Enviar pesquisa
Carregar
Hdfs write
•
Transferir como PPT, PDF
•
0 gostou
•
796 visualizações
wyukawa
Seguir
Denunciar
Compartilhar
Denunciar
Compartilhar
1 de 1
Baixar agora
Recomendados
Big Data Services in Danaos Use Case
Big Data Seervices in Danaos Use Case
Big Data Seervices in Danaos Use Case
Big Data Value Association
SHAKAS TECHNOLOGIES
Decentralized access control with anonymous authentication of data stored in ...
Decentralized access control with anonymous authentication of data stored in ...
Vasanth Mca
HCL CDC Velachery 9382207007, 9443558751
IEEE paper 2014 abstract
IEEE paper 2014 abstract
Senthilvel S
Keynote talk at the International Conference on Supercoming 2009, at IBM Yorktown in New York. This is a major update of a talk first given in New Zealand last January. The abstract follows. The past decade has seen increasingly ambitious and successful methods for outsourcing computing. Approaches such as utility computing, on-demand computing, grid computing, software as a service, and cloud computing all seek to free computer applications from the limiting confines of a single computer. Software that thus runs "outside the box" can be more powerful (think Google, TeraGrid), dynamic (think Animoto, caBIG), and collaborative (think FaceBook, myExperiment). It can also be cheaper, due to economies of scale in hardware and software. The combination of new functionality and new economics inspires new applications, reduces barriers to entry for application providers, and in general disrupts the computing ecosystem. I discuss the new applications that outside-the-box computing enables, in both business and science, and the hardware and software architectures that make these new applications possible.
Computing Outside The Box June 2009
Computing Outside The Box June 2009
Ian Foster
상세 설명: https://event.openinfradays.kr/2018/session1/track_4_0
[OpenInfra Days Korea 2018] (Track 4) CloudEvents 소개 - 상호 운용 가능성을 극대화한 이벤트 데이...
[OpenInfra Days Korea 2018] (Track 4) CloudEvents 소개 - 상호 운용 가능성을 극대화한 이벤트 데이...
OpenStack Korea Community
NYC* Tech Day - New Cassandra Drivers in Depth
NYC* Tech Day - New Cassandra Drivers in Depth
Michaël Figuière
(Alex Mironov, Booking.com) Kafka Summit SF 2018 Since its original introduction at Booking.com, Apache Kafka and overall concept of real-time data streaming have come a long way from being a complicated novelty to a common tool, used by a multitude of internal users ranging in their importance from the ad-hoc consumers to business-critical services powering up our property search engine. Over the course of this talk we’ll dive deep into how a relatively small team of SREs is successfully managing a multi-cluster, multi-tenant setup of Kafka and its surrounding ecosystem capable of transporting millions of messages per day. We’ll discuss challenges they faced along their way while building this platform and take a close look not only at application but also at architectural-level decisions they made to overcome them. Surely, we will also review what kind of tooling and automation team is using to stay sane during the day and sleep well during the night.
Data Streaming Ecosystem Management at Booking.com
Data Streaming Ecosystem Management at Booking.com
confluent
O'Reilly Software Architecture Conference 2018, New York (USA): Talk by Mario-Leander Reimer (@LeanderReimer, Principal Software Architect at QAware) Abstract: Big data processing, microservices, and cloud-native technology are a match made in computing heaven, enabling microservices to be used to build a flexible, scalable, and distributed system of loosely coupled data processing tasks, called data services. Mario-Leander Reimer explores key JEE technologies that can be used to build JEE-powered data services and walks you through implementing the individual data processing tasks of a simplified showcase application. You’ll then deploy and orchestrate the individual data services using OpenShift, illustrating the scalability of the overall processing pipeline. The context and content is taken from a real-world project for a major German car manufacturer, implementing a microservices-based processing pipeline that uses car-related event data (sensor data, traffic events, and other real-time data) for a traffic information management and route optimization system.
Dataservices: Processing Big Data the Microservice Way
Dataservices: Processing Big Data the Microservice Way
QAware GmbH
Recomendados
Big Data Services in Danaos Use Case
Big Data Seervices in Danaos Use Case
Big Data Seervices in Danaos Use Case
Big Data Value Association
SHAKAS TECHNOLOGIES
Decentralized access control with anonymous authentication of data stored in ...
