Baixado 47 vezes



































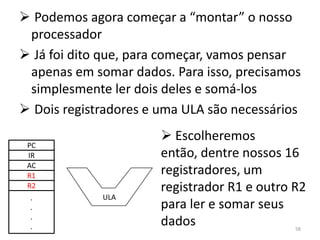
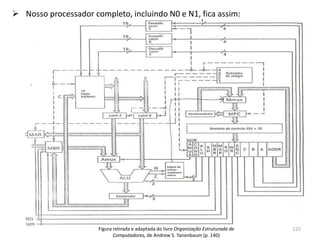
![ O Program Counter contém o endereço da
próxima instrução a ser buscada na memória
principal
O Instruction Register armazena a instrução
buscada na memória. Ou seja, IR = MP[pc],
sendo IR o conteúdo do registrador e pc um
endereço da memória principal MP
Accumulator é um registrador que armazena
valores intermediários, que não seriam úteis ao
final da operação
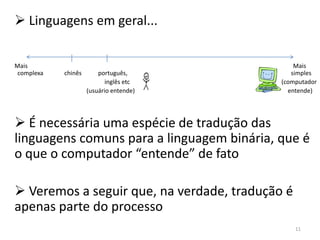
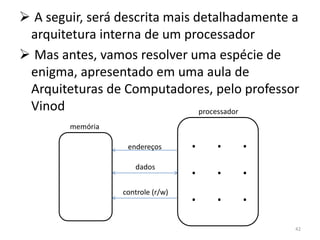
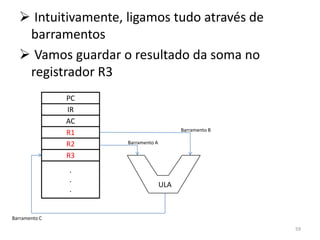
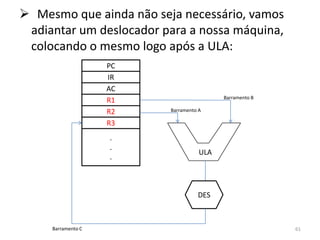
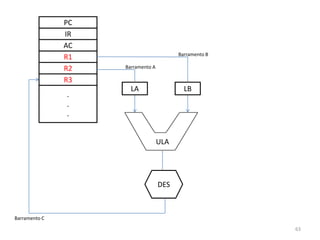
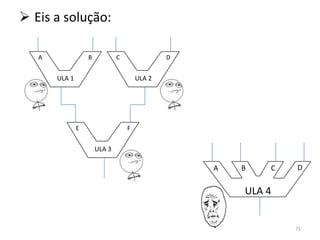
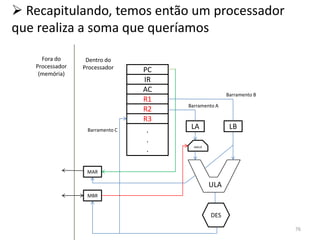
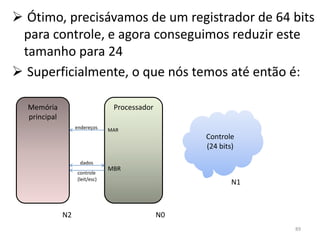
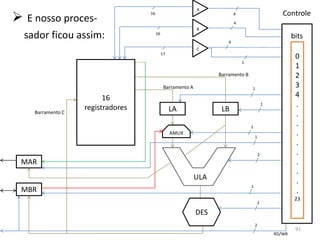
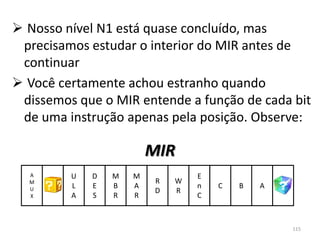
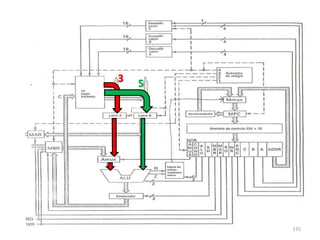
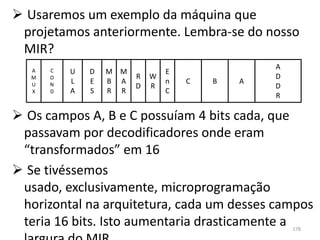
Haverá em nossa arquitetura, além dos 16,
outros registradores espalhados no processador:
dois latches, A e B, o Memory Adress Register
(MAR) e o Memory Buffer Register (MBR) 55](https://image.slidesharecdn.com/arquiteturasdecomputadores-slides-111125200837-phpapp02/85/Arquiteturas-de-computadores-slides-55-320.jpg)

























































