Baixado 12 vezes









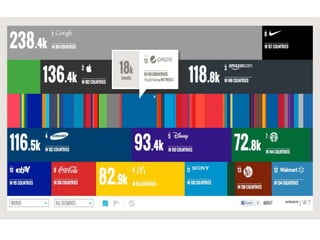
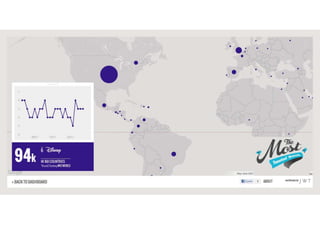









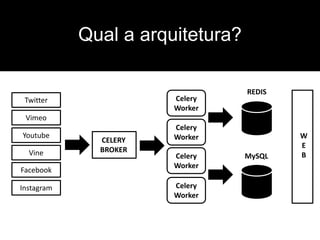





O documento descreve experimentos de análise de dados em redes sociais para determinar notícias importantes, medir opiniões de torcedores em tempo real e verificar o valor de marcas com base no engajamento online. Os experimentos coletam dados do Twitter, Facebook e outras plataformas usando APIs para processar grandes volumes de dados.



