Decentralized access control with anonymous authentication of data stored in ...
Vasanth Mca
HCL CDC Velachery 9382207007, 9443558751
IEEE paper 2014 abstract
IEEE paper 2014 abstract
Senthilvel S
Keynote talk at the International Conference on Supercoming 2009, at IBM Yorktown in New York. This is a major update of a talk first given in New Zealand last January. The abstract follows. The past decade has seen increasingly ambitious and successful methods for outsourcing computing. Approaches such as utility computing, on-demand computing, grid computing, software as a service, and cloud computing all seek to free computer applications from the limiting confines of a single computer. Software that thus runs "outside the box" can be more powerful (think Google, TeraGrid), dynamic (think Animoto, caBIG), and collaborative (think FaceBook, myExperiment). It can also be cheaper, due to economies of scale in hardware and software. The combination of new functionality and new economics inspires new applications, reduces barriers to entry for application providers, and in general disrupts the computing ecosystem. I discuss the new applications that outside-the-box computing enables, in both business and science, and the hardware and software architectures that make these new applications possible.
Computing Outside The Box June 2009
Computing Outside The Box June 2009
Ian Foster
상세 설명: https://event.openinfradays.kr/2018/session1/track_4_0
[OpenInfra Days Korea 2018] (Track 4) CloudEvents 소개 - 상호 운용 가능성을 극대화한 이벤트 데이...
[OpenInfra Days Korea 2018] (Track 4) CloudEvents 소개 - 상호 운용 가능성을 극대화한 이벤트 데이...
OpenStack Korea Community
NYC* Tech Day - New Cassandra Drivers in Depth
NYC* Tech Day - New Cassandra Drivers in Depth
Michaël Figuière
(Alex Mironov, Booking.com) Kafka Summit SF 2018 Since its original introduction at Booking.com, Apache Kafka and overall concept of real-time data streaming have come a long way from being a complicated novelty to a common tool, used by a multitude of internal users ranging in their importance from the ad-hoc consumers to business-critical services powering up our property search engine. Over the course of this talk we’ll dive deep into how a relatively small team of SREs is successfully managing a multi-cluster, multi-tenant setup of Kafka and its surrounding ecosystem capable of transporting millions of messages per day. We’ll discuss challenges they faced along their way while building this platform and take a close look not only at application but also at architectural-level decisions they made to overcome them. Surely, we will also review what kind of tooling and automation team is using to stay sane during the day and sleep well during the night.
Data Streaming Ecosystem Management at Booking.com
Data Streaming Ecosystem Management at Booking.com
confluent
O'Reilly Software Architecture Conference 2018, New York (USA): Talk by Mario-Leander Reimer (@LeanderReimer, Principal Software Architect at QAware) Abstract: Big data processing, microservices, and cloud-native technology are a match made in computing heaven, enabling microservices to be used to build a flexible, scalable, and distributed system of loosely coupled data processing tasks, called data services. Mario-Leander Reimer explores key JEE technologies that can be used to build JEE-powered data services and walks you through implementing the individual data processing tasks of a simplified showcase application. You’ll then deploy and orchestrate the individual data services using OpenShift, illustrating the scalability of the overall processing pipeline. The context and content is taken from a real-world project for a major German car manufacturer, implementing a microservices-based processing pipeline that uses car-related event data (sensor data, traffic events, and other real-time data) for a traffic information management and route optimization system.
