUCIBLE NETWORK RESE-
ARCH, 2003. Proceedings... [S.l.: s.n.], 2003.
ROUGHGARDEN, T. Selfish Routing and the Price of Anarchy. [S.l.]: The MIT Press,
2005.
SANTOS-NETO, E.; CIRNE, W.; BRASILEIRO, F.; LIMA, A. Exploiting Replica-
tion and Data Reuse to Efficiently Schedule Data-Intensive Applications on Grids. In:
WORKSHOP ON JOB SCHEDULER STRATEGIES FOR PARALLEL PROCESSORS
(JSSPP), 2004. Proceedings... [S.l.: s.n.], 2004.
SHOCH, J. F.; HUPP, J. A. The wormprograms—early experience with a distributed
computation. Commun. ACM, New York, NY, USA, v.25, p.172–180, March 1982.
SILBERSTEIN, M.; SHAROV, A.; GEIGER, D.; SCHUSTER, A. GridBot: execution of
bags of tasks in multiple grids. In: CONFERENCE ON HIGH PERFORMANCE COM-
PUTING NETWORKING, STORAGE AND ANALYSIS, 2009, New York, NY, USA.
Proceedings... ACM, 2009. (SC ’09).
SILVA, F. A. B. da; SENGER, H. Improving scalability of Bag-of-Tasks applications
running on master-slave platforms. Parallel Computing, Amsterdam, The Netherlands,
The Netherlands, v.35, n.2, 2009.
STAINFORTH, D.; KETTLEBOROUGH, J.; ALLEN, M.; COLLINS, M.; HEAPS, A.;
MURPHY, J. Distributed computing for public-interest climate modeling research. Com-
puting in Science Engineering, [S.l.], v.4, n.3, p.82 –89, 2002.
STAINFORTH, D.; KETTLEBOROUGH, J.; MARTIN, A.; SIMPSON, A.; GILLIS, R.;
AKKAS, A.; GAULT, R.; COLLINS, M.; GAVAGHAN, D.; ALLEN, M. Climatepredic-
tion.net: design principles for public-resource modeling research. In: IN 14TH IASTED
INTERNATIONAL CONFERENCE PARALLEL AND DISTRIBUTED COMPUTING
AND SYSTEMS, 2002. Anais... [S.l.: s.n.], 2002. p.32–38.
STERLING, T.; BECKER, D. J.; SAVARESE, D.; DORBAND, J. E.; RANAWAKE,
U. A.; PACKER, C. V. BEOWULF: a parallel workstation for scientific computation. In:
IN PROCEEDINGS OF THE 24TH INTERNATIONAL CONFERENCE ON PARAL-
LEL PROCESSING, 1995. Anais... CRC Press, 1995. p.11–14.
TAUFER, M.; KERSTENS, A.; ESTRADA, T.; FLORES, D.; TELLER, P. J. SimBA: a
discrete event simulator for performance prediction of volunteer computing projects. In:
INTL. WORKSHOP ON PRINCIPLES OF ADVANCED AND DISTRIBUTED SIMU-
LATION (PADS), 21., 2007. Proceedings... [S.l.: s.n.], 2007.](https://image.slidesharecdn.com/computacaodistribuidaeboinc2-221017141448-42ed72dd/85/ANALISE-DE-COMPORTAMENTO-NAO-COOPERATIVO-EM-COMPUTACAO-VOLUNTARIA-78-320.jpg)
![79
THAIN, D.; TANNENBAUM, T.; LIVNY, M. Condor and the Grid. In: BERMAN, F.;
FOX, G.; HEY, T. (Ed.). Grid Computing: making the global infrastructure a reality.
[S.l.]: John Wiley Sons Inc., 2002.
The Failure Trace Archive. Acessado em Janeiro 2010., http://fta.inria.fr.
The SimGrid project. Acessado em Novembro 2010., http://simgrid.gforge.
inria.fr.
VELHO, P.; LEGRAND, A. Accuracy Study and Improvement of Network Simulation in
the SimGrid Framework. In: INTL. CONF. ON SIMULATION TOOLS AND TECHNI-
QUES (SIMUTOOLS), 2., 2009. Proceedings... [S.l.: s.n.], 2009.](https://image.slidesharecdn.com/computacaodistribuidaeboinc2-221017141448-42ed72dd/85/ANALISE-DE-COMPORTAMENTO-NAO-COOPERATIVO-EM-COMPUTACAO-VOLUNTARIA-79-320.jpg)












Este documento apresenta uma dissertação de mestrado sobre análise do comportamento não cooperativo em computação voluntária. A dissertação propõe um simulador para a plataforma BOINC usando o SimGrid e realiza experimentos para estudar o equilíbrio de Nash em projetos de computação voluntária.















