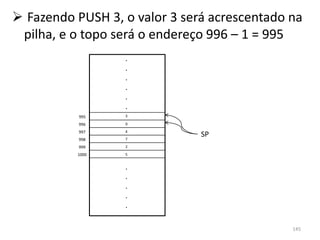
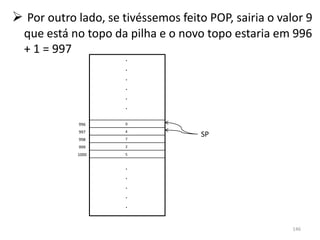









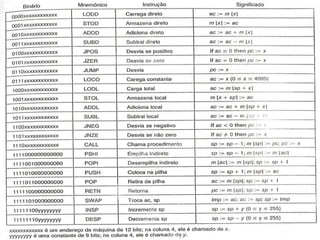





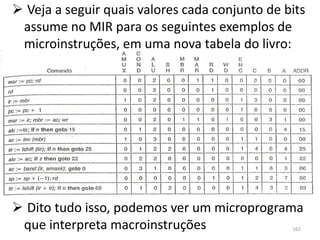






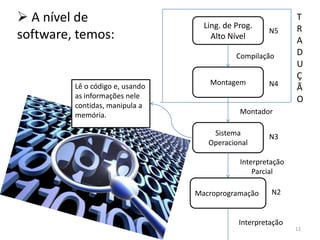
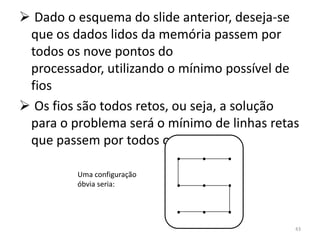
![se (i ≤ j) faça // ‘i’ e ‘j’ são variáveis quaisquer
m = a[i*2] // ‘a’ é um vetor e ‘m’ uma variável
// qualquer
fim se
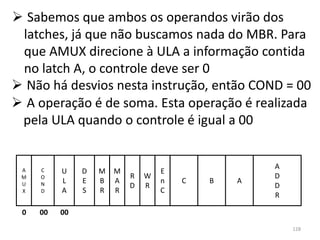
Vamos expressar este algoritmo em nível de
macroprogramação, e depois em microinstruções,
para enfim nos despedirmos
da nossa máquina-exemplo
170](https://image.slidesharecdn.com/arquiteturasdecomputadores-slides-111125200837-phpapp02/85/Arquiteturas-de-computadores-slides-170-320.jpg)
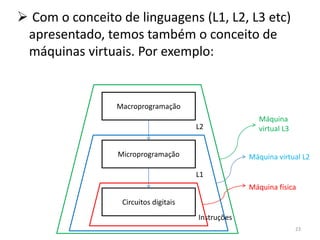
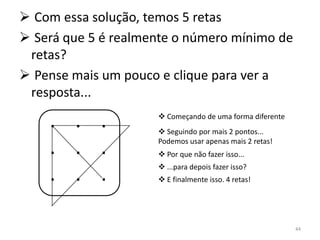
![ Serão realizadas 4 operações nesse algoritmo: Macroprograma
i ≤ j?
i*2 LODD j
buscar valor em a[i * 2] SUBD i
m := a[i * 2] JNEG saida
Testar se i ≤ j é o mesmo que testar se i - j ≤ 0
Atenção: ‘i’ e ‘j’ são variáveis globais
Com a instrução LODD passando j (entenda as
variáveis passadas no macroprograma como o
endereço onde essas variáveis estão, e não seus
respectivos valores), armazenamos no
registrador AC o valor contido no endereço saida (continuação
passado do programa)
.
Precisamos agora subtrair do valor de i. Com a .
.
instrução SUBD, o resultado já será armazenado .
em AC
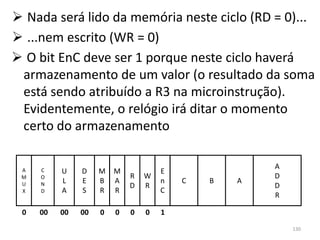
Hora de implementar o desvio condicional:
caso o conteúdo de AC seja negativo (j > i),
desviamos para o final do ‘se’ do algoritmo. Para
isso, criaremos um label “saida” 171](https://image.slidesharecdn.com/arquiteturasdecomputadores-slides-111125200837-phpapp02/85/Arquiteturas-de-computadores-slides-171-320.jpg)
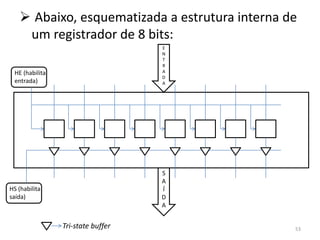
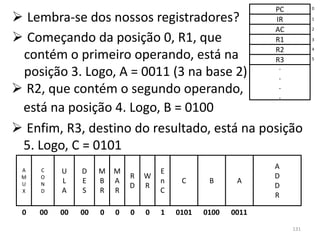
![ Agora, carregamos o endereço do primeiro
Macroprograma
elemento do vetor a no registrador AC. Se LODD j
fizéssemos LODD a, teríamos o valor de a[0] no SUBD i
acumulador, e não é o que queremos JNEG saida
Quisemos o endereço de a[0] porque assim LOCO a
podemos encontrar a[i * 2]. Já que i * 2 = i + ADDD i
i, fazemos 0 + i... ADDD i