Dataservices: Processing Big Data the Microservice Way
Dataservices: Processing Big Data the Microservice Way
QAware GmbH
ambari
My ambariexperience
My ambariexperience
wyukawa
https://www.meetup.com/ja-JP/Prometheus-London/events/232832512/?eventId=232832512
Prometheus london
Prometheus london
wyukawa
presto
Presto in my_use_case2
Presto in my_use_case2
wyukawa
hadoop source code reading #20
Upgrading from-hdp-21-to-hdp-24
Upgrading from-hdp-21-to-hdp-24
wyukawa
Hive sourcecodereading
Hive sourcecodereading
wyukawa
prometheus
Prometheus
Prometheus
wyukawa
presto meetup
Presto in my_use_case
Presto in my_use_case
wyukawa
promcon2016
Promcon2016
Promcon2016
wyukawa
prometheus
Prometheus casual talk1
Prometheus casual talk1
wyukawa
upgrade hadoop
Upgrading from-hdp-21-to-hdp-25
Upgrading from-hdp-21-to-hdp-25
wyukawa
presto
Presto conferencetokyo2019
Presto conferencetokyo2019
wyukawa
https://conferences.oreilly.com/strata/strata-sg/public/schedule/detail/62948
Strata2017 sg
Strata2017 sg
wyukawa
Azkaban
Azkaban-en
Azkaban-en
wyukawa
Azkaban
Azkaban
Azkaban
wyukawa
Osc mercurial-public
Osc mercurial-public
wyukawa
Dvcs study
Dvcs study
wyukawa
Hudson study-zen
Hudson study-zen
wyukawa
Shibuya.trac.8
Shibuya.trac.8
wyukawa
Tanabata.trac 第7回勉強会発表資料
Hudson tanabata.trac
Hudson tanabata.trac
wyukawa
Mais conteúdo relacionado
Destaque
ambari
My ambariexperience
My ambariexperience
wyukawa
https://www.meetup.com/ja-JP/Prometheus-London/events/232832512/?eventId=232832512
Prometheus london
Prometheus london
wyukawa
presto
Presto in my_use_case2
Presto in my_use_case2
wyukawa
hadoop source code reading #20
Upgrading from-hdp-21-to-hdp-24
Upgrading from-hdp-21-to-hdp-24
wyukawa
Hive sourcecodereading
Hive sourcecodereading
wyukawa
prometheus
Prometheus
Prometheus
wyukawa
presto meetup
Presto in my_use_case
Presto in my_use_case
wyukawa
promcon2016
Promcon2016
Promcon2016
wyukawa
prometheus
Prometheus casual talk1
Prometheus casual talk1
wyukawa
upgrade hadoop
Upgrading from-hdp-21-to-hdp-25
Upgrading from-hdp-21-to-hdp-25
wyukawa
Destaque
(10)
My ambariexperience
My ambariexperience
Prometheus london
Prometheus london
Presto in my_use_case2
Presto in my_use_case2
Upgrading from-hdp-21-to-hdp-24
Upgrading from-hdp-21-to-hdp-24
Hive sourcecodereading
Hive sourcecodereading
Prometheus
Prometheus
Presto in my_use_case
Presto in my_use_case
Promcon2016
Promcon2016
Prometheus casual talk1
Prometheus casual talk1
Upgrading from-hdp-21-to-hdp-25
Upgrading from-hdp-21-to-hdp-25
Mais de wyukawa
presto
Presto conferencetokyo2019
Presto conferencetokyo2019
wyukawa
https://conferences.oreilly.com/strata/strata-sg/public/schedule/detail/62948
Strata2017 sg
Strata2017 sg
wyukawa
Azkaban
Azkaban-en
Azkaban-en
wyukawa
Azkaban
Azkaban
Azkaban
wyukawa
Osc mercurial-public
Osc mercurial-public
wyukawa
Dvcs study
Dvcs study
wyukawa
Hudson study-zen
Hudson study-zen
wyukawa
Shibuya.trac.8
Shibuya.trac.8
wyukawa
Tanabata.trac 第7回勉強会発表資料
Hudson tanabata.trac
Hudson tanabata.trac
wyukawa
Mais de wyukawa
(9)
Presto conferencetokyo2019
Presto conferencetokyo2019
Strata2017 sg
Strata2017 sg
Azkaban-en
Azkaban-en
Azkaban
Azkaban
Osc mercurial-public
Osc mercurial-public
Dvcs study
Dvcs study
Hudson study-zen
Hudson study-zen
Shibuya.trac.8
Shibuya.trac.8
Hudson tanabata.trac
Hudson tanabata.trac
Hdfs write
1.
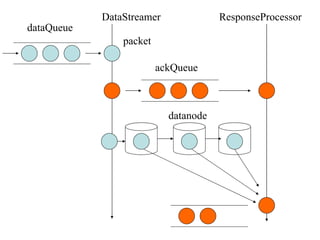
dataQueue ackQueue DataStreamer
ResponseProcessor datanode packet
Baixar agora