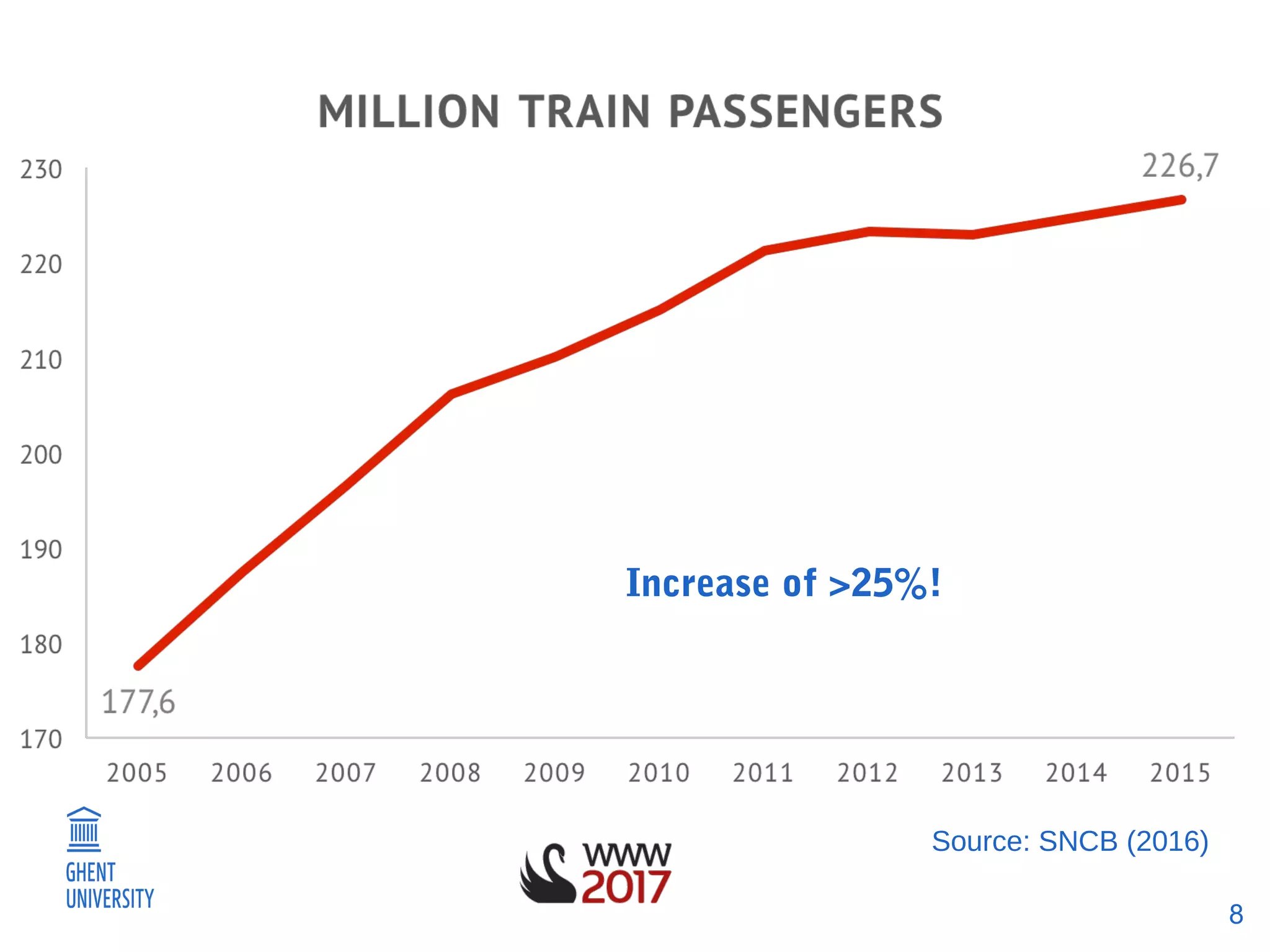
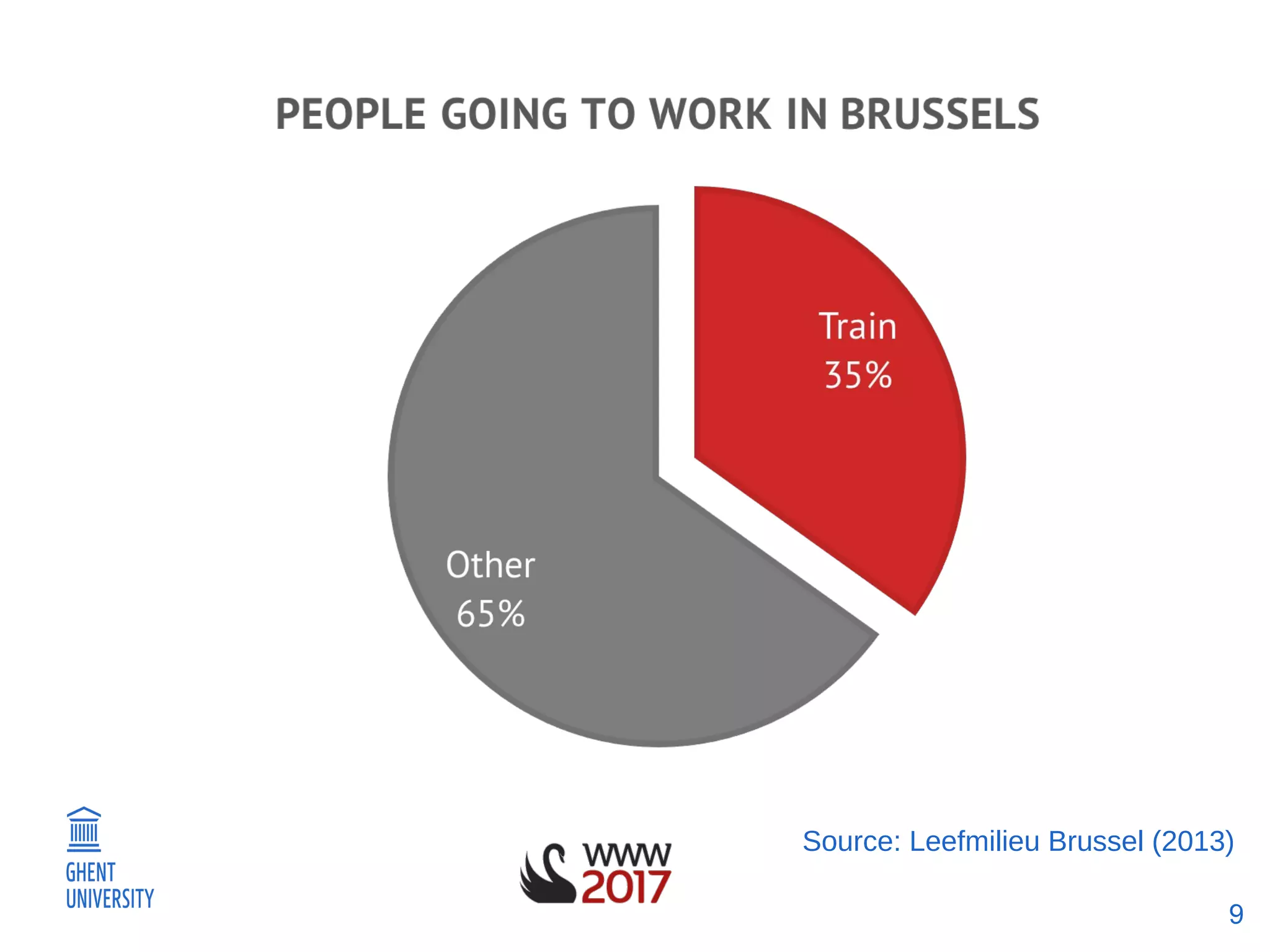
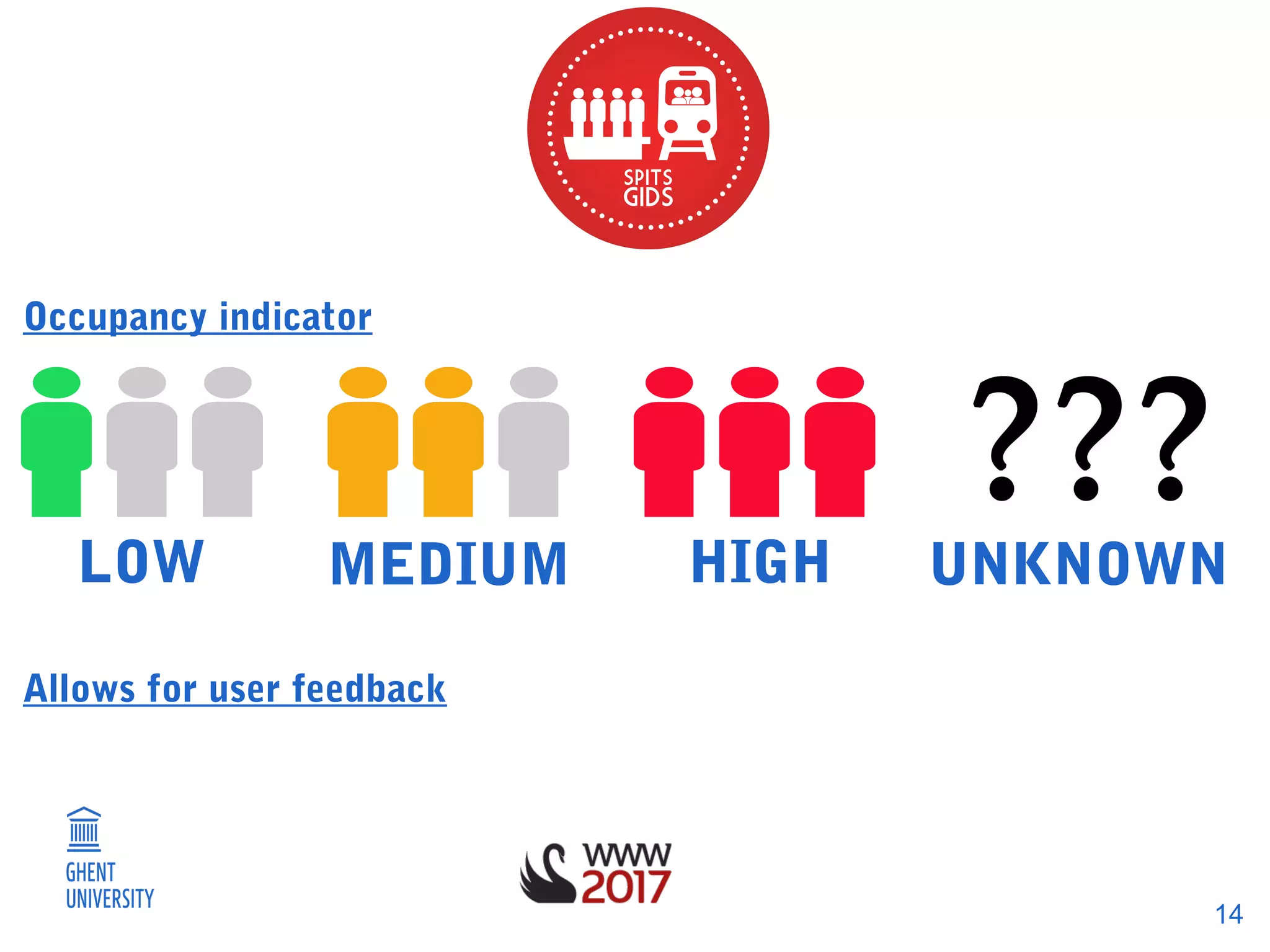
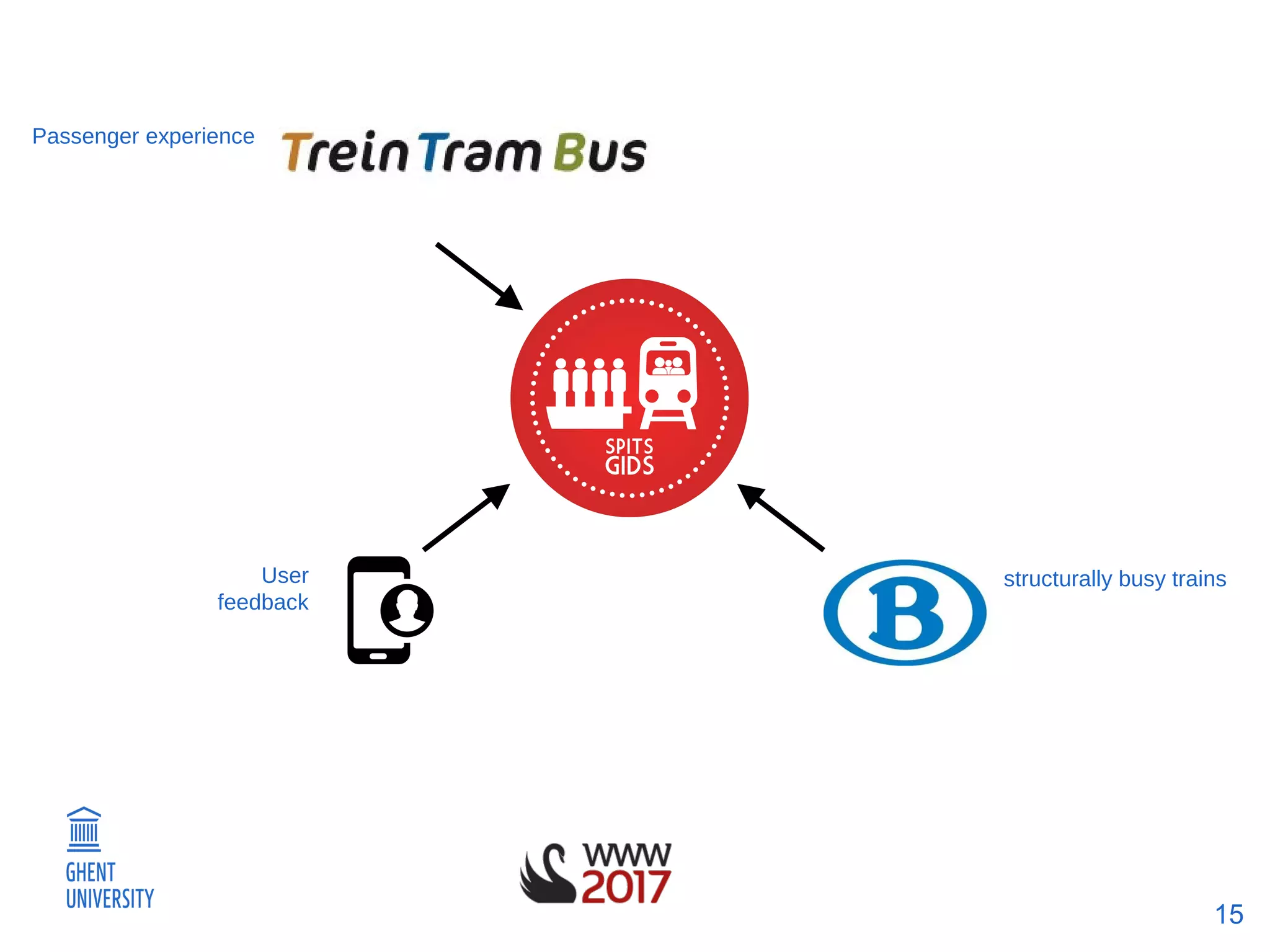
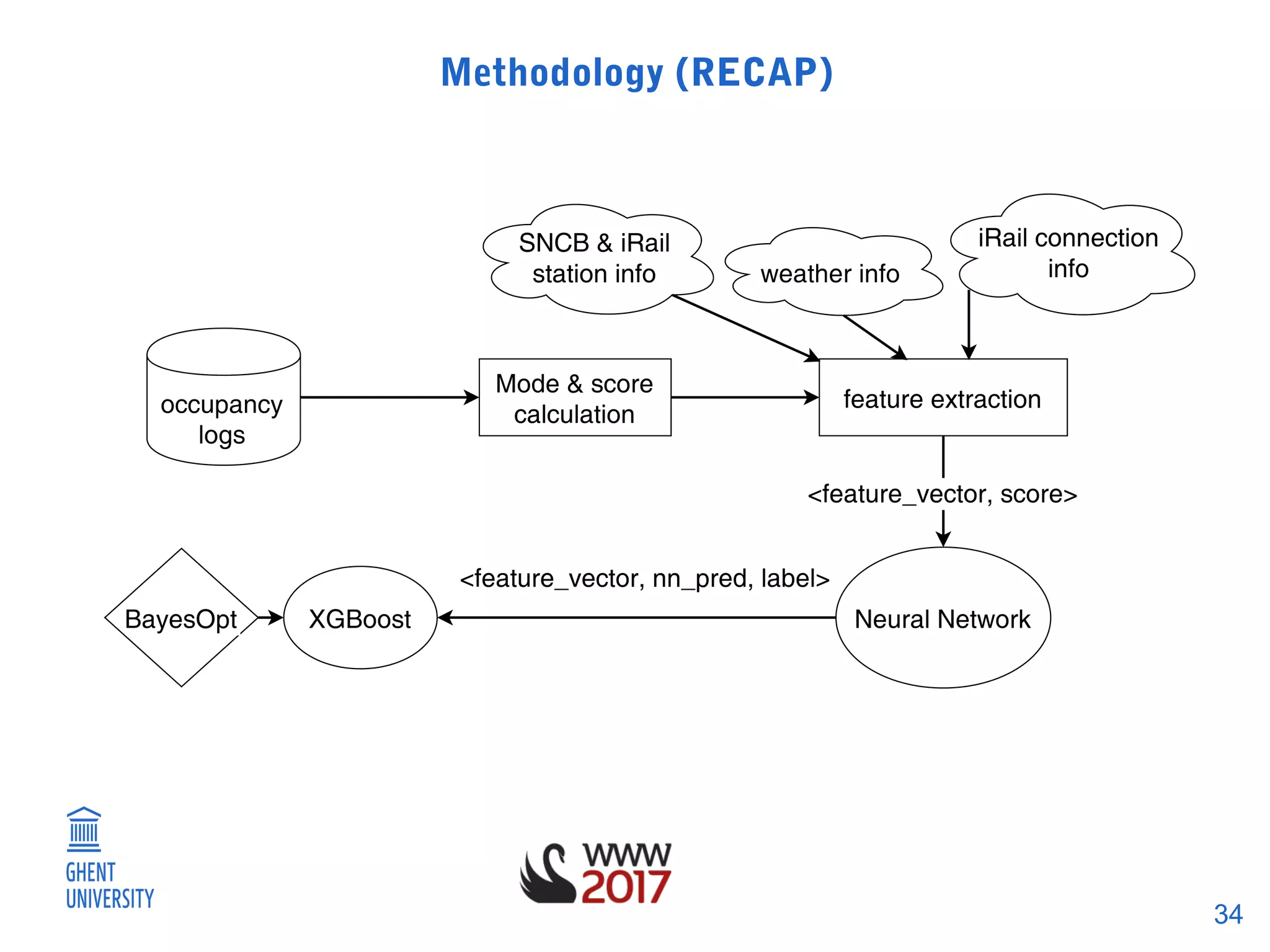
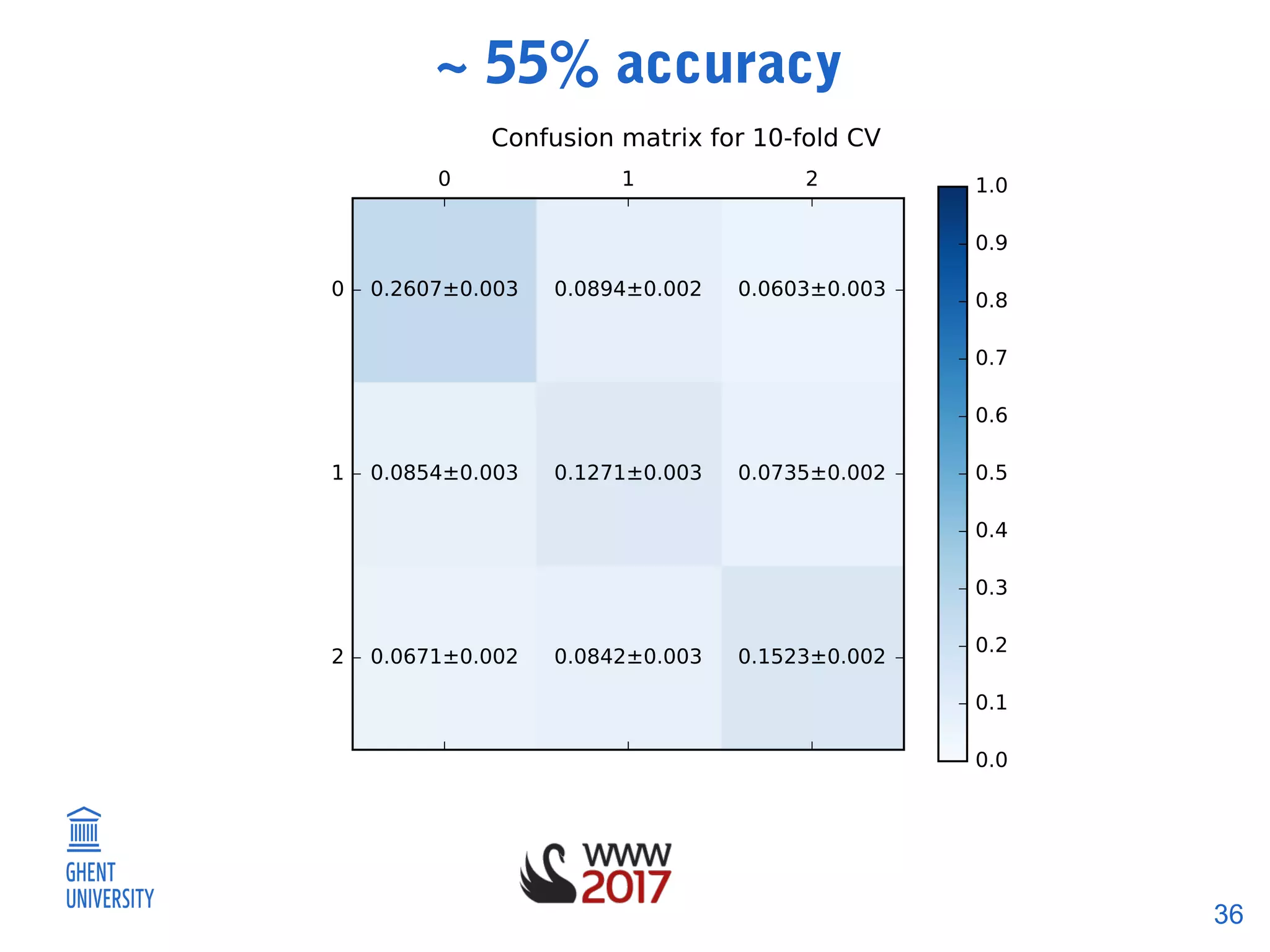
The document discusses a methodology for predicting train occupancies using user feedback and external data sources, focusing on enhancing passenger experience by notifying about train occupancy levels. It details the collection of data between August and December 2016, resulting in a model achieving approximately 55% accuracy in predicting occupancy. Future work includes gathering more data and collaborating with the train authority to improve model accuracy and incorporate external event data.
































![[ESWC2017 - PhD Symposium] Enhancing white-box machine learning processes by ...](https://cdn.slidesharecdn.com/ss_thumbnails/eswcpresentation-170603121332-thumbnail.jpg?width=640&height=640&fit=bounds)
![[SECSI 2018] CONAMO - Continuous Athlete Monitoring through a Real-Time Senso...](https://cdn.slidesharecdn.com/ss_thumbnails/presentationsecsigvdw-180416063819-thumbnail.jpg?width=640&height=640&fit=bounds)
![[PAKDD - BDM17] GENESIM: GENetic Extraction of a Single, Interpretable Model](https://cdn.slidesharecdn.com/ss_thumbnails/genesim-170524022354-thumbnail.jpg?width=640&height=640&fit=bounds)







