...+ i, e temos em AC o endereço correto do PSHI
(i * 2)-ésimo elemento do vetor a POP
Aqui vem o problema: queremos fazer STOD m
ac := m[ac], mas não temos uma instrução que o saida (continuação
faça. Temos como fazer, porém, m[sp] := m[ac], do programa)
isto é, colocar na pilha de execução o valor .
.
contido no endereço presente em AC .
.
...e depois armazenar este valor em AC .
.
(ac := m[sp])
Finalmente, armazenar o valor de AC no
endereço da memória onde está a variável m
172](https://image.slidesharecdn.com/arquiteturasdecomputadores-slides-111125200837-phpapp02/85/Arquiteturas-de-computadores-slides-172-320.jpg)

![mar := &i; rd; //MAR recebe o endereço da variável i
rd; //esperando o valor de i chegar até MBR
b := mbr; //B é um dos resgistradores sem função definida
mar := &j; rd;
ac := b + 1; rd; //armazenando i + 1 em AC. Falta somar com j
a := inv(mbr); //valor de j chegou ao MBR. A recebe o inverso
ac := ac + a; if n goto faça; //se i + j + 1 < 0, não saia do algoritmo
alu := ac; if z goto faça; //se essa soma for igual a 0, também não saia
goto saida;
faça b := lshift(b); //multiplicando por 2 o conteúdo de B
ac := &a; //AC recebe o endereço de a[0]
ac := ac + b; //AC recebe o endereço de a[i*2]
mar := ac; rd; //lendo na memória o valor que está em a[i*2]
rd;
mar := &m; wr; //escreve na variável m o que acabou de ser lido
wr;
saida ... //aqui está o que vem após o ‘fim se’ no programa
174](https://image.slidesharecdn.com/arquiteturasdecomputadores-slides-111125200837-phpapp02/85/Arquiteturas-de-computadores-slides-174-320.jpg)
![ Há apenas uma última observação. Analise estas
últimas linhas do microprograma anterior:
mar := ac; rd;
rd;
mar := &m; wr;
wr;
Implicitamente, o que temos é:
mar := ac; rd;
rd;
ac := mbr;
mar := &m; wr;
mbr := ac; wr;
O acumulador recebe o que foi lido da memória (valor
em a[i*2]). Em seguida, indicamos que estamos visando
o endereço da variável m para escrita, fazemos o MBR
receber o valor em AC e escrevemos esse valor no
endereço onde está m 175](https://image.slidesharecdn.com/arquiteturasdecomputadores-slides-111125200837-phpapp02/85/Arquiteturas-de-computadores-slides-175-320.jpg)



























