Baixado 77 vezes









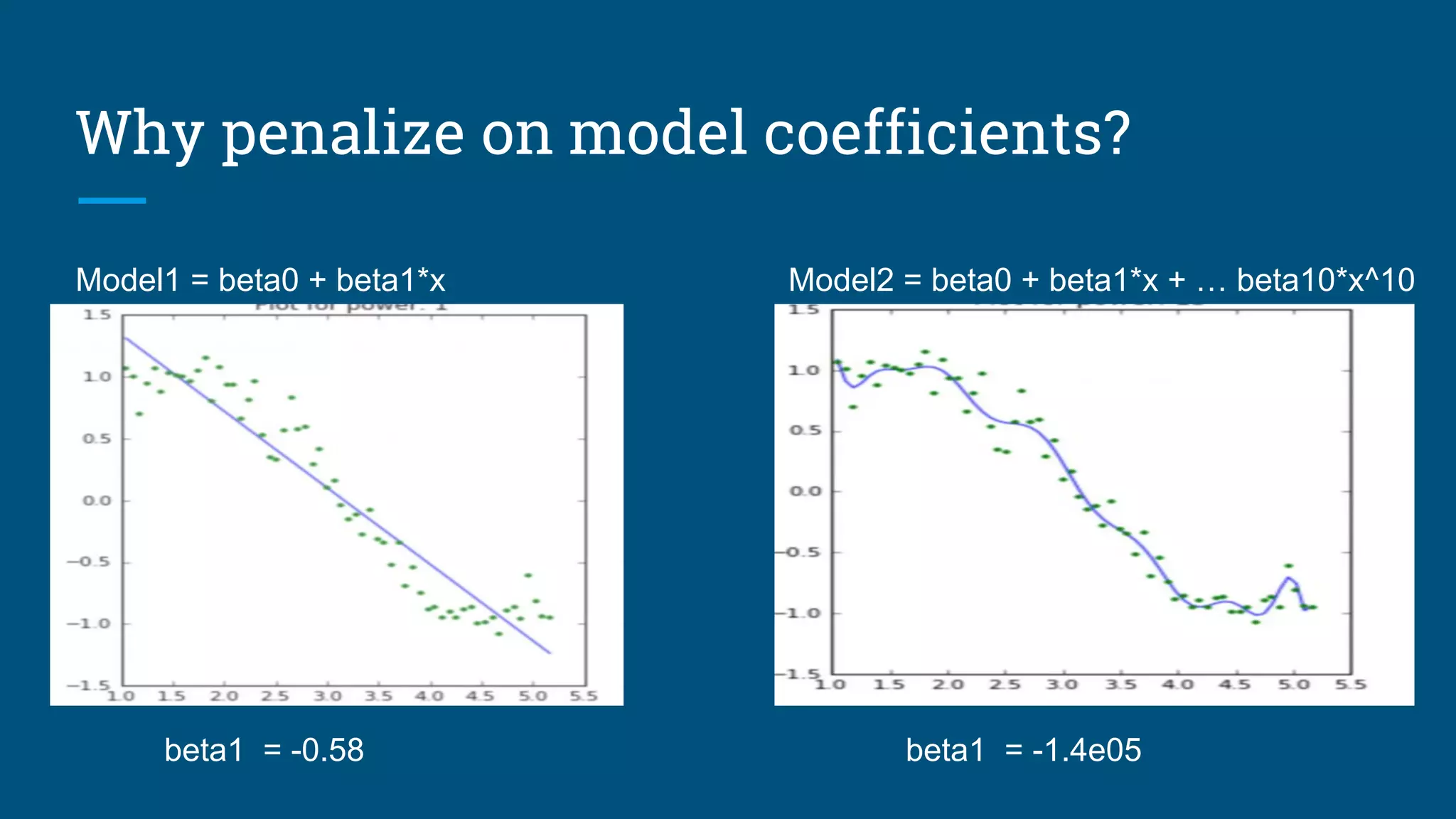



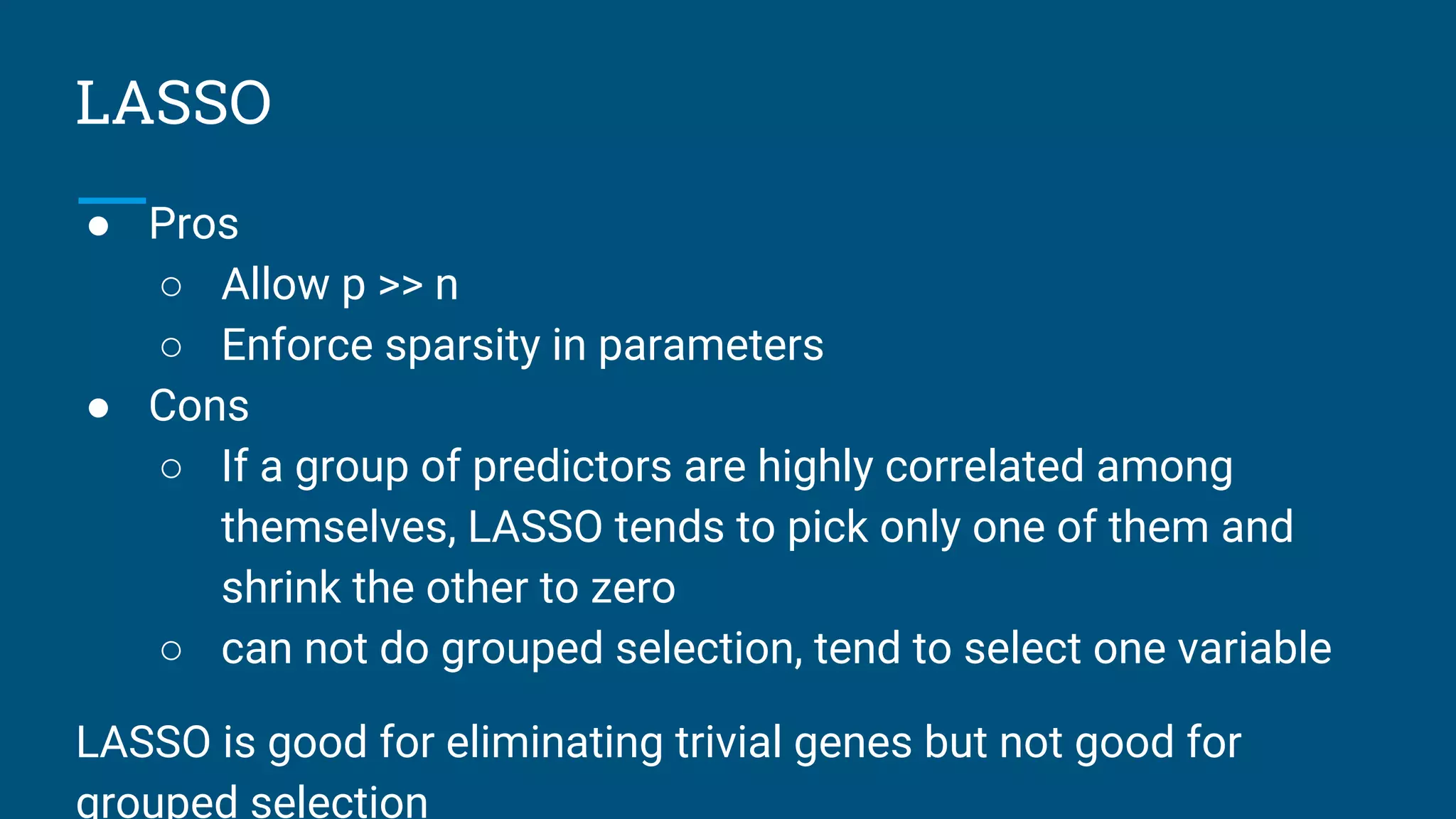


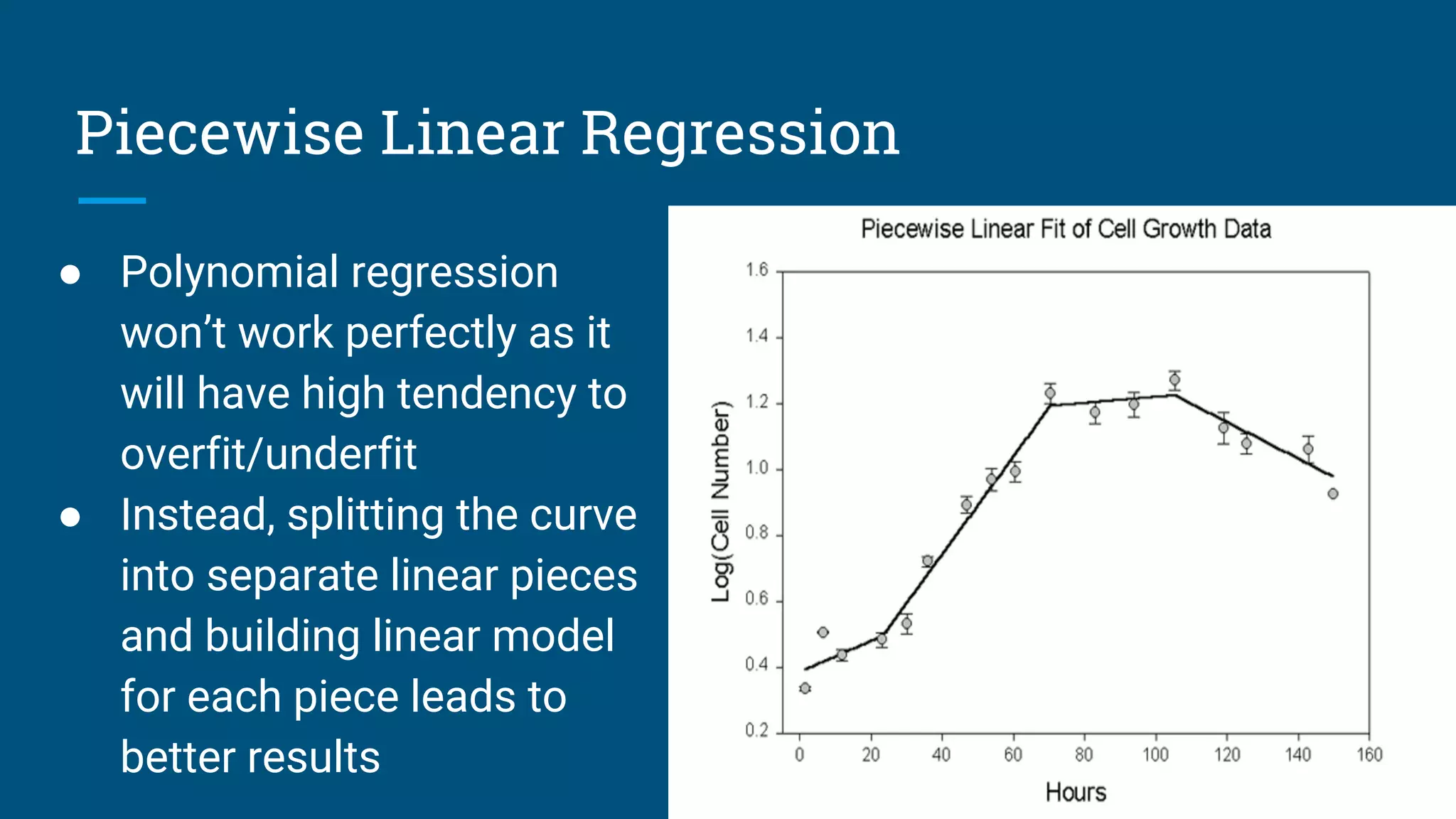


The document discusses various machine learning algorithms and model selection techniques, highlighting the advantages and disadvantages of each method, including Naive Bayes, logistic regression, decision trees, and SVM. It also covers advanced regression issues and regularization techniques, detailing ridge and lasso regression's pros and cons along with their applications in gene selection problems. Lastly, it introduces additional methods such as Poisson regression and piecewise linear regression for specific types of data.










































