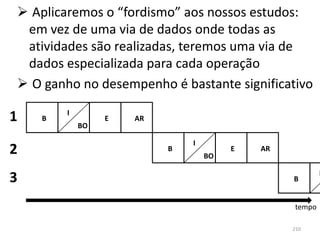



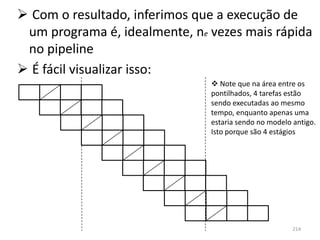

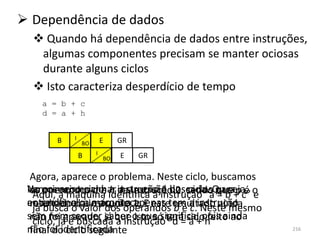
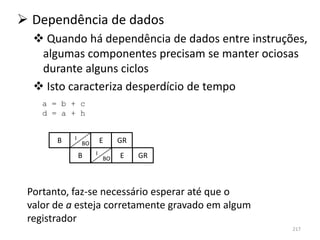

























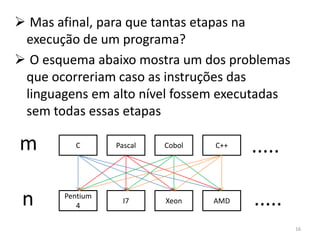
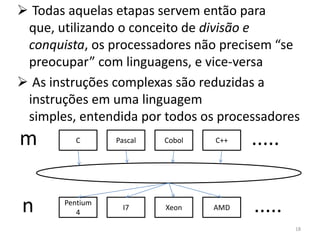
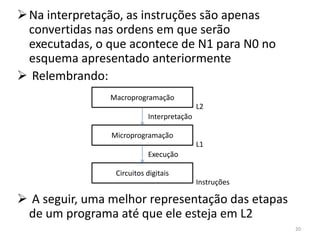
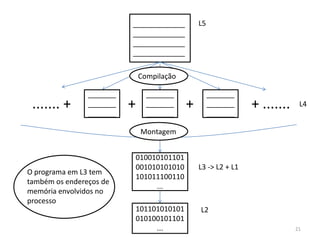
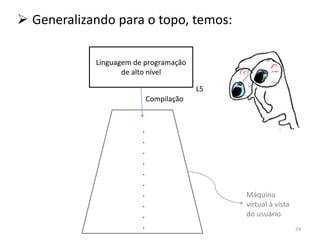
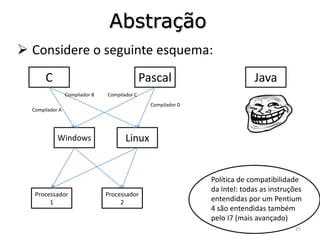
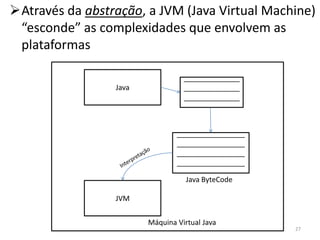
1) O documento discute arquiteturas de computadores e como os programas são executados nos computadores. 2) São descritas as etapas de tradução e interpretação de programas, desde linguagens de alto nível até a linguagem de máquina. 3) As muitas etapas servem para que programas em diferentes linguagens possam rodar em diferentes processadores de forma independente, reduzindo a complexidade.

































